Introducing Actions: Add custom business logic to Hasura
Actions make it easy for you to bring your new or existing business logic to Hasura. In this post, I'll introduce to you what actions are and why they're designed the way they are!
Why Actions?
With actions you can add any kind of business logic to your GraphQL API easily. Hasura handles CRUD, your actions handle everything else!
Actions works really well with Hasura so you can choose which bits you want Hasura to take care of, and which bits you want to take care of. It’s a spectrum that you can slide along back and forth as your application evolves.
Just like the way Hasura works with your database, our aim with Actions is to help our users land up with best practices from the get go!
Even though the business logic is written by you, Hasura still handles all the GraphQL bits. Blazing fast as usual. Hasura ensures that your business logic automatically falls into the pit of best possible performance.
Hasura actions are a great fit with serverless because each action can be backed by an independent function
How do Actions work?
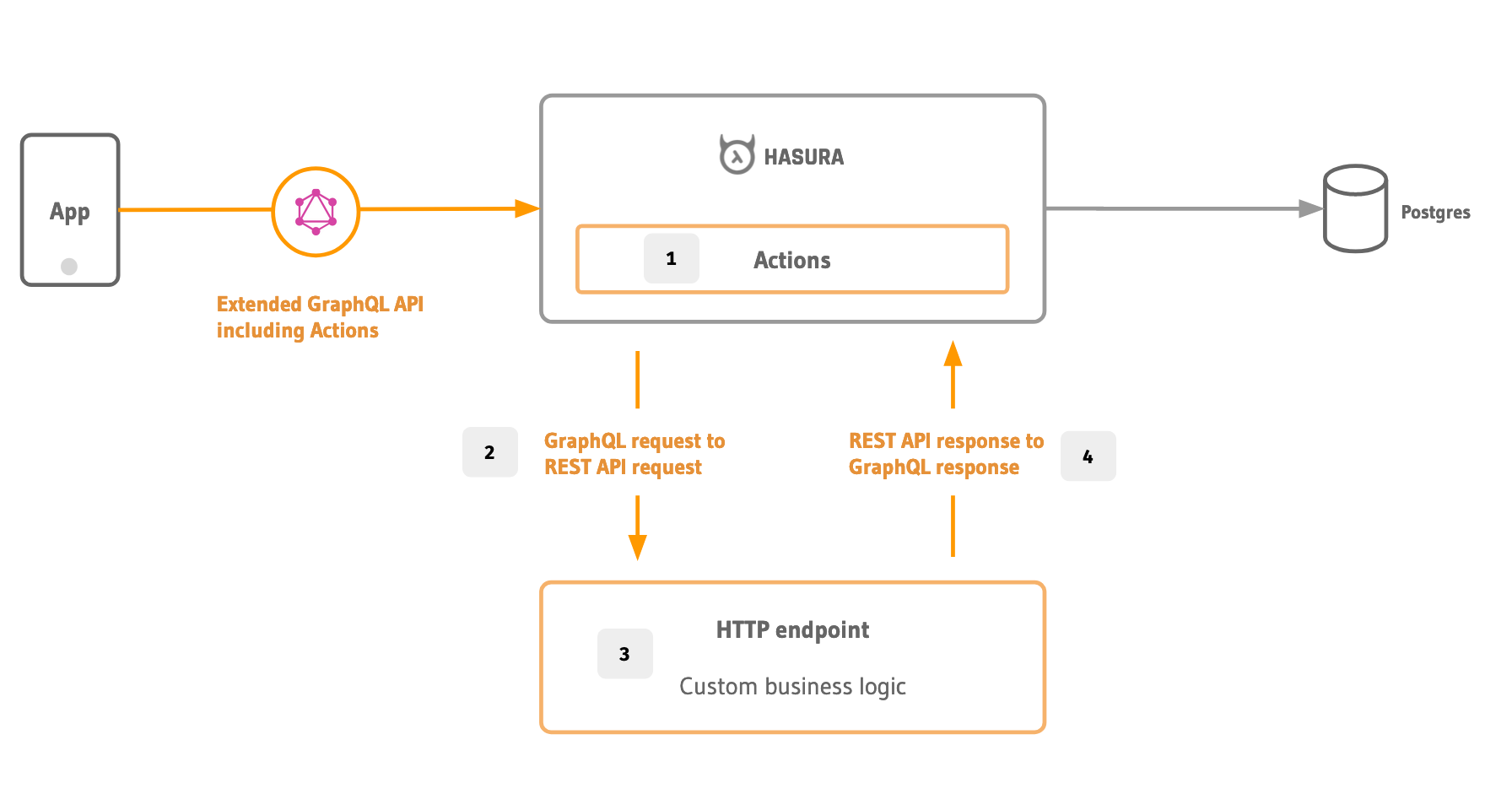
Hasura Actions: The ease of writing REST, and the joy of consuming GraphQL
Step 1: You specify the query or mutation GraphQL contract at Hasura
Step 2: Hasura validates and delegates the incoming GraphQL request to your REST API (aka Action handler)
Step 3: Your REST API Does Stuff™ and returns minimal output
Step 4: Hasura enriches the output with the rest of the data graph according to what the users want in the final GraphQL response. Because Hasura joins the data together, you get all of the benefits of Hasura’s blazing fast GraphQL execution.
Try out Actions for yourself, setup a GraphQL project using Hasura Cloud and read the Actions docs to get started.
To see all the different things that you can do with actions, check out this youtube playlist we put together in April in a series titled #ActionPackedApril.
An example of using Hasura actions with NextJS API routes!
Scalable architecture
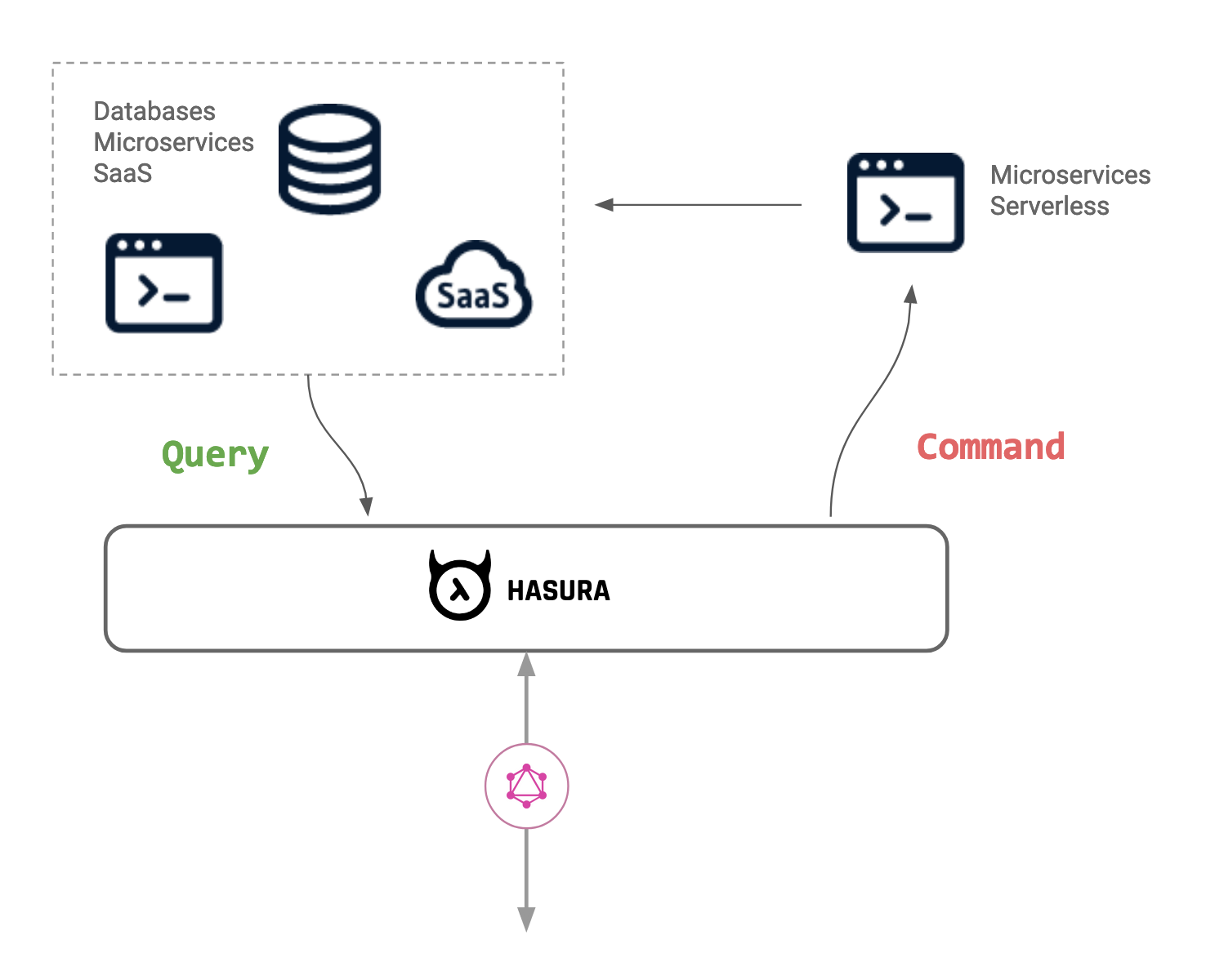
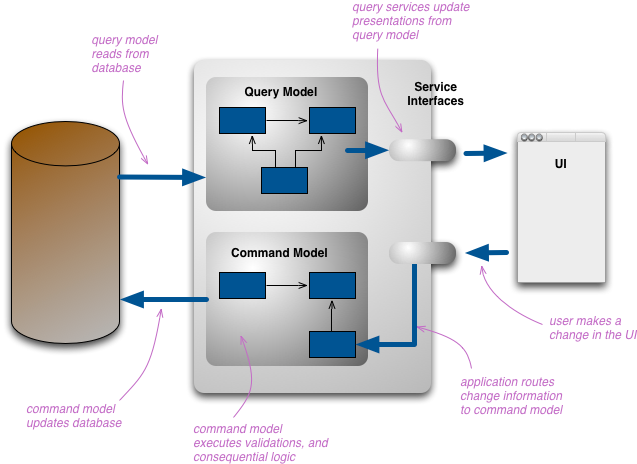
Most APIs are composed of a mix of CRUD and non-CRUD APIs. A scalable pattern for non-CRUD designs is a pattern based on a “command & query” architecture.
When we think about CRUD, we think about models and we think about reading or writing to them with a few API endpoints (or GraphQL fields).
When we think about a command and query design, you think about running a “command” which is an action or a workflow that makes sense for a user in your domain. The handler for this command then runs logic to process the request and then proceeds to update the views of the models. The final response to the request that the user made, is then a “query” of those updated models.
A command & query architecture for GraphQL with Hasura
Why is this architecture beneficial?
It allows the authors of each command to deal primarily with the business logic associated with the “domain action”. Models that have CRUD might get very complicated and can start encapsulating logic that is not relevant to the model at all. For example, insert on X should send an email.
Usually, setting up the plumbing required to set up a CQS/CQRS based architecture with microservices takes a little bit of work. With Hasura, that architecture is available out of the box and it is tremendously easy to distribute the work across a team!
Furthermore, from a security point of view, it becomes easy to think about access control.
At a domain entity level: Who all have the ability to access this model or action
At a user level: What models and actions does this user have access to
Hasura's security / permissions system is API driven, so you can easily extract both pieces of information above with just an API call!
No vendor lock-in
We designed Hasura to work on new or existing databases. As you use Hasura, the data models that you end up with, are very naturally the data models that you would have put in place as a good database user. This means that if you want to “eject” out of Hasura tomorrow, your data is still yours, ready to be used by whatever application you want.
With Actions, we extend that philosophy to business logic. GraphQL today is a still a young and maturing ecosystem. GraphQL frameworks are either vendor backed or made by independent developers without a large contributor community. Furthermore, most of the GraphQL work is restricted to the JavaScript ecosystem.
However, REST does not suffer from these problems. The tooling for building, maintaining and operating REST APIs is mature & quite phenomenal. The runtime environments for REST have also evolved rapidly over the last few years. Serverless runtimes are getting increasingly sophisticated and can run functions which are presented as lightweight REST endpoints. GraphQL servers, however, are not suited to serverless deployments. GraphQL servers in production environments need to maintain a fair bit of state to efficiently validate, cache, rate-limit incoming requests. GraphQL subscriptions, are quite complex to maintain and near impossible in serverless environments.
With Hasura, our aim has been to help users continue using their favorite technologies and tools (just like they own their own data and database) to add business logic in a way that would largely be the same even if they weren’t using Hasura!
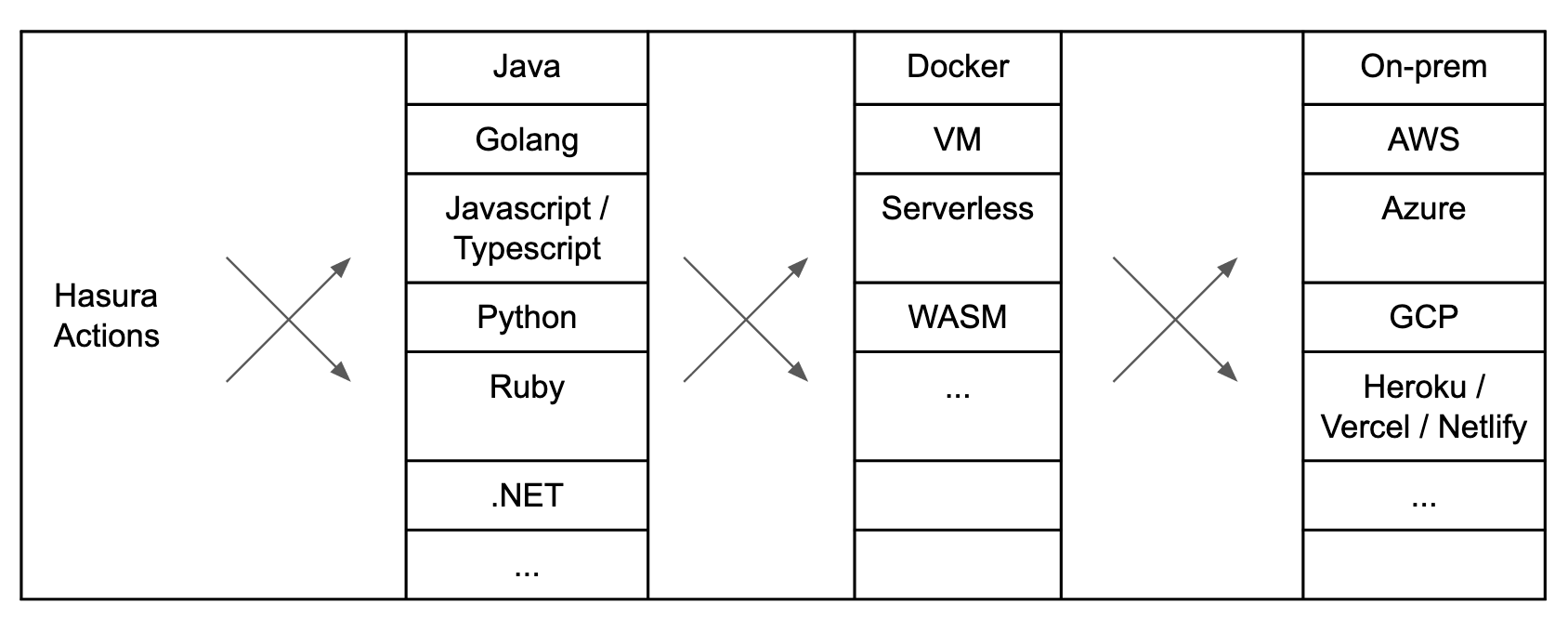
With Hasura actions, your business logic can be any combination of your favourite technologies:
Bring your favourite language x framework x runtime x deployment for Hasura Actions
If you want to move away from Hasura then you can completely opt-out and build your own GraphQL server, or even migrate away from GraphQL entirely without having to redo all the work you’ve done in your domain! Your data, your data models, your business logic will all carry forward.
Performance best practices
Hasura helps you fall into the pit of performance success as you use actions. :)
For example: The best practice for a GraphQL mutation is to delegate the input information to a function that can process it and then give read-after-write semantics, have the GraphQL layer generate the right response for the mutation (depending on what the user requested).
Hasura actions do exactly that, but in a way friendly to a microservices / serverless architecture. Your REST API performs business logic and returns just the right data or the right references to the data. Hasura joins those references with the rest of the data graph efficiently and generates the GraphQL response that your client deserves.
If you’re building your own GraphQL server, you have to worry about N+1 query problems, validating//caching query plans and other performance optimisations that Hasura handles for you. These problems become especially harder to address in a serverless environment. However, with Hasura’s Actions architecture, serverless REST endpoints are a perfect fit!
As you build your business logic and your REST API handlers, you need not worry about any of these. The design of Hasura actions makes it very easy to leverage and reuse authorization rules that are specified at the Hasura level too!
For example, you can specify Hasura authorization rules that correspond to end-users. From your Actions endpoint, you can invoke the Hasura GraphQL APIs as your end-user role. This makes it easy to write “backend” code that executes with the same privileges as “frontend” code, but with additional steps or validations that were not possible to run on the frontend. Your “model” level security stays in one place.
Pairs well with Serverless 🍷
Hasura Actions are backed by REST APIs, These APIs could be served by a service or a serverless function or anything else that can serve a REST API!
Serverless is an especially great fit both from an architecture / mental model point of view, and also from a performance & scalability point of view.
Each Hasura action can be backed by a serverless function (exposing a REST endpoint). This serverless function can be developed and deployed independently.
This is a neat separation of concerns, because Hasura exposes a unified coherent GraphQL API to the consumer, regardless of how the serverless functions are built and run.
Hasura also exposes a set of GraphQL endpoints on the database which can be used by the business logic to read and write data to the database. This is great for serverless, because connecting to the database directly is challenging.
The business logic you write now also falls into the pit of success for both performance and scaling, because a) GraphQL/database performance is guaranteed by Hasura b) scalability is guaranteed by the cloud-vendor running the serverless functions. 🔥