GraphQL maturity model: A practical guide for your GraphQL adoption journey
TL;DR
When done right, most GraphQL journeys result in a single graph (subgraph) evolving into a graph of graphs (supergraph) via GraphQL federation. It’s not a necessary evolution if you have one or a limited number of domain databases. And when it does happen, it’s typically a cyclical journey and there’s almost always a new subgraph to be built.
The learnings from building a supergraph can be invested back into building a high-quality subgraph, and the ecosystem of subgraph and supergraph tooling is already evolving into the next stage of its journey based on these insights.
Introduction
All models are wrong, but some are useful. This model aims to be useful to a GraphQL practitioner or to anyone curious about GraphQL (GraphQurious?), by enabling them to anticipate the challenges of later/upcoming stages, and use these insights from others’ experience to fine-tune their current efforts and be better prepared.
Glossary
Subgraph: A GraphQL API that’s one of the components in a larger graph. In more practical terms, it’s the GraphQL equivalent of a microservice – typically this is a GraphQL API built and operated by a single team that owns a domain.
GraphQL federation: a term introduced by Apollo to describe the process of combining multiple subgraphs into a unified GraphQL API/schema (with relationships between subgraphs).
Federated GraphQL API: Output of the GraphQL federation process, typically used in the context of using Apollo tooling. Other GraphQL projects also sometimes use this term.
Supergraph: A generic term used to describe a federated GraphQL API. The graph in supergraph refers to the combination of API domains rather than just the API itself.
Caveats
Iterations and nonlinearity: Adoption journeys are not as linear. Most organizations will go through multiple iterations of building GraphQL APIs/layers. So it’s possible, for example, to go from stage 4 to stage 1 as you pick up the task of building a new subgraph.
Org structure and multiple stages: More than 1 independent or dependent GraphQL journey could play out in an organization, sometimes on the same team. So it’s possible to belong to different stages at the same time.
Measure of complexity, not competence: It’s quite normal to not need anything more than a single simple GraphQL API on a domain database and stay in stage 1 for years. A position in the maturity model is more indicative of the data access patterns that need to be supported and less about the ability of teams to support more elaborate patterns.
We are now ready to dive head-first into this framework. Our example is an e-commerce application:
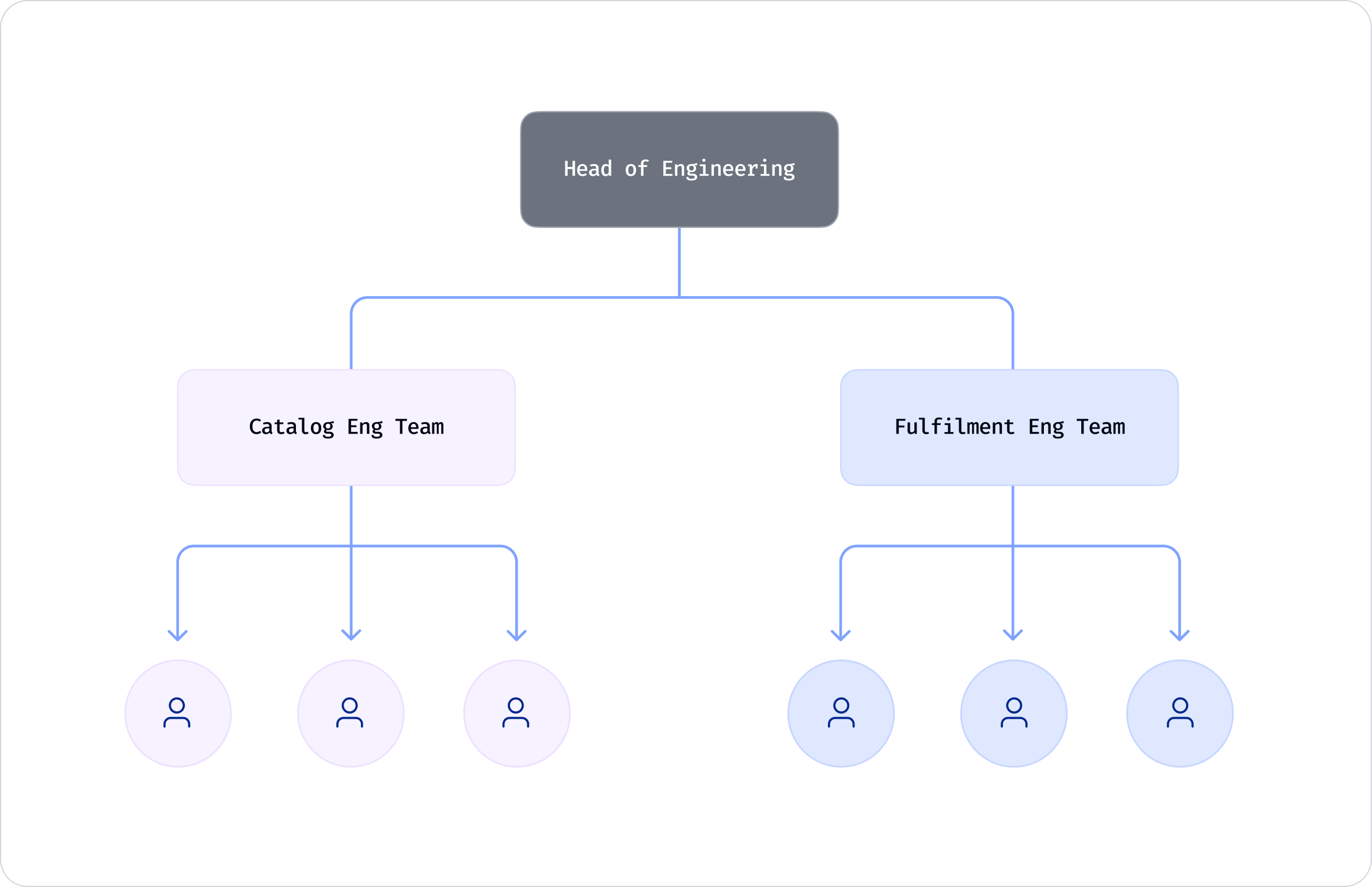
1.Teams/people: The application is being built by a hypothetical engineering function with multiple domain teams.
2.Application: The following wireframes for this app will help us navigate through the stages of this framework,
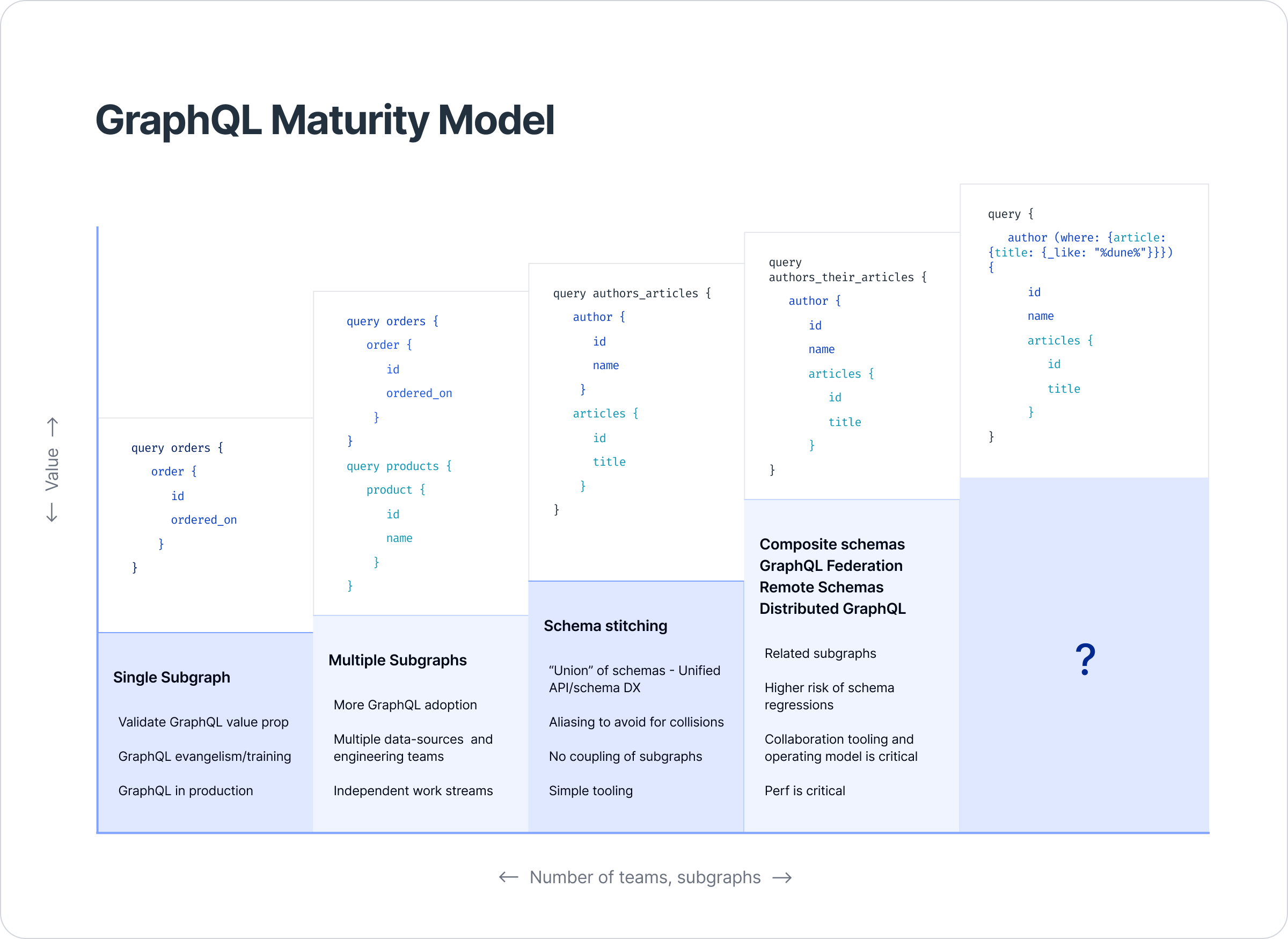
The GraphQL maturity model plots the evolution of subgraphs and their interplay along two axes: the value of the GraphQL solution and the number of teams or subgraphs involved in the solution.
The model plots the natural evolution of a graph in an organization with multiple domains. It also calls out the key focus areas in each of the stages in the model as they change from a single team’s concern to potentially affecting the entire engineering organization. At each stage, sample queries demonstrate the art of possible enabled by the API. This reflects the growing complexity and maturity of the federated GraphQL API itself.
Stage 0: GraphQL curiosity
Welcome! If you’re curious about GraphQL and its ability to solve engineering challenges in the world of APIs, you’re in the right place.
GraphQL emerged from very real-world use cases at Facebook. There are significant parallels between Facebook in 2014 and enterprise organizations – a large number of engineering teams, lots of data, and the need for seamless inter-team collaboration.
Building is learning – as you explore different patterns of using GraphQL, it’s highly recommended that you experiment with different approaches and stages to get a better understanding of how GraphQL could work for you and your team.
Stage 1: Building a subgraph
Building and deploying a production-ready GraphQL API is a crucial first step.
Most GraphQL literature emphasizes the later stages of this maturity curve – about how to value compounds when you “join” more than two subgraphs – and that’s mostly true. But this stage is the rate-limiting factor – if you can’t build production-grade high-quality subgraphs quickly enough, you won’t have that shiny unified API layer anytime soon.
Speed is of the essence here and the associated trade-offs you make in this stage might make the difference between having a practical API layer in production vs. a paper tiger that’s more design than code! It’s harder to build production-grade subgraphs than to join two or more subgraphs – a problem that can be solved with the right tooling.
At the end of this stage:
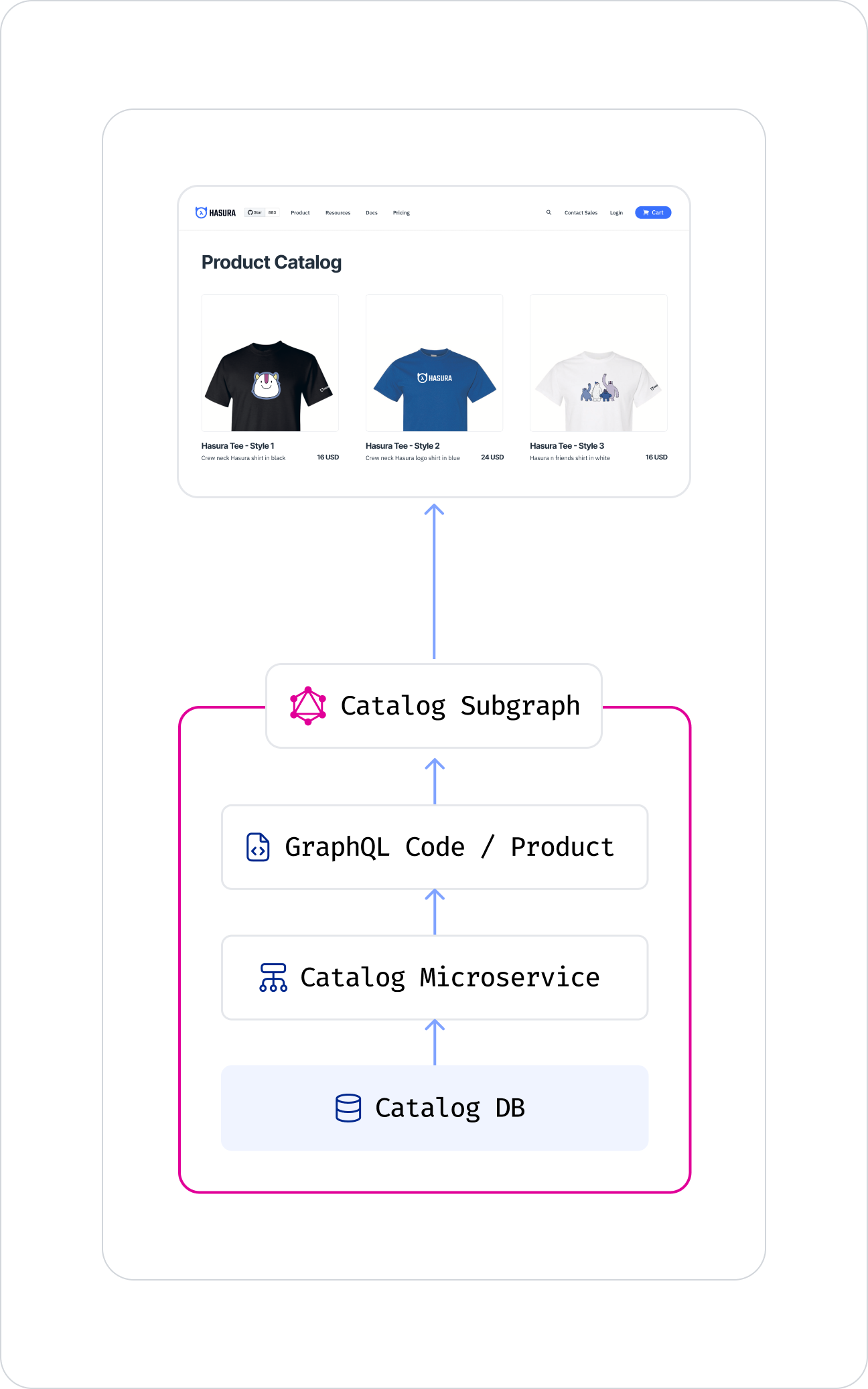
Our architecture looks like this:
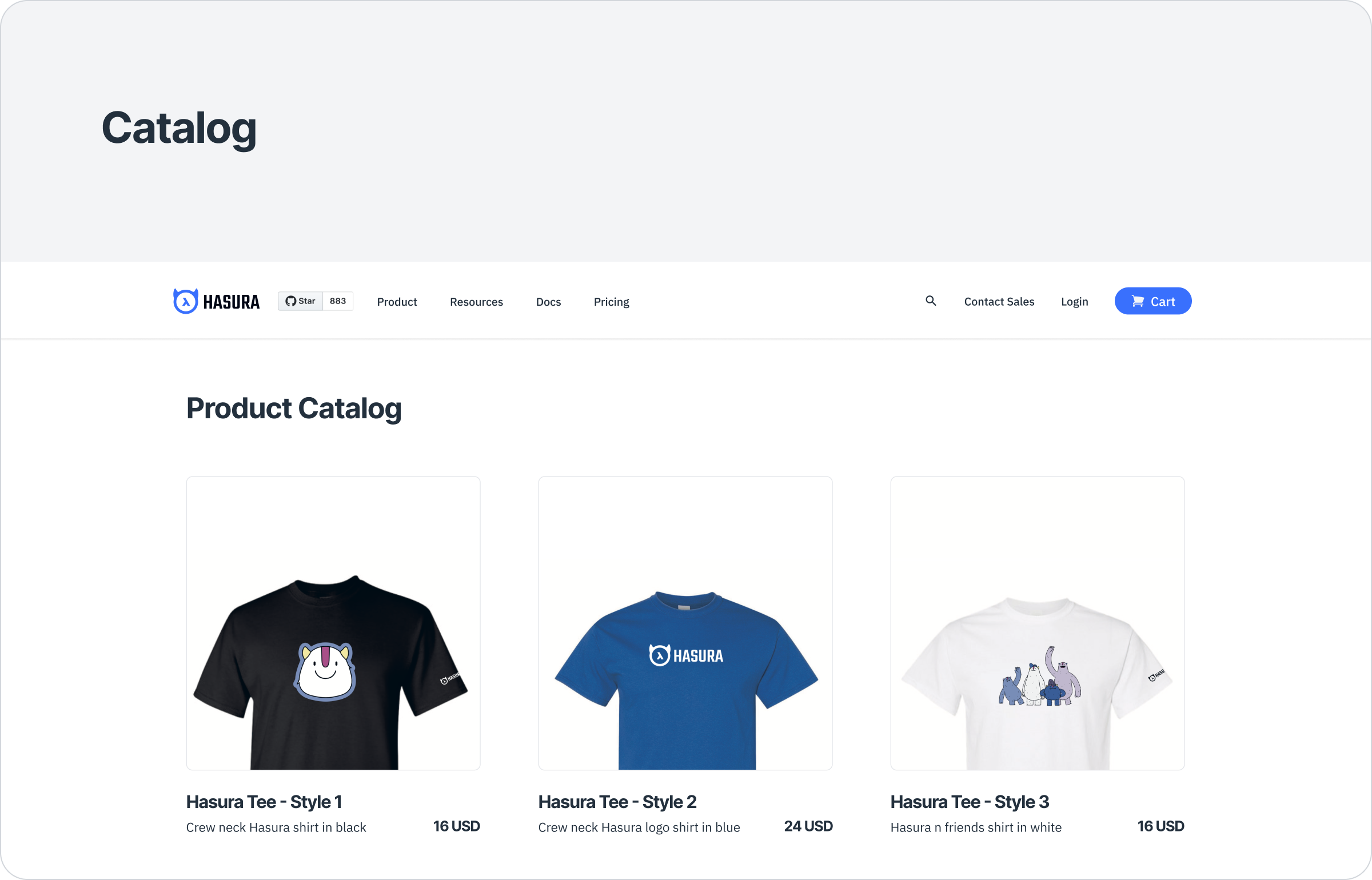
Catalog Subgraph
Note: This diagram is reductive by design. Your first domain GraphQL API can also be a part of an overarching program in your organization like technology modernization
The Catalog subgraph serves the following schema:
catalog_products {
id
name
description
}
Implementation patterns
The GraphQL ecosystem has evolved to produce a variety of subgraph authoring tools and approaches. Key among these are schema-first, code-first, and domain-driven approaches. As your graph matures, you’ll likely use more than one approach depending on the specific use-case. We have written extensively about subgraph tooling here.
Lessons from building a supergraph can be applied to how subgraphs should be built. Revisit this section after the end of this post and see if that changes your opinion of what subgraph quality really means.
GraphQL API management tools
Depending on deadlines and how experimental your efforts so far have been, you might want to deploy your subgraph in production for client applications to start consuming this wonderful API. If this is your first GraphQL API, you’ll need to factor in some non-functional concerns like observability, performance, and security. Some subgraph tools offer such capabilities out of the box.
In the future, if your graph evolves to contain more than one subgraph, you may have to revisit your architecture to see if these concerns are better off being addressed in a centralized way.
💡Tips
If this is your first time with GraphQL, you’d likely start with a proof-of-concept, and, if you’re convinced of GraphQL’s value, you’ll need to evangelize GraphQL within your organization and help your client applications or other backend services consume your GraphQL API. Benchmarking your progress vis-a-vis traditional API development processes will hold you in good standing.
It may help to find a way to expose your GraphQL API in other formats like plain old REST, gRPC, etc. All teams in your organization may not be ready to move to a new specification. GraphQL can be your tool to provide a self-serve API platform but the output need not always be a GraphQL API. With its type system, GraphQL lends itself to be translated into other formats.
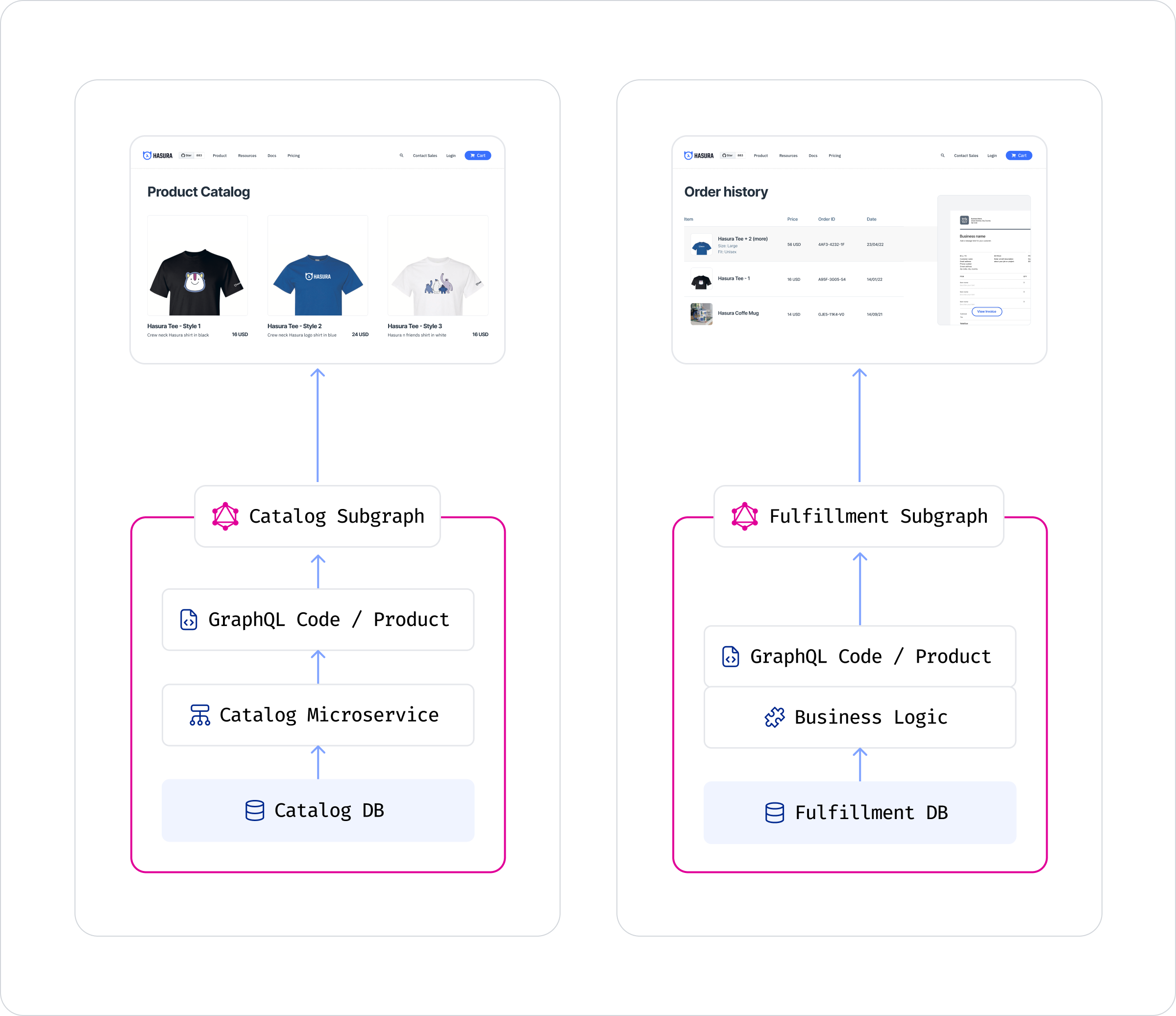
At the end of stage 1, you’d have validated your choice to introduce GraphQL into your stack and your implementation choices. Now, inspired by the success of this effort, your own team or another one could choose to build another subgraph (this can also be via another data source in the domain from the first example). You can choose to reuse the same tooling from stage 1 or go in a different direction to continue learning or to use the best tools for this new data source.
The two subgraphs are not related yet. They represent independent work streams that are not affected by each other.
Note: the difference in GraphQL subgraph design reflects the diversity of implementation patterns in the GraphQL ecosystem.
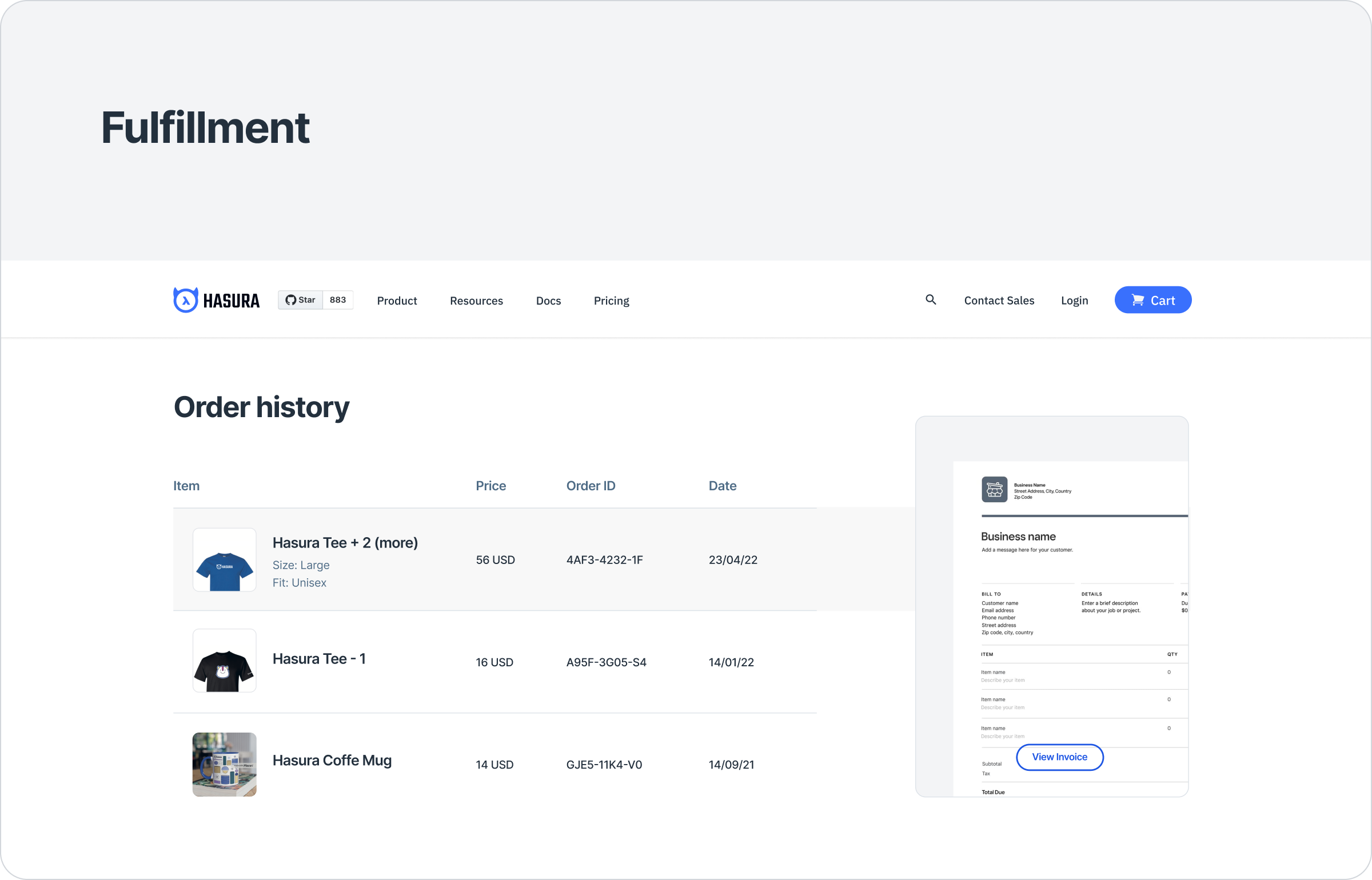
The new fulfillment subgraph serves the following schema:
Order{
id
value
Products: [Product]
}
Product {
id
qty
}
💡Tip
Before beginning this stage, check if you need to reevaluate the tooling based on your experience in stage 1. A big benefit of GraphQL is ecosystem interoperability is that you can use the right tooling for the use case at hand, as long as you build a GraphQL-spec compatible API.
Stage 3: Schema stitching
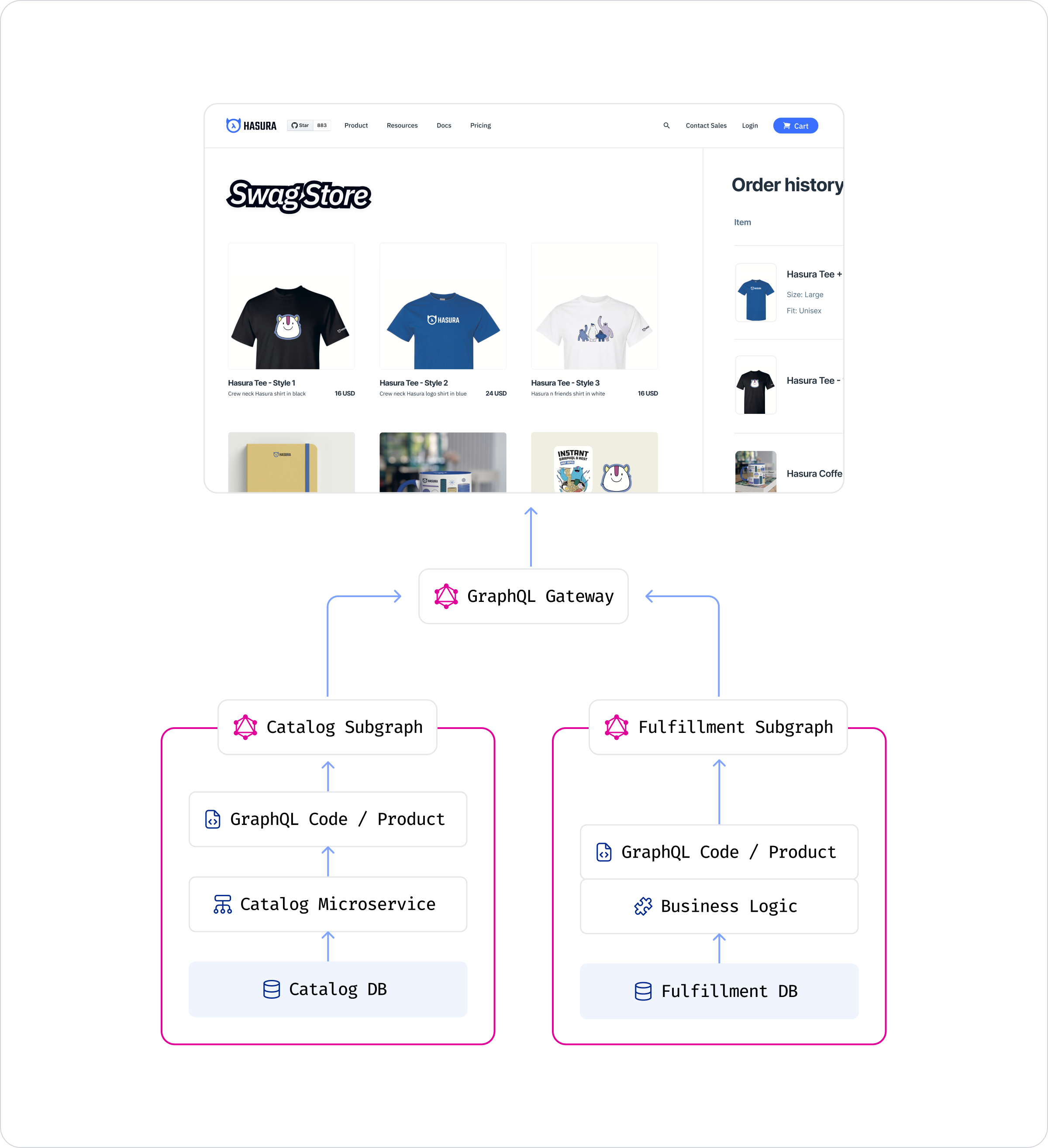
We have reached the aforementioned point of necessary collaboration. It’s the first stage where the sub in subgraphs makes sense – each of the domain graphs from the previous two stages become a part of a unified schema.
It’s natural to want to query the two independent subgraphs in the same query/request and present a unified schema to API consumers. For the consumer application or service, it’s objectively simpler to do so instead of making two different requests. The developer experience of working with one unified schema is also far superior.
Schema stitching offers a way for completely independent subgraphs to be “unified.” This “union” of types is typically done using some kind of a gateway. In our e-commerce example, schema stitching allows you to query the entirety of the following schema in one request:
catalog_products {
id
name
description
}
Order{
id
value
Products: [Product]
}
Product {
id
qty
}
Schema stitching as a concept and product capability has evolved into more than just a union of types since it was first introduced. You can build a custom tool or script to do this yourself, or use a third-party GraphQL gateway tool to route requests to the right subgraph. Some of these products allow you to merge (conflicting) types across subgraphs by allowing you to define the logic to do so.
Schema stitching is the first step of the next stage as well. Choosing when to move to the next step is best captured by this comment on Reddit:
“Most of the advantages of GraphQL federation occur when there are clear administrative boundaries between the data sources (Conway's law). That doesn't happen until larger team sizes, so IMO GraphQL federation seemed like unnecessary complexity at this stage.”
💡Tip
Schema stitching solves the problem of a unified GraphQL schema fairly elegantly without a lot of effort. Depending on your choice of tools, you may have to either use some form or namespacing-based aliasing or provide conflict resolution rules to merge types.
Stage 4: GraphQL composition or federation
Federation. Remote schemas. Distributed schemas. These are some of the names given to this stage by various tools in the GraphQL ecosystem. The defining trait of this stage is that types across subgraphs can have hierarchical relationships to each other.
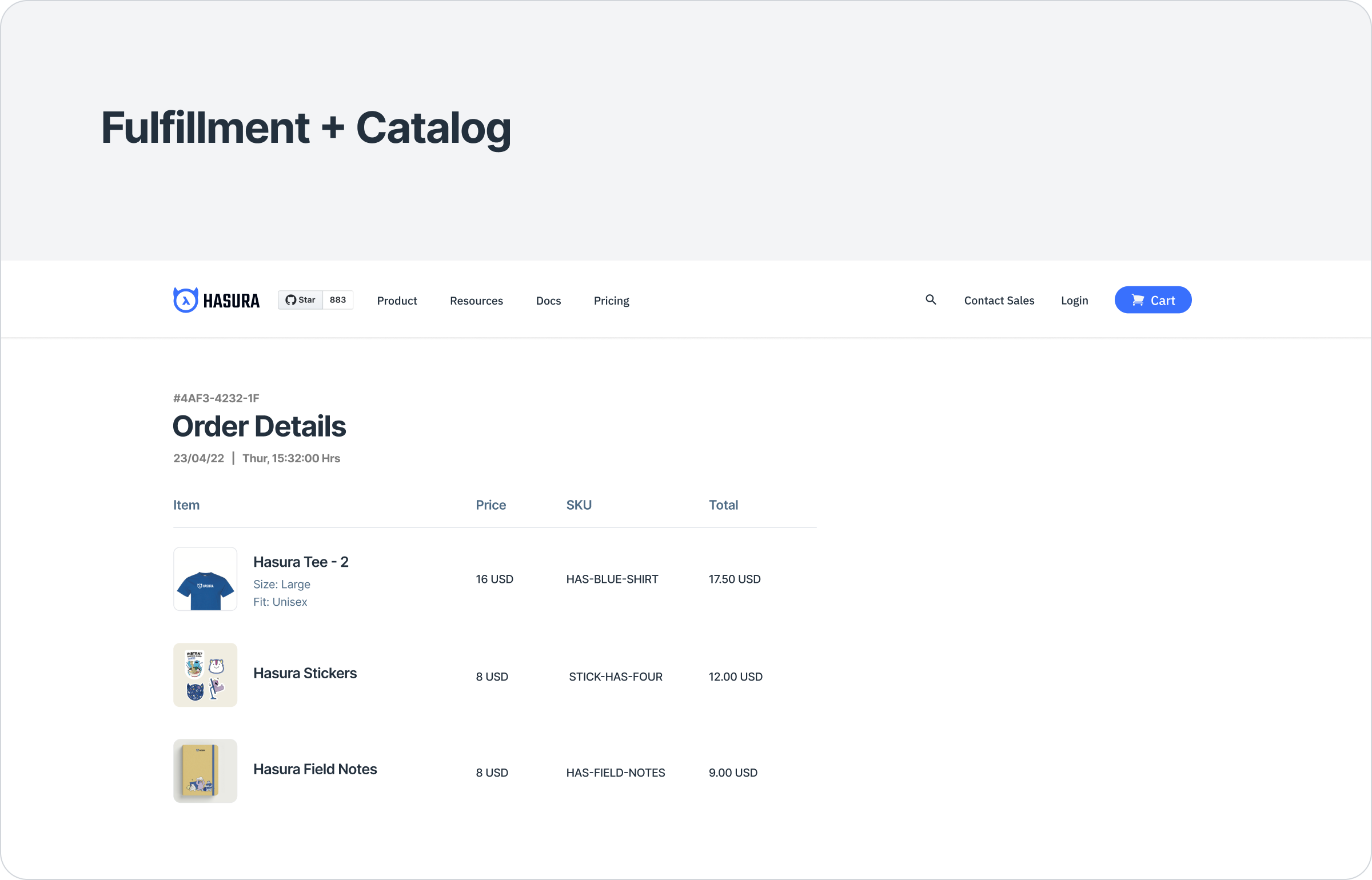
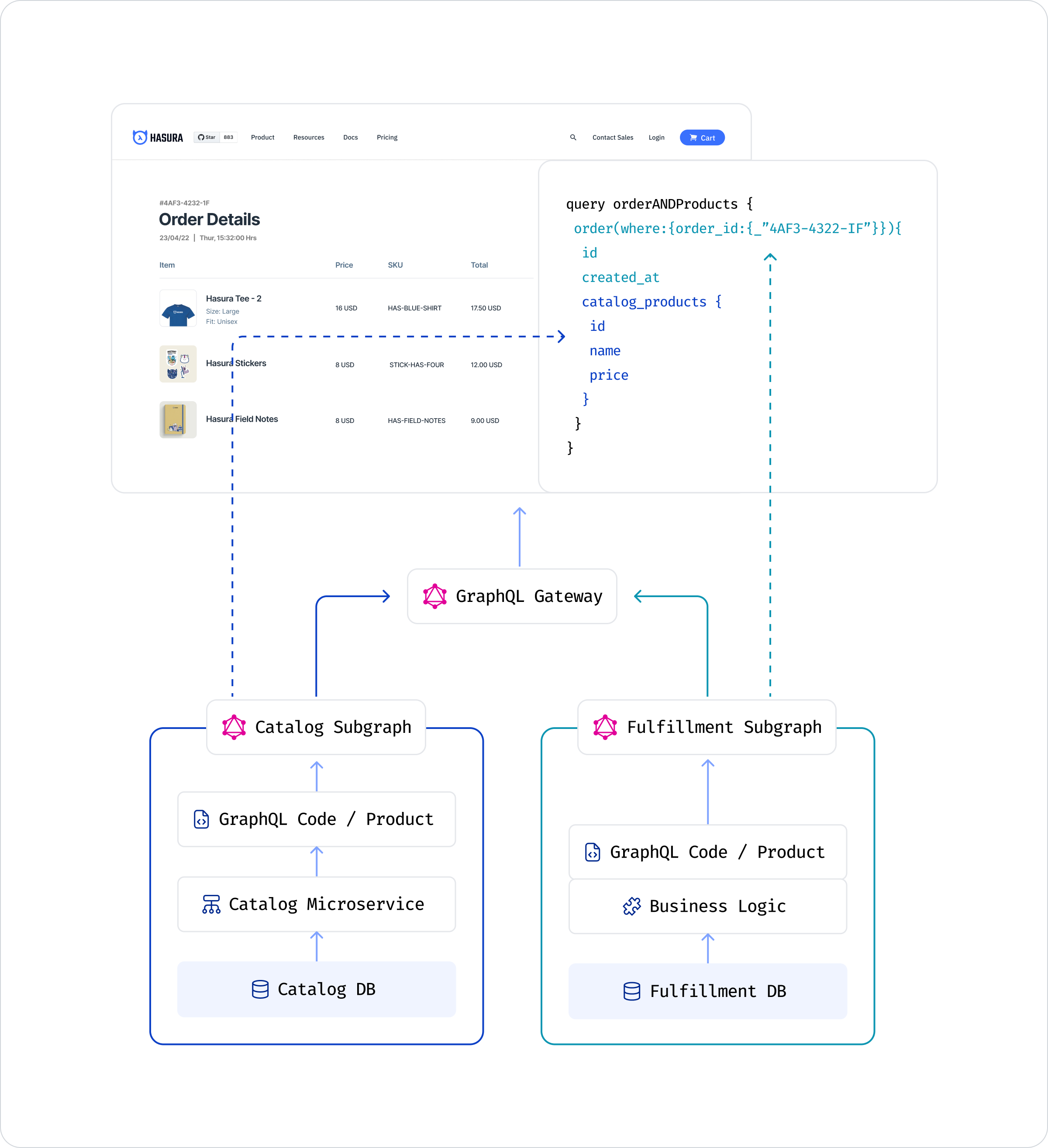
Back to our example to illustrate this. The third wireframe in our original set of requirements needs data from both the subgraphs – a specific order and information about associated products. This data is relational in nature – there’s a 1:many relationship between an order and products. We need to execute a nested query on our composed API. This can be done by defining a relationship between the order type and the catalog_product types by using the common fields id.
We still need a centralized gateway to front this related, united schema. This gateway, like the one used for schema stitching, routes part of the requests to the right subgraph. With the right kind of subgraphs (ones that allow batching), most gateways can also optimize performance by making two requests in total, one to each subgraph instead of making N + 1 requests.
The GraphQL Foundation has created a working group to formally define a formal specification for composition.
💡Tips
API platform benefits
Composability is where the value from GraphQL starts to compound with every product iteration. The richness of your unified graph can be defined as its ability to allow “joins” between its constituent subgraphs. The easier it is to do this, the easier it is to build seamless user experiences across previously siloed data in the org. This is the holy grail of any API platform strategy out there.
People and processes
With more “coupling” in this stage, the challenge of federated ownership of the unified GraphQL schema is more critical to solve. Enabling multiple teams to collaborate on and fearlessly evolve the unified graph API, without conflicts, is key to building high-quality applications. You can do this by using tools like schema registries that support schema integrity tests and regression tests (on production traffic preferably). This is another form of the classic microservices integration problem which can be solved with good tooling that provides early warning (the earlier the better – pre-commit is best!).
Performance concerns
Observe the number of redirections and layers at play here. If your gateway and subgraphs aren’t performant, your composed API won’t be performant as well.
Your subgraphs need to support batching/filtering for types involved in a join as a child. In our example, if the catalog subgraph didn’t have support for a query such as the following, you can’t reduce N + 1 requests to 2, which will result in abysmal performance:
query filterProducts {
product(where: { id: { _in: ["<list of products from order>"] } }) {
id
name
}
}
Stage 5: What’s next
After coming up with the periodic table in 1869, Mendeleev could see some patterns in the framework well enough to accurately predict as-yet-undiscovered elements. In a similar vein, what patterns can you see in the above model?
A couple of observations stand out:
Subgraphs are key: Good subgraphs make good GraphQL APIs. As we can see above, if your subgraphs are not rich (support filtering, sorting, batching/composition, etc.), your unified GraphQL API isn’t going to be very useful either. However, it is very hard to:
Manually add aggregations/compositions capabilities to a subgraph.
Manage upstream API and data sources.
Another way to state this problem is this: How do you build subgraphs that allow this kind of composition i.e. allow you to filter a parent object by its child’s attribute?
# fetch parent by child's attributes
query filterOrder {
order(where: {order.product.description {_contains: "discount"}}) {
id
value
products {
id
description
}
}
Hint: unless you work some magic into the subgraph, you cannot do this without having to create a separate subgraph. Powerful queries like this are needed to deliver on the promise of GraphQL federation.
More complexity needs more communication: As your GraphQL API evolves to incorporate more teams/subgraphs, inter-team collaboration becomes more valuable than productivity gains. As any good engineering exec will tell you, this is true of any growing team/org.
Single point of failure: Composition/federation is an attempt to centralize subgraphs (microservices). Centralized entities are lightning rods for failures with unknown root causes. How do you instrument this architecture for preventing this i.e. keeping MTTR as low as possible?
Think “git blame” for logs.
Decoupling the graph from GraphQL: An innocuous-looking learning from stage 1, which holds true later as well, is that API consumers may not always be ready to invest in learning a new specification like GraphQL. Also, what if frontend tooling evolves to be more receptive to gRPC?
The next logical step in a mature GraphQL API, will be to find a way to address federation/composition concerns from the get-go, but without compromising productivity. Supergraph.io is an architecture framework that formalizes principles that allow you to address these concerns.
Ready to gain a deeper understanding of GraphQL APIs, supergraphs, scalable adoptions strategies, federation, and more?