

Hasura DDN: The most incredible API for ClickHouse

Introduction to Hasura DDN
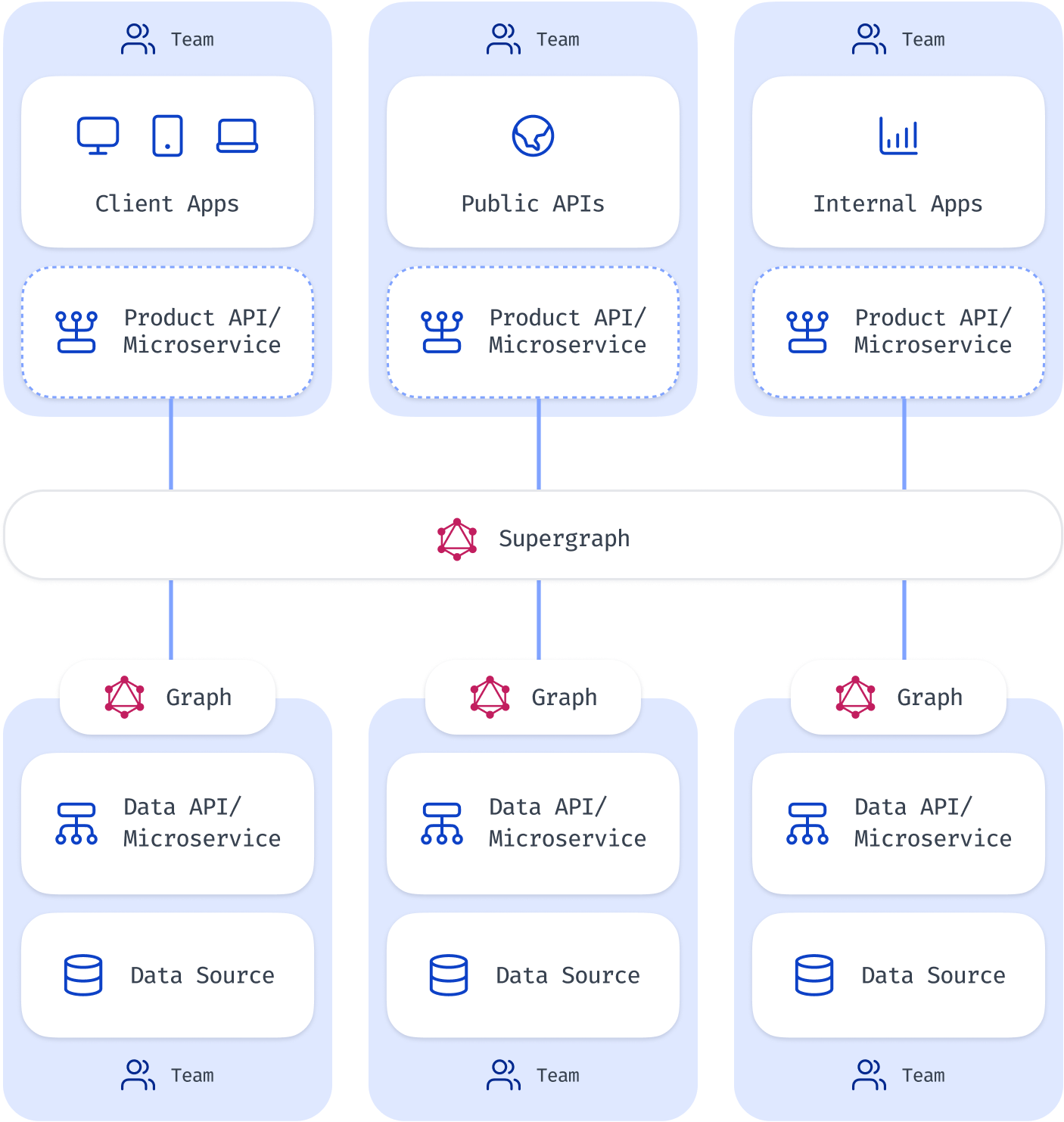
Hasura DDN benefits for all API stakeholders
API consumers get access to a blazing-fast composable API:
- Composable API: Hasura DDN can easily be configured for your PostgreSQL database immediately generating GraphQL Queries that enable sorting, filtering, and pagination.
- Supergraph federation: Hasura DDN excels at complex compositions like cross-domain joins, nested filtering, and sorting. These types of API features are notoriously challenging to code and optimize. With Hasura, you get these features out of the box.
- Performance: The Hasura query planner and the data connectors work together to leverage the native database capabilities. The query execution plan also intelligently sequences, batches, and distributes a composite query to avoid common performance challenges like N+1.
API producers can rapidly author rich APIs
- Easy configuration: Rapidly author APIs on one (or many) sources with an intuitive and declarative domain-first modeling framework. Simply model your data domain, permissions, and relations via Hasura metadata to get a standardized API endpoint.
- Connector ecosystem: Adding new databases or data services into your API is a step away. With a rich ecosystem of open source native data connectors, and the ability to build your own, getting a powerful GraphQL or REST API on your data is easy.
Platform teams get operational guarantees without the operational work
- Reliability and HA: Distributed multi-region edge network with instant rerouting away from impacted regions.
- Global performance: Smart edge routing minimizes round trip between client → Hasura runtime → data replica.
- Instant autoscaling: Sub-millisecond cold start – instantly scale out to quickly handle traffic spikes without a hiccup.
- Deep observability: Accelerate debugging and reduce MTTR with deep end-to-end visibility down to database query.
When to use ClickHouse?
- Columnar storage model: ClickHouse stores data by column rather than by row, which is ideal for analytical queries that typically only require a subset of data fields. This model significantly reduces the amount of data read from the disk, enhancing query performance and data compression rates.
- Real-time query processing: ClickHouse is designed for real-time data analysis. It can perform queries on large datasets with minimal latency, making it suitable for applications that require immediate insights from the most recent data.
- Massive scalability: It supports horizontal scaling, which allows it to manage and query petabytes of data efficiently across a distributed cluster. This makes ClickHouse an excellent choice for big data applications.
- Vectorized query execution: ClickHouse uses vectorized query execution which processes data in batches, rather than row by row. This approach optimizes CPU usage and speeds up data processing tasks.
- Data compression: It offers excellent data compression, reducing storage costs and improving I/O speeds. ClickHouse uses different compression codecs optimized for specific data patterns and types.
- SQL support: ClickHouse supports SQL for querying data, which makes it accessible to those familiar with SQL. It also includes additional optimizations and functions for time series data.
- High availability and fault tolerance: ClickHouse ensures high availability and fault tolerance through replication and other mechanisms, supporting deployment in mission-critical applications.
- Materialized views: These are used to automatically aggregate data and refresh the aggregated results as data is ingested. This feature is particularly useful for speeding up complex queries.
- Projections: Projections are a feature in ClickHouse that enhance query performance by storing additional copies of the data sorted differently from the primary key. This allows for faster retrieval of data based on commonly queried columns or expressions, thereby optimizing read operations for specific queries.
Optimize queries using ClickHouse views and projections
Using a View in ClickHouse with the NY Taxi Data
CREATE VIEW monthly_revenue AS
SELECT
cab_type,
toMonth(pickup_datetime) AS month,
sum(fare_amount + tip_amount) AS total_revenue
FROM trips
GROUP BY cab_type, month;
Using a Projection in ClickHouse with the NY Taxi Data
ALTER TABLE trips ADD PROJECTION geo_optimized
(SELECT * ORDER BY pickup_longitude, pickup_latitude, dropoff_longitude, dropoff_latitude);
Getting started
Create a free ClickHouse Cloud project
Add sample data to your ClickHouse deployment
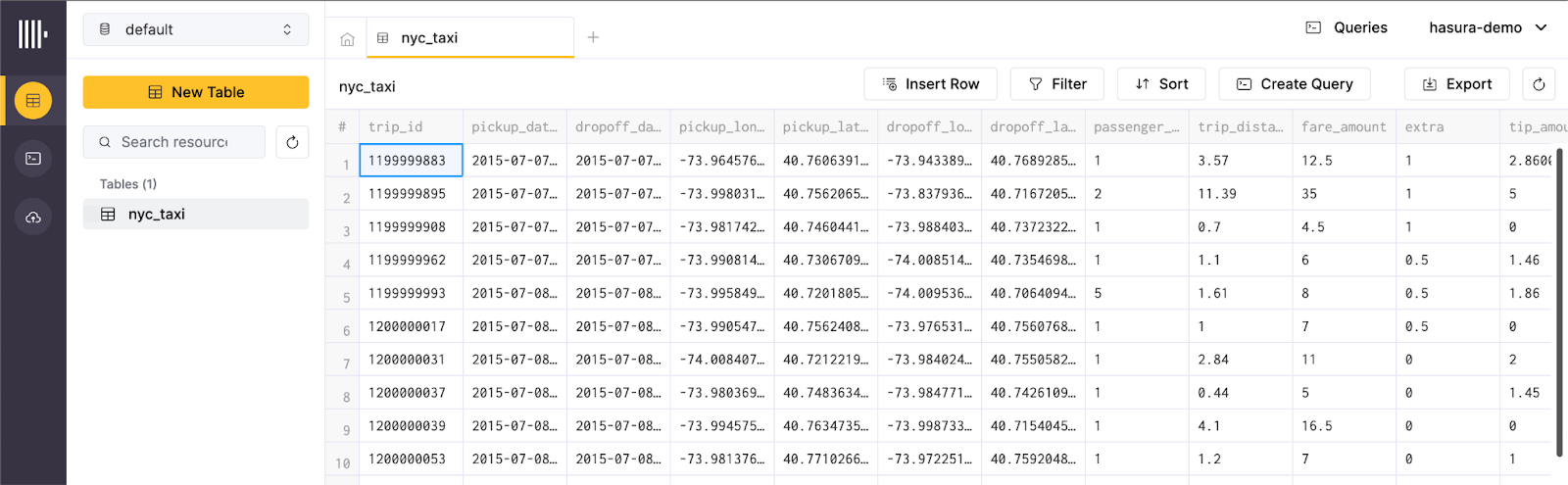
Connect to Hasura
Prerequisites
- Install the new Hasura CLI – to quickly and easily create and manage your Hasura projects and builds.
- Install the Hasura VS Code extension – with support for other editors coming soon(recommended)!
- ClickHouse account with a service to connect to that either allows access from anywhere or includes your Hasura IP address in the service’s list of allowed IP addresses.
Create project and connect ClickHouse
ddn login
ddn create project --dir ./my-first-supergraph
cd my-first-supergraph
ddn add connector-manifest clickhouse_connector --subgraph app --hub-connector hasura/clickhouse --type cloud
kind: ConnectorManifest
version: v1
spec:
supergraphManifests:
- base
definition:
name: clickhouse_connector
type: cloud
connector:
type: hub
name: hasura/clickhouse:v0.2.5
deployments:
- context: .
env:
CLICKHOUSE_PASSWORD:
value: ""
CLICKHOUSE_URL:
value: ""
CLICKHOUSE_USERNAME:
value: ""
Update connector, track models, and build
ddn dev
ddn update connector-manifest clickhouse_connector
ddn update data-connector-link clickhouse_connector
ddn add model --data-connector-link clickhouse_connector --name Trips
ddn add model --data-connector-link clickhouse_connector --name MonthlyRevenue
ddn build supergraph-manifest
Try out some GraphQL queries
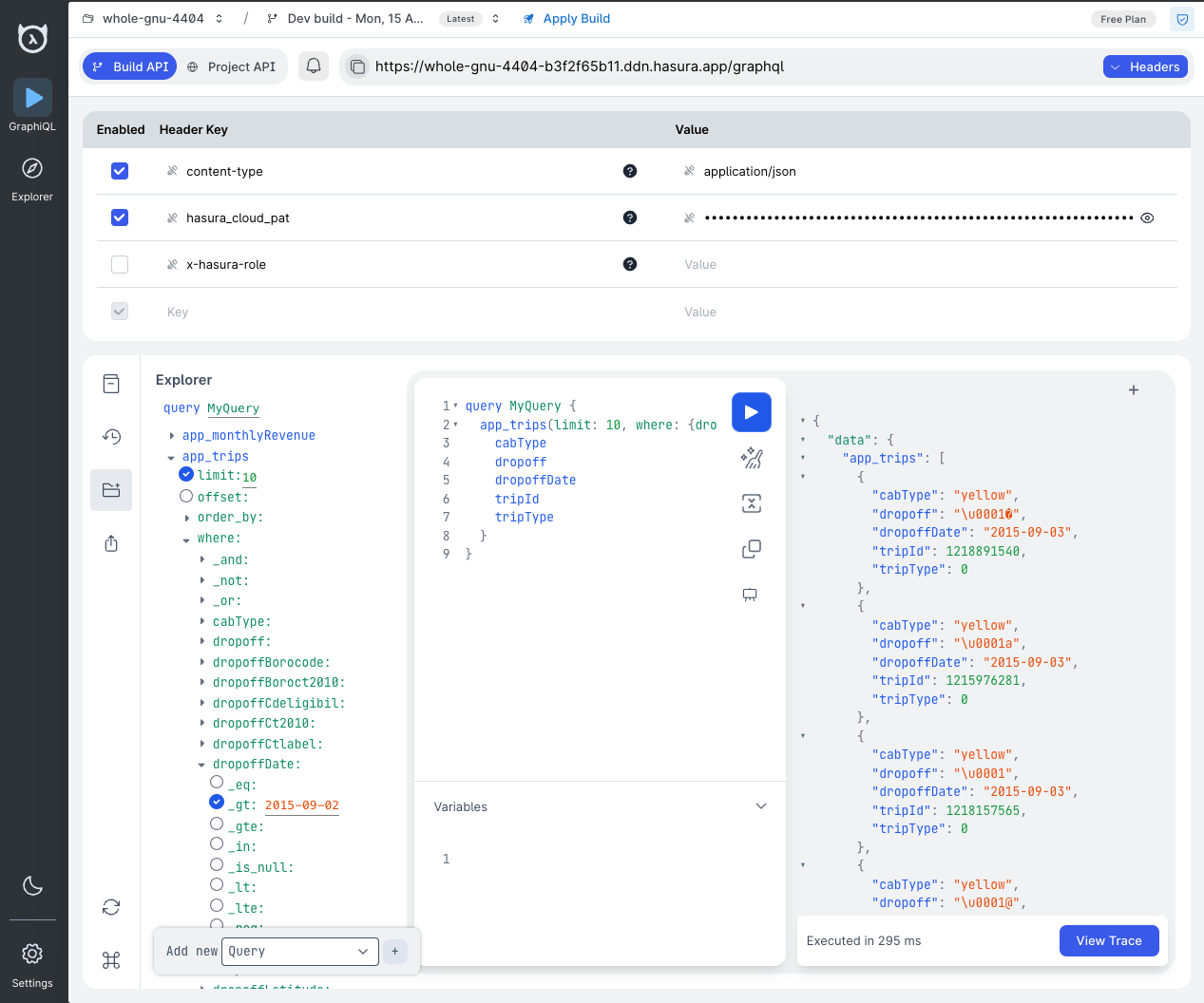
query MyQuery {
app_trips(limit: 5, where: {dropoffDate: {_gt: "2015-09-02"}}) {
cabType
dropoff
dropoffDate
tripId
tripType
}
app_monthlyRevenue {
cabType
totalRevenue
month
}
}
{
"data": {
"app_trips": [
{
"cabType": "yellow",
"dropoff": "\u0001�",
"dropoffDate": "2015-09-03",
"tripId": 1218891540,
"tripType": 0
},
{
"cabType": "yellow",
"dropoff": "\u0001a",
"dropoffDate": "2015-09-03",
"tripId": 1215976281,
"tripType": 0
},
{
"cabType": "yellow",
"dropoff": "\u0001",
"dropoffDate": "2015-09-03",
"tripId": 1218157565,
"tripType": 0
},
{
"cabType": "yellow",
"dropoff": "\u0001@",
"dropoffDate": "2015-09-03",
"tripId": 1216075068,
"tripType": 0
},
{
"cabType": "yellow",
"dropoff": "\u0001C",
"dropoffDate": "2015-09-03",
"tripId": 1218693991,
"tripType": 0
}
],
"app_monthlyRevenue": [
{
"cabType": "yellow",
"totalRevenue": 5663768.081338277,
"month": 7
},
{
"cabType": "yellow",
"totalRevenue": 16364225.173764862,
"month": 8
},
{
"cabType": "yellow",
"totalRevenue": 7528500.511831259,
"month": 9
}
]
}
}
Ready to explore?

Related reading

