Hidden in plain sight: Why your data is lying to you
Why anomaly detection matters
Every great detective knows that the most telling clues are often not obvious – the subtle irregularities, the patterns that don't quite fit. The same is true in the world of data quality. While traditional validation approaches diligently check the obvious rules (The data must be a number between 1 and 100), they often miss the more subtle mysteries that could signal deeper issues.
Consider these patterns that frequently slip past traditional validation (all of which I have fallen victim to at some point in my career):
Gradual drift in values over time may indicate calibration or calculation issues. For example, a bank's net interest margins gradually decline in a retail portfolio with interest rate stability.
Sudden changes in data distribution could signal upstream system or process changes. For example, a telco's enterprise customers' data usage patterns abruptly concentrate in off-peak hours after the rate structure changes.
Unusual combinations of valid values that might indicate process breakdowns. For example: A broker's high-value clients show declining digital engagement while maintaining branch activity.
Unexpected gaps or clusters in time series data, suggest collection or compliance issues. For example: High-dollar radiology claims clustering just outside Medicare's standard review windows.
Cross-platform data compositions create unforeseen combinations.
The rise of modern data access layers has made these subtle, cross-platform patterns more common and critical to detect. Consider this scenario:
A marketing campaign's success metrics look normal in isolation but appear anomalous when viewed alongside customer service data and social media sentiment.
Implementing a cross-domain data access layer strategy, provides this context, allowing a data anomaly detector to see the whole story when individual chapters might raise false alarms.
While these patterns are increasingly important to detect, an even more critical point in the data lifecycle often gets overlooked: when data reaches key decision-makers.
The critical last mile: Egress anomaly detection
While most organizations focus on catching data anomalies at ingestion or during processing, many critical issues only become detectable at the egress point where data flows to decision-makers. Most enterprises combine basic automated validation with end-user feedback to catch problems at this critical juncture. However, these approaches often miss subtle cross-metric patterns that true anomaly detection could catch. This "last mile" of data delivery presents unique challenges and opportunities:
Maximum business impact: When anomalous data reaches board reports, regulatory filings, or executive dashboards, the consequences are immediate and significant. A subtle pattern that slips through earlier validation could lead to flawed strategic decisions or compliance issues.
Rich context availability: We have the full context of all upstream data flows at the egress point. This comprehensive view enables the detection of subtle cross-system anomalies or the resolution of domain-level issues, that would be invisible at earlier stages. For instance, individual teams might flag a surge in product usage as suspicious, an anomaly detection system can recognize it as legitimate by correlating it with marketing campaign data.
Cross-system pattern recognition: As data products from different domains converge in final reporting, we can detect inconsistencies that individual domain validations would miss. For example, a sales spike might pass standard variance checks but appear suspicious when correlated with inventory movements and customer authentication patterns.
This last-mile perspective transforms anomaly detection from a data quality tool into a strategic business capability. So, instead of just catching errors, it becomes a tool for validating the business's narrative across all data domains.
Embracing data composition: A balanced perspective
With such high stakes, we have to consider how data composition affects our ability to detect and interpret these patterns. Modern low-data-movement tools have dramatically increased data composition capabilities, from query engines like Trino and Dremio to analytical engines like DuckDB to supergraphs like Hasura DDN (Data Delivery Network). At the same time, this power is often viewed (maybe rightfully so) with trepidation – a liability to be controlled and minimized. However, this perspective misses a crucial point: Data composition is inevitable but potentially revealing. When teams combine data in novel ways, they often uncover hidden insights and potential quality issues that might otherwise go undetected.
Modern data systems provide unprecedented visibility into these combinations and their implications. Because these systems make data composition observable, organizations can detect unexpected patterns before they become problematic. This visibility serves a dual purpose: It enables innovation through experimental data combinations while maintaining robust security boundaries.
The key lies in building adaptive systems where anomaly detection serves as a continuous feedback mechanism. These systems can identify several types of issues:
Semantic inconsistencies When data from different domains is combined, semantic mismatches become apparent.
Temporal anomalies: Combining time-series data can expose synchronization issues.
Business rule violations: Novel combinations might reveal violations that weren't visible when data was considered separately.
Data quality issues: Cross-system combinations often expose problems that single-system validation missed.
Organizations need a comprehensive approach that combines clear governance policies with flexible control mechanisms. This requirement means creating frameworks that are simultaneously permissive enough to enable discovery and controlled enough to prevent misuse. The focus should be on building the capacity to respond to unexpected compositions while maintaining security and compliance.
The AI and GenAI dimension
As you master these data composition challenges, the next big hurdle will be artificial intelligence. Data composition capabilities have more interesting implications when considering AI systems, particularly large language models (LLM) and Generative AI (GenAI). These systems don't inherently understand organizational data boundaries or valid combination patterns. The data access layer metadata serves as a natural graph structure that guides AI systems in making appropriate data combinations while providing context about relationships and usage patterns (this is similar to GraphRAG's approach).
Future implications
Consider how an enterprise LLM system might evolve when guided by a metadata graph from your data access layer. Rather than just validating data or checking relationships, the system begins to understand the natural connections between different parts of your business. It learns that customer transaction data and product inventory are connected in specific, meaningful ways – not just through database joins but through actual business logic and patterns.
This deep contextual understanding opens up fascinating possibilities. Imagine your LLM spotting a subtle correlation between customer behavior and inventory movements that human analysts missed because they looked at each domain separately. The system isn't just following predefined rules – it's learning how different pieces of your business naturally fit together from the metadata graph.
The metadata graph helps the LLM understand the relationships between different data domains. This understanding allows it to suggest relevant data combinations within the bounds of existing security controls. While access controls still enforce who can access what data, the LLM helps users discover permitted connections they might have overlooked.
Creating positive reinforcing systems
In systems design theory, the goal is to build feedback loops that provide the best signals to optimize the output systematically. This fundamental principle is hard to grasp, and consequently, I've seen it play out repeatedly and poorly in practice, whether in:
One consistent pattern emerges: While necessary, human involvement in these feedback loops often introduces more noise and slows down cycle times.
This is where AI becomes particularly interesting. Beyond just automating tasks, it offers a way to:
Maintain signal quality
Increase the speed of feedback loops
Provide better feedback to humans
In some cases, replace human involvement
Each pattern we observe contains valuable information about how data moves and transforms across the organization.
When an anomaly is detected, we start with immediate stakeholder notification and corrective action. However, the real power comes from the broader pattern analysis, which examines historical anomalies to identify common factors that can help refine our detection rules automatically.
The insights gained through pattern analysis can drive process enhancements across the organization:
Data collection methods are refined based on observed issues
Business assumptions are adjusted to reflect new understanding
Documentation is updated to capture learned best practices
Turning these insights into lasting improvements requires a carefully designed organizational structure where each team understands its role in the larger data quality ecosystem.
Organizational roles and impact
The effectiveness of anomaly detection and its associated improvement cycles depends heavily on clear ownership and collaboration across the organization. Different teams must work together in a coordinated way, each bringing unique perspectives and capabilities to the process.
Domain data teams: The foundation
Domain data teams serve as the primary stewards of their specific data areas. These teams bring a deep understanding of expected patterns and variations within their domains, developed through years of hands-on experience with specific data types and systems. They establish baseline expectations for normal behavior within their domains and provide crucial context when anomalies are detected.
Federated data teams: The connectors
Federated data teams act as bridges between different domains, managing the cross-system infrastructure that makes modern data composition possible. These teams maintain the technical foundation for anomaly detection, ensuring that detection rules and thresholds remain consistent across systems.
Like LEGO pieces from different sets combining to create new structures, standardized data products can be confidently assembled into novel combinations.
Their unique position allows them to spot patterns that might be invisible when examining individual domains in isolation. At the same time, their standards ensure that new data products naturally fit into the broader ecosystem.
Cross-domain data teams: The innovators and controllers
Cross-domain data teams represent both innovation and control functions within the organization. In financial institutions, risk management teams serve as a crucial cross-domain function, combining data from multiple systems to monitor institutional risk exposure. Financial control teams bridge multiple domains by reconciling data across trading, settlement, and accounting systems.
GenAI initiatives represent a particularly demanding type of cross-domain work. These teams must:
Integrate data from across the entire enterprise
Maintain extremely high-quality standards
Develop systems that autonomously generate content and make decisions based on integrated data
The success of these organizational structures ultimately depends on effectively communicating anomalies and insights to the right stakeholders at the right time. Each team, from domain owners to cross-domain specialists, needs different levels of detail and context to take appropriate action.
Managing stakeholder engagement
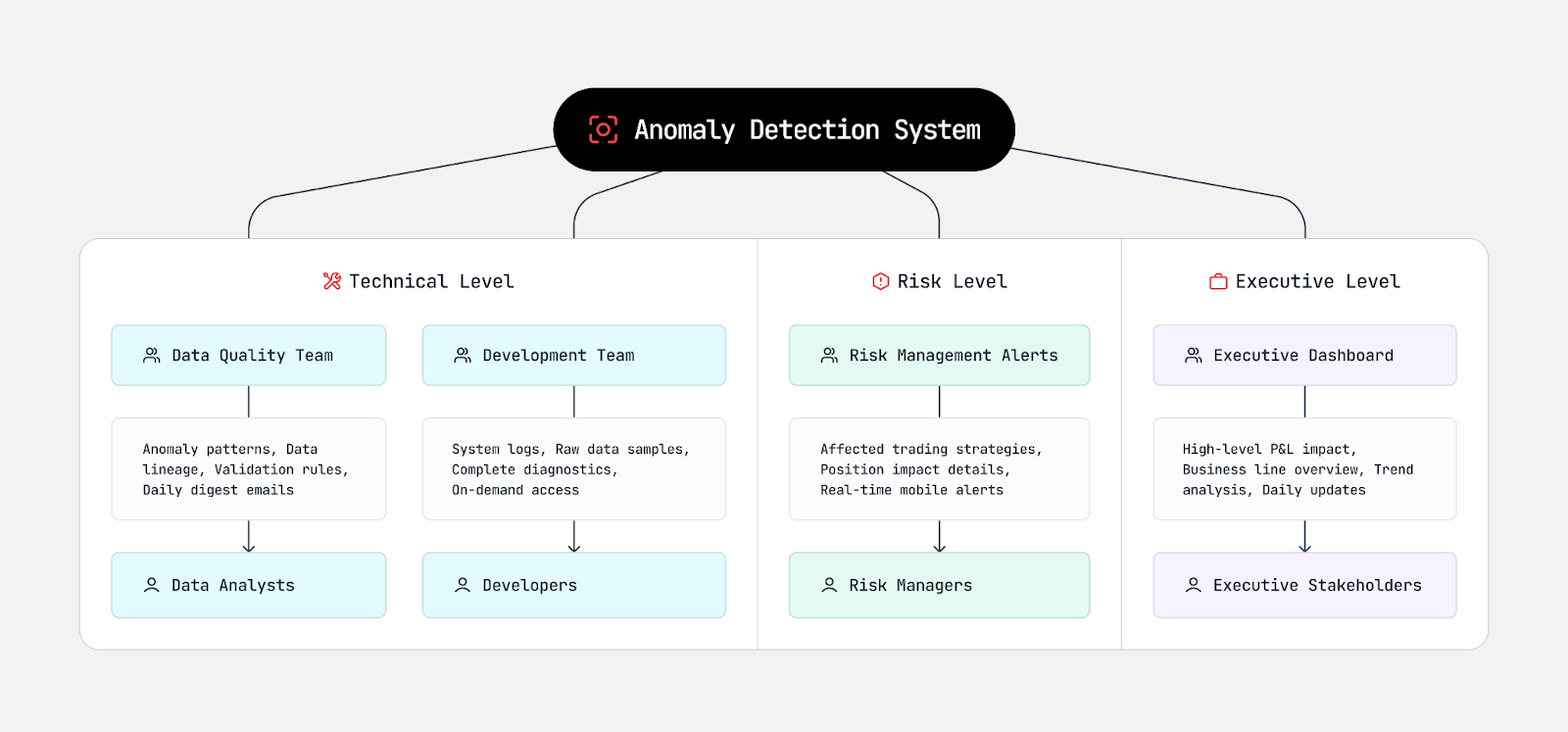
Consider anomaly detection alerts like a modern news organization trying to serve different audiences. Just as a good news outlet knows some readers want breaking news alerts while others prefer detailed analysis, our anomaly detection system must deliver information in layers of increasing detail.
Progressive disclosure principles help manage this complexity by providing different levels of information to various stakeholders. For instance, when a significant data anomaly is detected in trading data:
The timing and format of these notifications vary by role. A risk manager might need immediate mobile alerts for anomalies affecting active trading positions, while data quality teams prefer daily digest emails grouping related anomalies for systematic analysis. Meanwhile, executive dashboards might focus on trend analysis, showing how anomaly patterns evolve and their correlation with business metrics.
Implementation
I’ve created an open-source reference implementation demonstrating some of these principles using Hasura DDN platform. This plugin shows how to implement egress anomaly detection that leverages metadata from your data access layer while maintaining performance and scalability. You can explore, contribute, or adapt the implementation for your use case at this GitHub link.
Conclusion
As organizations continue to evolve their data ecosystems, anomaly detection systems must advance to meet new challenges. Future enhancements will likely focus on more sophisticated learning capabilities and deeper integration with the business context. While business process rules remain foundational, the feedback loop between validation rules and anomaly detection could become more autonomous, guided by metadata-rich data access layers and AI systems that understand the organizational context.
The role of data composition in this future becomes increasingly critical.
As data products from different domains converge, the ability to detect meaningful patterns while filtering out spurious correlations will separate leading organizations from followers. Yet even as automation streamlines specific tasks, the demand for human expertise will likely grow in data governance, ethical considerations, and interpreting complex anomalies.
Data quality professionals must adapt by developing new skills, including data science techniques, machine learning approaches, and AI, all while focusing on higher-level tasks requiring human judgment and critical thinking.
The path forward lies in building systems that effectively combine human expertise with machine intelligence, creating virtuous improvement cycles that enhance data quality and business value. Organizations that master this delicate balance – maintaining necessary controls while enabling innovation through data composition – will be best positioned to thrive in an increasingly data-driven future.
Ready to explore Hasura DDN's capabilities to achieve true data quality and business value? Simply click here to get started!