

Instant GraphQL APIs on DuckDB
What can the Hasura DuckDB connector do?
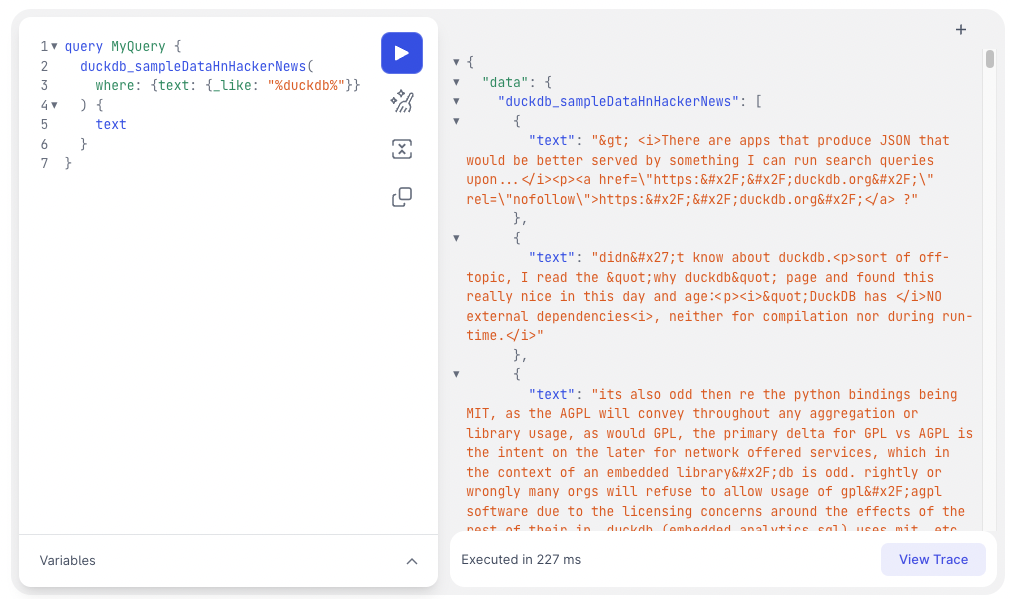
What capabilities does the Hasura DuckDB connector have?
query Query {
duckdb_chinookMainAlbum {
albumId
artistId
title
}
}
query Query {
simple_predicate: duckdb_chinookMainAlbum(where: {albumId: {_eq: 10}}) {
albumId
artistId
title
}
and_predicate: duckdb_chinookMainAlbum(
where: {_and: [{albumId: {_gt: 1}}, {albumId: {_lte: 2}}]}
) {
albumId
artistId
title
}
}
query Query {
order_by: duckdb_chinookMainAlbum(order_by: {albumId: Desc}) {
albumId
artistId
title
}
paginate: duckdb_chinookMainAlbum(offset: 10, limit: 10) {
albumId
artistId
title
}
}
query Query {
complex_query: duckdb_chinookMainAlbum(
limit: 10
offset: 10
order_by: {albumId: Desc}
where: {_or: [{albumId: {_lt: 10}}, {albumId: {_gt: 20}}]}
) {
albumId
artistId
title
}
}
query Query {
relationship_query: duckdb_chinookMainAlbum {
albumId
title
artist {
artistId
name
}
tracks {
trackId
name
}
}
}
query Query {
relationship_filter_query: duckdb_chinookMainAlbum {
albumId
title
tracks(
limit: 10
order_by: {trackId: Desc}
where: {name: {_like: "%Spellbound%"}}
) {
trackId
name
}
}
}
query Query {
relationship_predicate_query: duckdb_chinookMainAlbum(
where: {tracks: {name: {_like: "%Spellbound%"}}}
) {
albumId
title
tracks {
trackId
name
}
}
}
Conclusion

Related reading

