Introducing GraphQL Joins for federating data across GraphQL services
We are excited to announce the release of GraphQL Joins, available in Hasura v2.6.0.
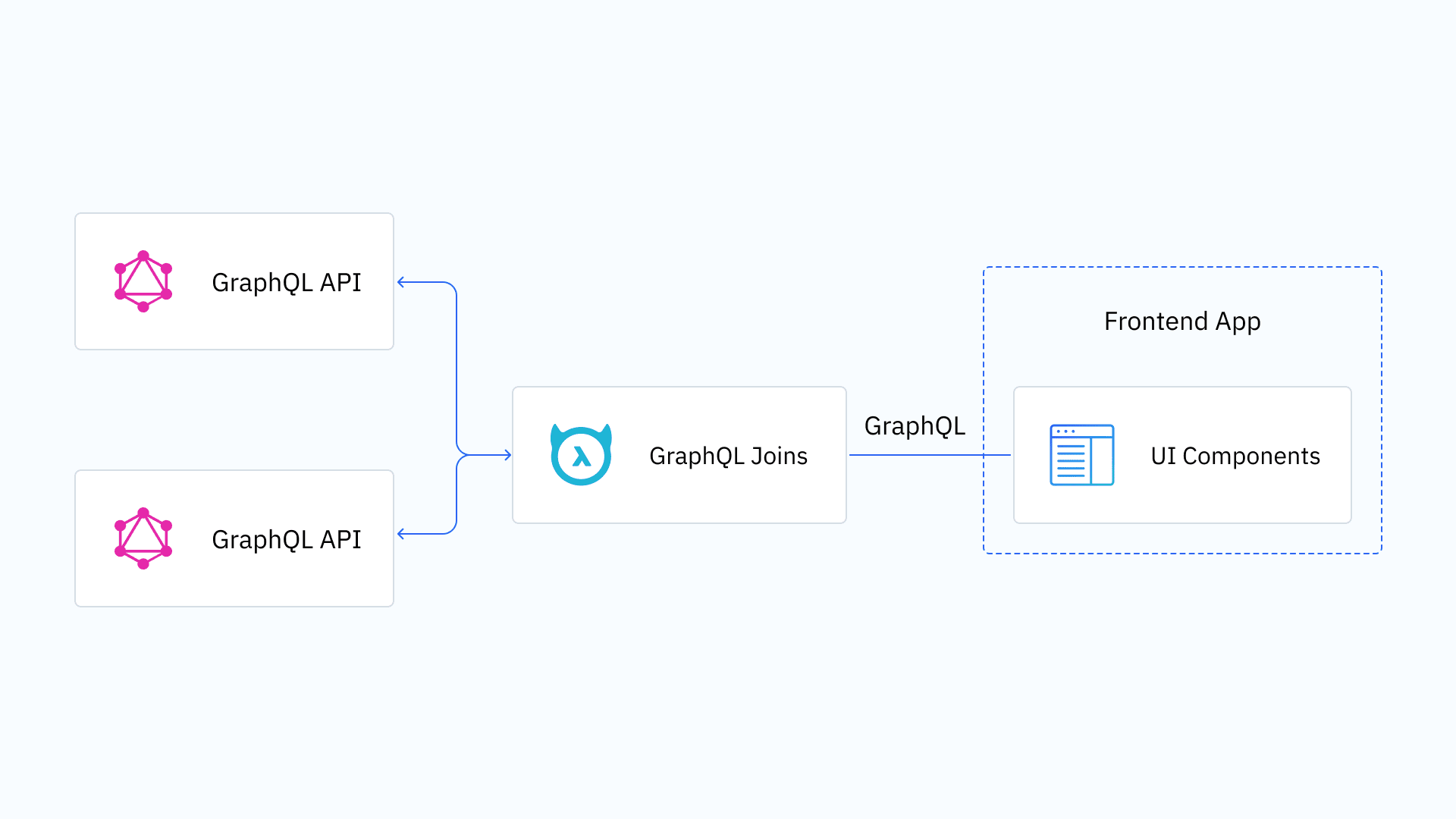
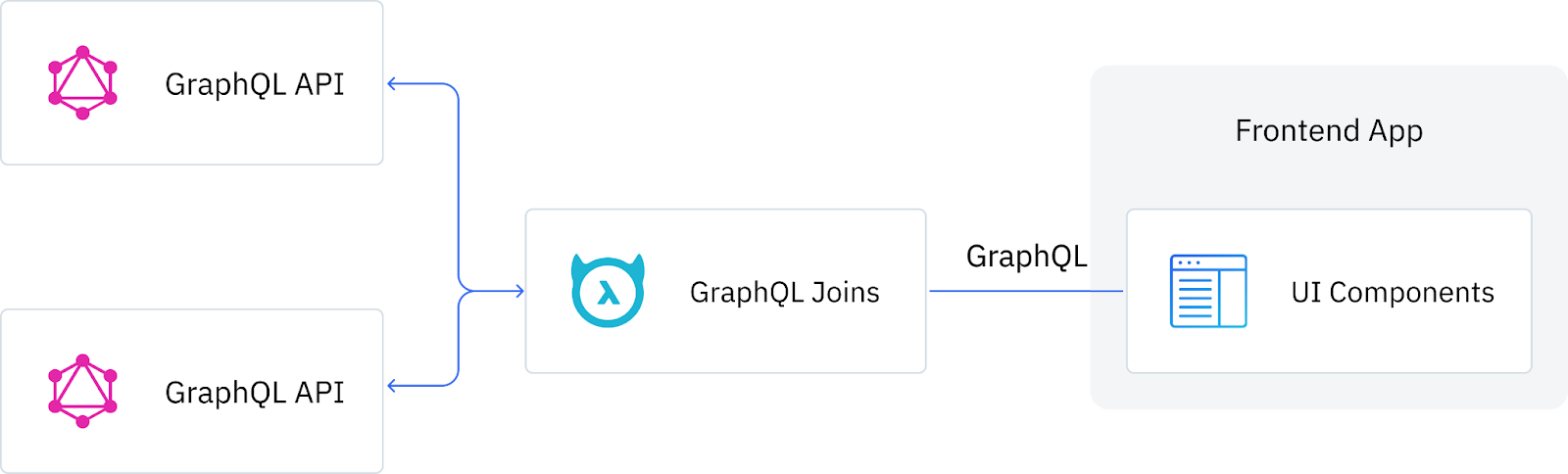
With GraphQL Joins, developers can federate their queries and mutations across multiple GraphQL services as if they were a single GraphQL schema without modifying any of the underlying APIs or writing any extra code or requiring any changes to the upstream GraphQL service.
At its core, GraphQL joins is the simple idea of creating a relationship from one type in the GraphQL schema to another resolver in the same or a different GraphQL schema.
GraphQL Joins with Hasura
GraphQL Joins enables the following types of use-cases:
For Hasura users: Run custom mutations and queries on your GraphQL service that return references to entities in your database powered by Hasura (learn more)
For teams with multiple GraphQL services: Unify and join across multiple in-house or 3rd party GraphQL services (learn more)
For teams with great REST APIs already in place: If you have an OpenAPI (swagger) spec-ed API that maps well to a GraphQL schema automatically, use GraphQL Joins to create relationships between the different entities and prevent N+1 queries on the client.
This is useful for users building GraphQL backends with Hasura or users looking at publishing a unified GraphQL data API for other teams and developers.
In this blog post, we cover the following topics:
Evolution of data federation in Hasura
How to set up GraphQL joins in Hasura
Creating relationships
Managing type conflicts
Managing schema evolution and allowing upstream GraphQL services to change automatically
Authentication to upstream GraphQL services
Authorization
Scope access to specific parts of the unified GraphQL API
Caching
Hasura internals: How query execution works
Evolution of data federation at Hasura - joining data across databases, REST and GraphQL APIs
Hasura allows joins across REST APIs (coming soon)
Setting up GraphQL Joins
Testing out GraphQL joins should take you all of 60 seconds with Hasura! Watch this video to see what it looks like or try it out yourself!
Let us look at how GraphQL Joins can be tried out in a few simple steps with Hasura.
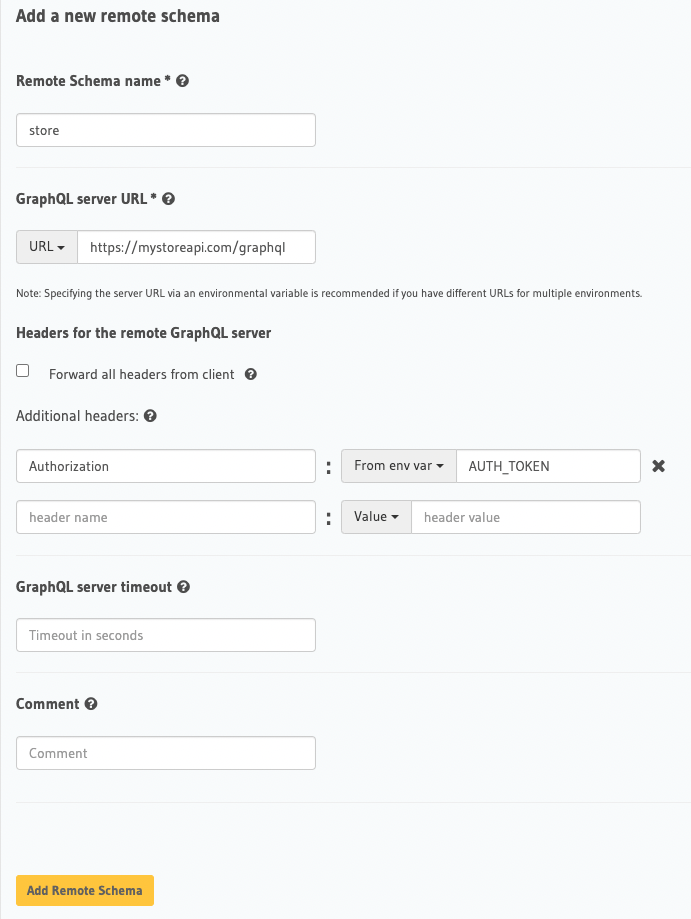
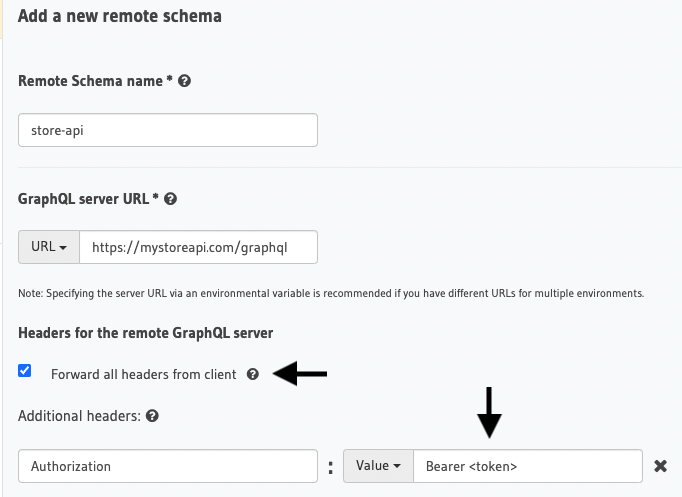
Add any two GraphQL compliant schemas to Hasura as a Remote Schema. Just plug the GraphQL endpoint, and add any relevant headers to be forwarded (including the tokens, secrets etc).
Add a new remote schema via Hasura Console
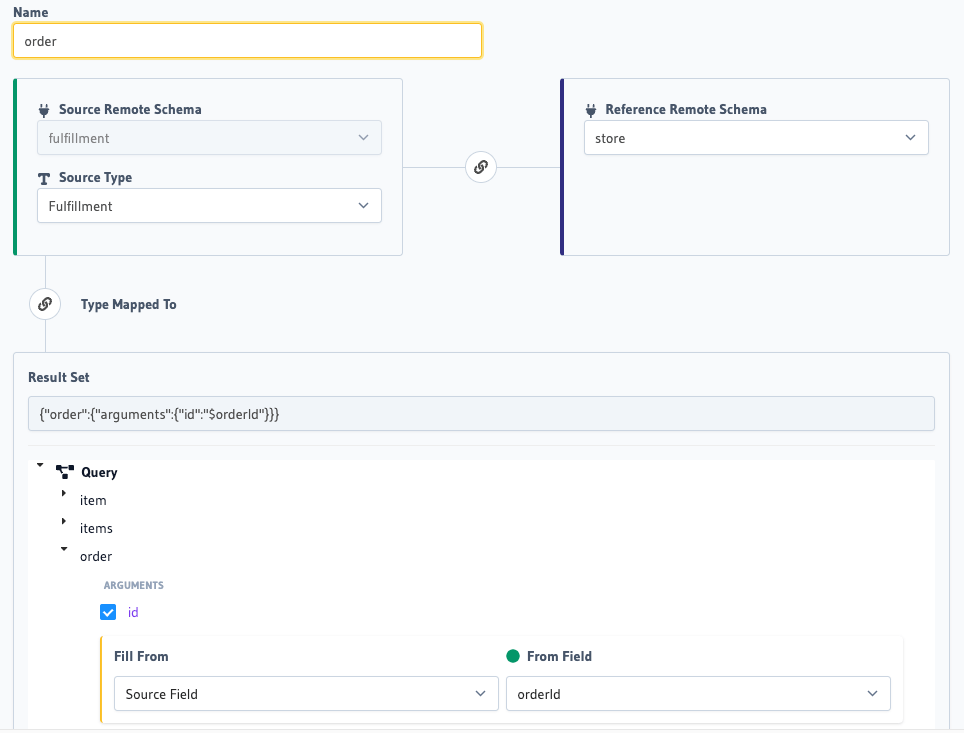
2. Head to the source Remote Schema from where you want the relationship to be set up and navigate to the Relationships tab.
3. Configure the relationship by selecting the source type, target remote schema and the join argument to be used that will be a common parameter in both the APIs. For example, orderId as in the example below.
4. Create the relationship and try out the GraphQL query that uses the relationship. For example:
{
fulfillment(orderId: 1) {
status
order { <---- order is coming remote schema 2
lineItems {
item {
name
}
}
}
}
}
Bonus Tip: You can also set up a remote relationship between the same schema! Just select the same schema for both the source and target and set up the relationship.
Q: What if I want to add a GraphQL service maintained by a 3rd party?
A: It just works. There are no changes required in any of the upstream GraphQL servers to add them to Hasura for the federation setup. All your favourite public GraphQL APIs like GitHub, Contentful, GraphCMS etc can be added and used to set up remote relationships without any extra code or configuration. Check out Data Hub for more public GraphQL APIs.
Handling type conflicts
A common issue that you might encounter, especially with a vendor or 3rd party GraphQL API are conflicts in the merged GraphQL API. For example, common GraphQL types like “users” might overlap. You will need the ability to handle these conflicts while you add them as a remote schema to Hasura so that when Hasura unifies them into a single API all consistency checks go through.
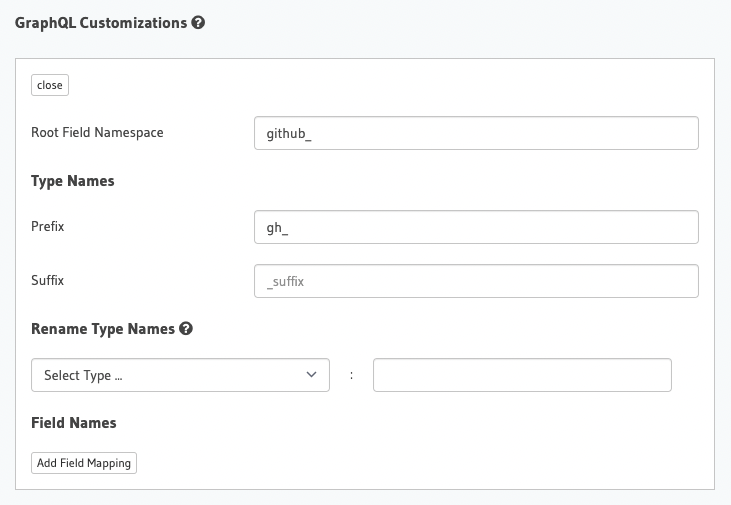
Hasura lets you transform your Remote Schema using a prefix or suffix for the root query or for the individual types in the schema. If you want to go deeper, you can also transform individual types to have their own unique names to avoid schema collision or for use cases like a better naming convention.
Q: I’m encountering a type conflict error while adding a remote schema. How do I resolve this?
A: The error should tell you which type that is already existing in the GraphQL schema is conflicting with the new remote schema that is being added. The conflict could be with the fields and queries generated from the databases connected to Hasura, or with another remote schema that was added to Hasura earlier. Once you identify the conflicting type from the error message, you can head to the relevant page on the console (either the database tables or remote schema modify) and set up the transformations and proceed with the addition of the new remote schema without any hassles.
GraphQL Customizations
Use-case examples
Your custom resolvers that return references to entities in a database
The data coming in from a GraphQL API can be joined with data already existing in a database. This is possible by creating a relationship from a field in the custom GraphQL server to a field in the database table.
GraphQL Joins
For example, consider the following query:
{
order(id: 1) { <---- order is served by a GraphQL API
status
customer { <---- customer data comes from a Postgres database
name
email
}
}
}
Joining across multiple GraphQL APIs
In this use case, you have two independent GraphQL APIs that have some form of related data which can be configured to return the joined data.
GraphQL Joins with Hasura
For example: consider the following query:
{
fulfillment(orderId: 1) {
status <--- fulfillment data is coming from remote schema 1
order { <---- order data is coming remote schema 2
lineItems {
item {
name
}
}
}
}
}
From an OpenAPI REST service to a GraphQL API with relationships between types
You can create relationships within the same remote schema types. This is useful in cases where you are incrementally migrating from a REST API to GraphQL using tools like OpenAPI to GraphQL where the relationship setup is lost during the translation of the API.
Approaching Schema Evolution
The initial data federation setup will continue to work till the upstream API(s) change. As the application evolves, the API will undergo schema changes, either additive, removal or via deprecation of types. Here we have two scenarios that need to be handled.
Simple schema updates (non-breaking changes)
Breaking changes
Both need to be handled differently. Hasura lets you apply schema changes in your CI/CD system via the metadata API that is exposed. If there are simple non-breaking schema changes, you can just reload the metadata to reflect the updates. This will work automatically and no more additional configuration or code changes are required.
If there are breaking changes, post the metadata reload, they are handled gracefully at the Hasura layer. For example, If an existing GraphQL type is used in a remote relationship and if the schema undergoes a breaking change, Hasura throws metadata inconsistency warning(s) wherever relevant. This can be used to debug what will stop working before going to production.
Hasura throwing inconsistent metadata warning!
Some of the common breaking changes include fields, inputs, types, and arguments having been modified for the existing schema. And of course, any removal of any of these would be considered a breaking change as well.
You can run regression tests in your CI/CD workflow to identify such issues and make the appropriate changes to the client code. Hasura Cloud makes this setup easy to configure and run these tests on your staging/production environments.
Integrating with other tools
There are OSS tools and services that let you manage the schema changes at the CI/CD layer. graphql-inspector is an OSS tool that can be used as a GitHub action to monitor breaking changes to the schema connected to the GitHub repo. There are also managed services like Hive by The Guild and Apollo Studio which lets you manage schema in their registry and view the schema diff with breaking changes as the API evolves. The managed services work well for monitoring GraphQL APIs that you write and have control over.
Keeping remote schemas up-to-date
If the upstream GraphQL API is maintained by someone else where you have no control over the schema or when there might be a breaking change, you can set up a monitoring step to do a schema diff on a continuous basis and check if there are any changes (especially breaking)
Tip: If you want a DIY monitoring solution, you can make use of Hasura Scheduled Triggers to run a function that uses graphql-inspector to continuously do a schema diff on a regular basis and set up a notification system to know if and when a vendor API changes.
Once a schema change is identified, you can trigger the CI/CD workflow to reload the Hasura metadata for the updates to reflect.
Handling Authentication for upstream GraphQL servers
The upstream GraphQL servers will most likely require some form of authentication to introspect and expose the schema. In order to handle this authentication, you can set up the tokens during the creation of the remote schema by forwarding the right headers.
You can also forward any additional headers from the client to the upstream server. This way, if the frontend client is using a specific token that authenticates and authorises certain parts of the upstream API, that can be taken care of by Hasura with the forward headers set up.
Enable forward all headers from client on remote schema
Authorization for role-based schemas
Hasura supports role-based authorization where access control is done by creating rules for each role and operation.
By default, the entire schema of your external GraphQL API is part of the unified API that Hasura exposes. But you might want to restrict access to certain parts of the schema for security reasons.
To enable permissions, an environment variable needs to be configured.
Now, let us look at different authorization use cases:
Expose a subset of the schema for a given role
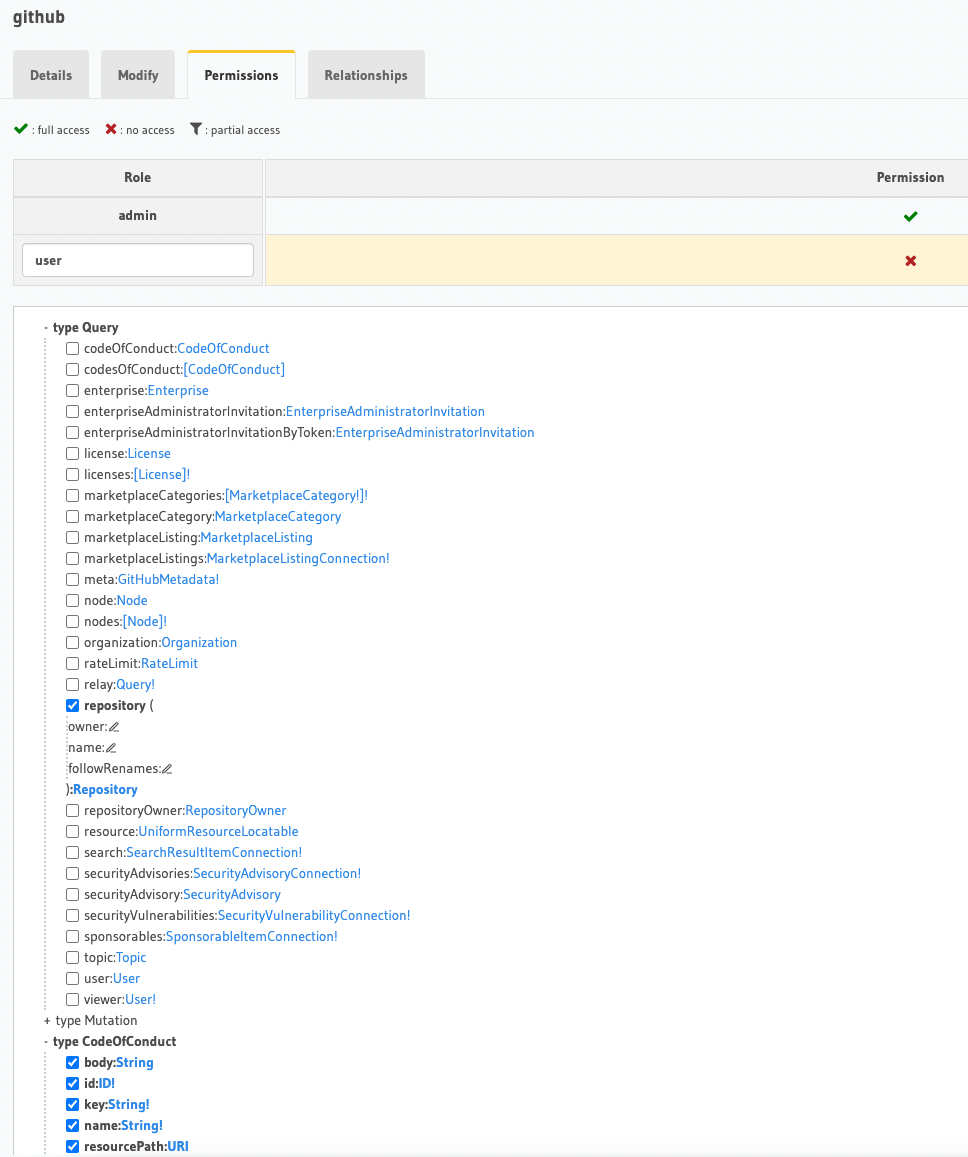
The remote schema added to Hasura would potentially have a larger schema, where every query need not be exposed to the API layer. Consider the GitHub's public GraphQL API available at https://api.github.com/graphql.
We want to be able to only fetch repository details from the API for a role called user. All other schemas are not required to be exposed in the API for this given role. We can configure this at the Hasura permissions layer.
Role based Authorization for GitHub's public GraphQL API
Caching for Remote Schemas and Federated Data
Hasura Cloud supports query response caching that helps improve performance for queries that are executed frequently. If in case, your federated GraphQL query is executed frequently, you can make use of caching in Hasura Cloud.
For example, the query can be modified to have the `@cached` directive and the response from the joined data will be cached.
{
fulfillment(orderId: 1) @cached(ttl: 120) {
status
order {
lineItems {
item {
name
}
}
}
}
}
That’s it. The federated data can be cached automatically with the addition of a directive. Note that, the caching will not work if you have enabled forward headers from the client while setting up the remote schema. This is currently a limitation.
Hasura Internals: How query execution works
Unlike joins across two tables in the same Postgres database, all “remote” joins must be performed by the GraphQL Engine, regardless of whether the data originates from a database or a remote schema: each source is independent from all the others, and only the Engine has the full knowledge of all of them. To perform such a join, we use a “dataloader” approach: we analyse the query ahead of its execution to identify each individual part, and we modify each individual sub-query to also extract the required join keys; the engine then issues them one by one and stitches the results together.
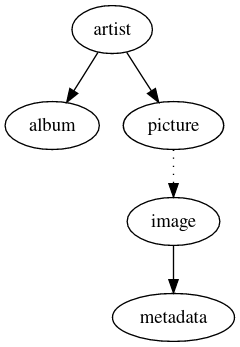
Consider a complex nested joins like the one below:
From the artist object, we perform two remote joins: one to get the album, and one to get a picture; however, after performing that second remote join, we perform another one, from the picture to its metadata: in our join tree, the picture node contained another recursive join tree.
In the engine, instead of the joins being one step, they are now performed iteratively: after performing the very first step of the query, we traverse the join tree. At each leaf, each join that needs to be performed, we repeat the process recursively with that node’s sub-tree; we perform, in essence, a depth-first traversal, constructing the resulting JSON object on the way back up.
However, when extending the Engine to allow joins from remote schemas, we encountered an additional difficulty, which forced us to refine how our join trees are defined: the path at which a join must be performed can be ambiguous! Consider, for example, the following example:
query($nodeId: Int!) {
node(id: $nodeId) {
... on Artist {
articles {
name
}
}
... on Writer {
articles {
name
}
}
}
}
Depending on the actual GraphQL type of the object that is being returned, we must perform one of two possible joins: either one from artist to articles, or one from writer to articles. But, in both cases, the part of the answers’ object that needs to be modified is at the path node.articles! To be able to differentiate between the two, we need to be able to distinguish them in the join tree, and furthermore we must be able to know, in the engine, what the actual GraphQL type of the returned object is.
To do so, we have changed our join tree definition to allow each branch to be annotated with a typename: in this case, our join tree would have two joins: one at the path node.(Artist.articles), and one at the path node.(Writer.articles). We only do this for paths that depend on the runtime GraphQL type. And to retrieve the runtime type, we add a phantom field in the request that extracts the __typename of the object, that we then use when traversing the join tree.
Try out GraphQL Joins with a demo
We have created an example of GraphQL Join where two custom GraphQL servers written using GraphQL Yoga are added as a remote schema and data is being joined based on an argument.
Get started with GraphQL Joins today on Hasura Cloud. Try it out for yourself and let us know what you think!
We really want your feedback. We’ve created a GitHub issue and would love to hear from you. Ping us on discord. If you’d like a demo of different use-cases and want to chat about how this will work with what you’re doing, reach out to us.
Join our webinar
Join Co-founder and CEO, Tanmai Gopal, on May 12th for A Deep Dive into Data Federation with GraphQL Joins. Hear how Hasura GraphQL Joins enhances data federation for developers who have: - More than one GraphQL API – whether their own or a third party’s - Existing investments in GraphQL servers to which they would like to add new data sources - Databases for which they haven't yet created APIs