On behalf of the entire team at Hasura, I'm delighted to announce the release of Hasura GraphQL Engine 2.0 (also just called Hasura 2.0). 🎉
Hasura 2.0 is our most significant release over the last few years, but is also entirely backwards compatible with Hasura 1.x. Over the last 85 releases of Hasura over 2 years, we've endeavoured to never break user facing APIs and this major release is another checkpoint in that ensuring that users get new features without having to refactor their work. In fact, Hasura 2.0 == Hasura 1.4, but it was such a big release that we decided to call our next 1.4 release, 2.0.
TL;DR: How do I get started? If you'd like to skip the spiel and just head on straight to trying it out, head to the docs to try 2.0 with Docker or try it for free on Hasura Cloud - our managed service offering of the Hasura GraphQL Engine. Watch this webinarto get an overview of all the new capabilities in our v2 release.
So, what is Hasura 2.0?
Hasura 2.0 captures fundamental changes inside the GraphQL engine that allows Hasura to serve the needs of a much larger class of mission critical applications.
1. Connecting multiple databases simultaneously and database generalization
We first built Hasura with exclusive support for Postgres. This was a deliberate choice so that we could focus our engineering and product efforts and given the rise of Postgres and the Postgres ecosystem exploding this choice paid off well.
With Hasura 2.0 we've set the foundation to unlock 2 key capabilities:
Connect to multiple independent databases simultaneously
Database generalization - accelerate Hasura support for additional database engines
1.1 Connecting to multiple databases simultaneously
As we've worked with our users, especially enterprise & mission critical workloads, we've noticed increasingly that users often bring multiple new or existing databases, even if its just Postgres. These are 2 of the top use-cases we've seen:
Multi-tenancy: Different tenants have their data grouped into different Postgres databases. Often this is to enable scaling or to enforce stricter data isolation.
Different workloads: A Postgres database optimized for search might be very provisioned and tuned very differently from a database optimised for timeseries (using say, Timescale) which in turn would be very different from a Postgres database tuned for high transaction volumes. Data is consumed from these different sources together.
Hasura 2.0 allows bringing in multiple databases simultaneously to a single instance of Hasura GraphQL engine (or a scaled up cluster of Hasura instances).
Instead of having to supply a single env var, you can now add and remove database sources on the fly on a running Hasura instance!
1.2 Database generalization
Postgres was always just the beginning at Hasura. We've now refactored our query compilation pipeline so that it can be generalized to any database easily.
Existing or legacy mission critical data is often not on Postgres and the cost of ETL-ing that data to Postgres is infeasible and defeats the purpose of being able to query the source of truth directly - especially for fast-moving operational/realtime data.
And ofcourse, new data workloads also might go into other databases that aren't just Postgres!
With Hasura 2.0 we're launching with support for SQL Server and our first OLAP database - BigQuery.
We'll be rolling out SQL Server support on Hasura Cloud in phases over the coming day. You can also head to the docs to try Hasura with Docker and your own SQL Server database.
We've started off with generalizing to relational databases with the goal of making sure a new relational database engine can be added to Hasura within 2 weeks.
Hasura's philosophy of adding a new database is to keep the final GraphQL API similar, but without trying to normalize all database engines to the same common denominator interface. Hasura aims to bring out the best of a particular database engine while ensuring all the Hasura goodness of GraphQL, authorization and eventing Just Work.
We've started to put together a contribution guide of how you can extend a few typeclasses to add support for your favourite SQL system and also work closely with the maintainers to keep improve native support for that database and its goodness (its specific types, functions, operators, connection handling etc.).
Over the course of the year, we'll be bringing other types of databases systems into Hasura: document and key-value stores are big on our minds! Let us know what databases you'd like to see support for via our Github so that others can weigh in as well and help us prioritize.
Hasura supports "joining data" over heterogeneous sources so that API consumers see a semantically unified Graph of their API models. Currently, Hasura supports joining in certain specific directions.
Coming soon, in order of priority, are the following remote join capabilities:
Remote Schemas to databases: Join the output of any GraphQL API datasource with a data model
Remote schemas to remote schemas: Join types across different GraphQL services
Database to database: Join across different databases
GraphQL APIs have emerged as the best modern API for humans to explore, consume and integrate.
While GraphQL's goal at inception was to provide a specification for automating API composition on UIs and creating a type-safe client-server contract over JSON, its success goes far beyond that. Arguably, and much to the frustration of true GraphQL stans, GraphQL fragments and Relay style GraphQL are not as popular as they ought to be. This is because GraphQL solved a much bigger problem than just automating the tedious portions of API composition and integration on the UI.
GraphQL represents two big shifts in the way we think about APIs:
Self-serve consumption: API consumers can browse, explore, test and integrate APIs with a much tighter feedback loop without requiring the typical kind of hand written documentation & tooling.
Query what you want: API consumers can craft an API query to get precisely the data they want without requiring humans to build custom endpoints for their favourite shape of data. Imagine a database that served data only in a fixed shape - ridiculous right! And now that's what we want, but from our APIs too. Performance, caching, security, etcetera should Just Work as much as possible.
However, in practice, we've seen three big deterrents to using a GraphQL API in production - even where it's "technically" feasible:
The lack of GraphQL vendor tooling around GraphQL in production - ops, caching, monitoring, error and QoS reporting, authorization, security are all entirely new with GraphQL. In mission critical scenarios, especially in enterprise environments, the cost of GraphQL adoption might simply be too high.
Consumers who are not building frontend applications (say on a public API, or for developers building other services) might not want to or be able to use GraphQL clients in their code. As humans, they still love GraphQL for the tooling, but actual usage might not be possible
REST APIs are not going away. This means that teams might have to maintain multiple API engines forever to make sure they don't alienate some API consumers. The cost of maintaining a GraphQL API and simultaneously a REST API is ridiculous. (REST can also be seen as a placeholder here for teams that use gRPC, say).
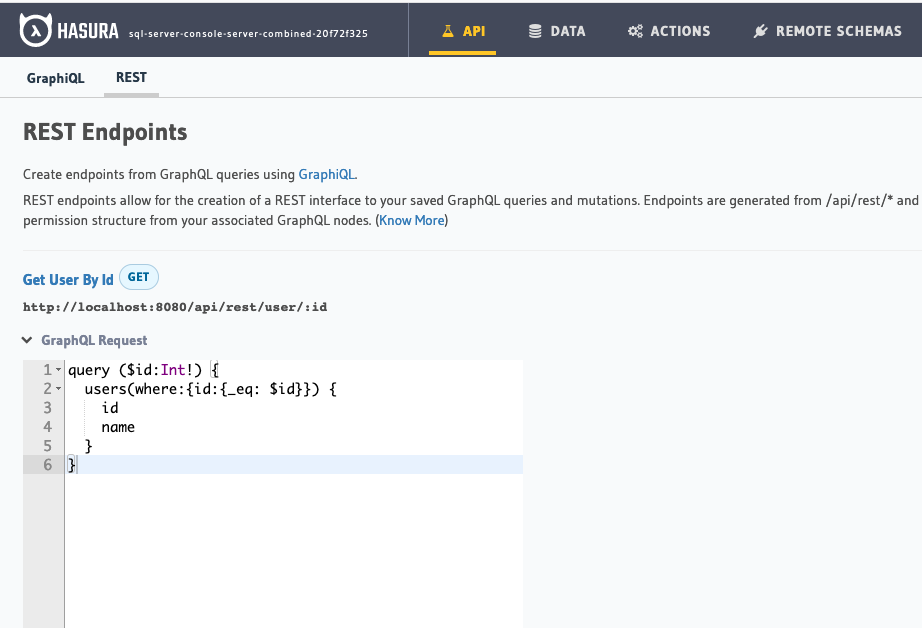
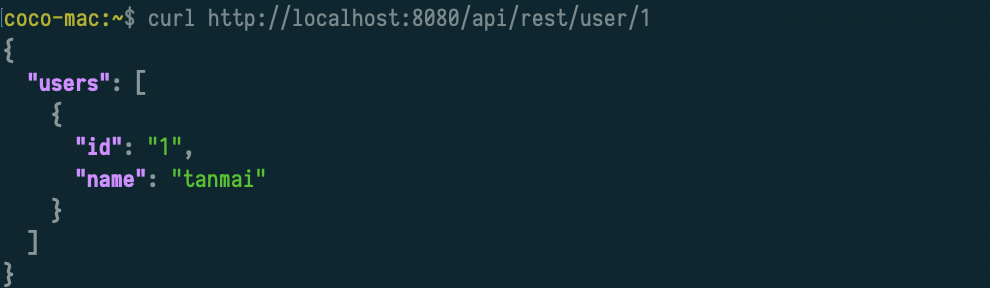
Hasura 2.0 allows users to create idiomatic REST endpoints based on GraphQL templates.
Create a REST endpoint from a GraphQL query templateMaking a REST API call to Hasura
This allows Hasura users to get all the benefits of GraphQL and REST - when the situation demands it. Hasura uses GraphQL as an intermediate representation and converts a RESTful request with its parameters to a parametrized GraphQL query and then executes it, with minimal overhead - query plans are cached after all!
This might seem similar to the idea of "persisted queries" but the key difference here is supporting idiomatic REST. This implies supporting error codes, caching headers, REST style verbs and parameterization (path params, URL parameters, JSON body etc.) and even OpenAPI/Swagger documentation for created endpoints.
3. Authorization engine
Hasura contains a sophisticated authorization engine - very similar to RLS style authorization in the database world.
This allows Hasura to extend its authorization policy abilities across data-sources without being restricted to the authorization features supported by particular databases only.
Hasura 2.0 features authorization on remote GraphQL services (your own GraphQL services or external GraphQL APIs you don't own): role-based schemas and preset-arguments.
Over time we plan to extend this authorization engine to create a generic and unified RLS style authorization layer across all data sources. With support for authorization on remote GraphQL services we've only just begun!
As data explodes, the need for declarative and "human observable" authorization becomes even more important.
Hasura 2.0 also features a policy inheritance system that allows composing fine-grained RLS or ABAC style policies on the fly.
4. High Availability & Distributed Ops
A GraphQL layer fronting multiple heterogeneous data sources is an ideal candidate for being a single point of failure. Hasura 1.x was already seamless to run in a scaled up fashion as a cluster of replicas and they would sync with each other automatically.
With Hasura 2.0 we wanted to ensure that we can start bringing in features that make running a Highly Available and "distributed" Hasura cluster along with its interaction with a set of upstream data sources as seamless and easy as possible.
This is no longer about just making Hasura scale up and work, but also to make its interaction with upstream sources fault-tolerant & scalable to prevent the single-point-of-failure problem.
Hasura 2.0 features a "maintenance mode" that allows for major Hasura version upgrades of itself and connected sources without any downtime to the GraphQL API and event delivery systems.
These are the features coming to Hasura soon:
Automated failover, circuit-breaking and retry logic customized to the upstream datasource's characteristics. Eg: The postgres primary replica is down!
Upstream source monitoring: Often when API performance slows down, it is hard to isolate whether the source of the problem is the API layer, or the upstream datasource. Eg: API requests are queuing up because the connection pool is saturated.
5. Metadata APIs
ICYMI, Hasura is a GraphQL server that doesn't require a build step! All of Hasura's configuration is entirely dynamic and API driven. This "metadata" API - which can be locked down in production depending on the use case - makes "change management" extremely convenient.
However, these metadata APIs are also extremely powerful because they allow Hasura users to "fetch" all of the configuration of a Hasura system on the fly.
This unlocks unprecedented metadata capabilities:
Creating a data-dictionary of what the underlying data models, their documentation, frequently used columns, recommended query patterns. We've already put together a starter kit for building your own data dictionary on top of Hasura here.
Observing security and authorization configuration and rules on the fly. Observing which authorization clauses are actually used by particular requests.
Creating community and org-specific base metadata configurations and sharing them to encourage common standards and best practices.
While some of the features above available aren't in this release of Hasura 2.0, expect a lot of metadata tooling to come your way!
Here's the one we're most excited about are working on right now:
Instant git push (or github webhook) to deploy database migrations and Hasura metadata changes to your staging and production Hasura instances.
Summary
Hasura 2.0 is here and along with the features that are a part of this release, it sets the technical foundation for engineers and contributors to innovate and ship rapidly for the coming months and years.
Join me at the Hasura 2.0 launch webinar to go over these features in action, learn more and ask questions!
And of course, in case you missed it, don't forget to register for the awesome (and free!) virtual GraphQL conference: https://graphql.asia/