The Architect’s Dilemma: Navigating the world of GraphQL
Remember not so long ago when GraphQL was the new kid on the block and people were rushing to adopt it? Lots of technologies come and go over the years but few end up getting their own foundation. (Much less a foundation that’s tied into the Linux foundation.)
I think a big part of the hype boils down to the fact that GraphQL done right is simply better than any possible equivalent of its REST counterpart. It’s not better because I want it to be better, or because I like how it works more. It’s better in the same way one might say MergeSort is better than BubbleSort.
When it comes to all the hard-tech metrics – primarily “how fast and efficient is it?” – there's a clear winner. Yet if you Google “Is GraphQL better than REST?” you’ll get mixed reviews. I’ve even seen some GraphQL hate going around and have heard my fair share of nightmare stories. When we say MergeSort is better, the metric we’re tending to use is time complexity. O(n log(n)) beats O(n^2) hands down. If we measure which sorting algorithm is better based on which is easier to implement, BubbleSort wins. There are also edge cases like when evaluating space complexity but let’s be real, nobody is arguing for BubbleSort in production.
The comparison between GraphQL and REST is similar in many regards. GraphQL – if implemented perfectly (hard to do), while properly solving all the known difficulties associated with implementing it elegantly (also hard to do) – is strictly better, if not for the simple fact that by reducing over-fetching and under-fetching we can literally reduce the amount of electricity our applications use while also speeding up our page-loads. The catch is precisely how hard this is to do. Unlike most sorting algorithms, you can’t implement GraphQL in an afternoon by hand. GraphQL was never intended to be a quick win.
I’m of the personal opinion that the companies likely to get GraphQL right have great communication structures. And I believe this is a consequence of Conway’s law, which states any organization that designs a system will produce a design whose structure is a copy of the organization's communication structure. Stealing a term from DDD circles, perhaps the most important discussions to be had around adopting GraphQL are the ones around your company's ubiquitous language. I’d guess the better an organization is at breaking down the social boundaries within their organization, the stronger their ubiquitous language becomes, and the more likely they are to have great success when adopting GraphQL.
There’s also absolutely no reason GraphQL and REST can’t play nicely together. If you can only pick one, I’d vote for GraphQL, but nobody says you can’t have both! So, too, can GraphQL and gRPC find ways to get along. The end motivation of adopting something like GraphQL oftentimes doesn’t center specifically around GraphQL itself, but rather around this idea that’s been starting to gain popularity in enterprise circles of creating supergraphs, which is something GraphQL can enable you to do. This is also one of the core problems that Hasura wants to help solve, by making it easy for Enterprise Architects to build supergraphs, which we’ll peek into a bit deeper at the end of this blog. Building these supergraphs isn't just a technical hurdle; it's an endeavor riddled with complexity, especially when it comes to correctly implementing GraphQL APIs. And trust me, this isn't just a theoretical problem.
Personal experience has taught me that building GraphQL APIs correctly is hard.
A few years before I discovered GraphQL, I was building a lot of REST API’s. My workflow at the time included tools like Postman, and I was a big fan of building things using the OpenAPI spec. As a Python nerd, that often meant building things using FastAPI. And when Python wasn’t a good fit, I would resort to things like Spring Boot.
I remember the first time I laid eyes on GraphQL: The promise was beautiful, and right away I went to work on a personal project to give things a try. I quickly realized that when it comes to building things with GraphQL, writing GraphQL resolvers by hand is simply downright painful. If you’re trying to build things with GraphQL and you’re handwriting all of your resolvers, then in nearly every case you’d likely be better off building things using REST.
I didn’t realize this until after a decent amount of time breaking myself out of the REST mindset (which is a whole chore on its own).
Writing GraphQL resolvers by hand is downright painful.
If you’re coming from a REST background, one of the first things you need to do when adopting GraphQL is forget all the rules you’ve been using for what’s likely the majority if not the entirety of your professional development career so you can learn a bunch of new rules that contradict most everything you’ve done or been taught before.
One of my favorite posts about GraphQL is the ironically titled, “How not to learn GraphQL.” While I was learning about GraphQL, at first, I found myself frequently falling victim to one of the biggest mistakes people make – trying to design GraphQL APIs the way the industry has spent the past 20 years teaching us to design APIs. (Who would’ve thought?)
I’ve seen highly talented people and top-tier teams fall victim to this, even with all the warnings out there. When you take a team that’s used to thinking in REST patterns, and you ask them to build something in GraphQL, I’d guess there’s a 90% chance they’re going to end up with a spaghetti-monster schema as developers are going to superimpose a REST-ful mindset onto the whole thing.
It’s unbelievably easy to read this or something like it and think, Oh, I’ll keep that in mind, note to self, don’t do that, then go and do precisely that anyways. (I’m guilty of having done it.)
Another pattern I’ve seen that often happens once people have managed to get over the mindset switch is they start building out a big pile of fancy new tooling from scratch. I’ve seen multiple roll-your-own attempts at things that automate building resolvers. Then you have to handle the N+1 problem in your resolvers and suddenly things get more complex. If you want subscriptions that’s an entirely different and equally complex conversation. Permissioning and handling authentication with GraphQL is another complexity because there’s a lot larger of an attack-vector when you expose your entire business domain as a graph. You need to think about pagination, and sorting, and by the end of it all, you truly are better off with REST.
If you still aren’t convinced, then the final complexity monster I’ll toss on top of it all is federation and handling multi-tenant applications. Or, if you want to push your engineers to the edge of insanity, you can try schema stitching by hand with cross-functional teams and watch the CI/CD build pipeline clog up for hours as each commit that makes a schema change kicks off your test suites. (Bonus points if some of the tests are flaky.)
I’d posit that herein lies the problem: The bottom line is that using GraphQL is one big complexity monster. If you use it right, it’s great, but good luck using it right on your own. It’s especially tricky because chances are the more “veteran” an engineering team you have, the more likely they are to fall into using the patterns they’ve spent their careers learning – and then they’ll make a big mess.
To adopt GraphQL correctly, you need to dedicate time and resources toward training your team on how to use GraphQL. There also should be an understanding from the top down that the decision to adopt GraphQL is a long-term strategic business decision. Hasura’s Co-Founder and CEO Tanmai Gopal recently spoke at GraphQL Conf about how GraphQL is a strategic choice that can set the business up for success, but it isn’t a tactical choice for quick wins.
Lots of people jumped onto the GraphQL bandwagon, and many got burned. That’s what happens when a technology is new and hot and nobody knows how to properly use it but everyone decides to try.
As humans, we tend not to want to get burned and quickly learn not to stick our hands into the fire. Lots of developers have been a part of big, ugly, messy GraphQL projects where their job title quickly changed from “Software Engineer” to “Firefighter.” That’s been the only experience many have had with GraphQL, and I can’t say I blame those individuals if they’ve sworn off ever trying GraphQL again. I try to avoid flame-breathing complexity monsters and would suspect most smart programmers and architects do, too. </rant>
Consuming a well-thought-out GraphQL API is great.
That’s the flip side. Once a GraphQL API is built, if it’s been built well with a good structure and a well-thought-out design, it’s a lovely experience to use. It’s mostly the building and maintenance that sucks – for the consumers, it adds tremendous value.
I’m certainly biased in thinking that Hasura is the best way to work with GraphQL, but even without Hasura, there are plenty of better ways than doing it yourself. I think the biggest key is not trying to do it yourself. There are lots of difficult problems to solve when you try to DIY GraphQL. And while it’s certainly a fun exercise, in the same way writing your own database might be, it’s not something I’d be planning to do for systems I wanted to send into production (unless I had the resources to dedicate for what will likely be a years-long engineering effort to get right).
We at Hasura have worked to refine the techniques we use to overcome the N+1 problem for a while, and if you want to reinvent them, here’s a potential starting point on how we did it. Good luck and have fun! 😅
For us at least, solving these problems is an entire product that requires the dedication of a small army of talented engineers. Trying to handle all of these things on your own in the background, while also working to solve the difficult and unique challenges specific to your product, is perhaps a bit silly.
Despite the above rant, there is a reason why GraphQL continues to get so much love and attention from developers and companies alike. When set up correctly, it’s a whole new world. It doesn’t even really have to be GraphQL if we’re being honest. It just needs to be something that does all the same things that GraphQL does, and is as easy to consume as GraphQL is, so we can build a supergraph.
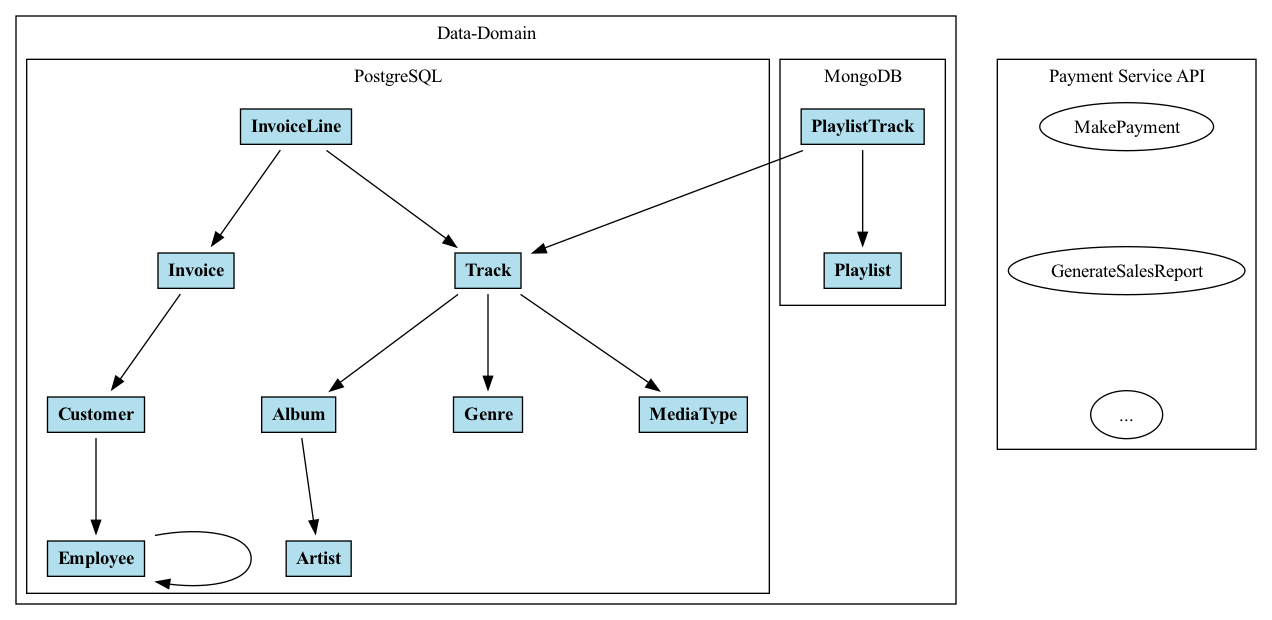
A supergraph is an architecture and operating model to build and scale multiple data domains as a single graph of composable entities and operations. It gives you the best of both worlds and can be viewed from the lens of taking a “monolithic microservices” approach. You can create an application that is logically monolithic, but physically distributed and micro.
Building a supergraph is typically a large undertaking. At Hasura we believe it should be as simple as declaratively defining your data model and tucking your custom business logic away as operations on the graph. To build a supergraph all you need to learn to do is to think like a node, and the rest should be after-thoughts. We think that the most important questions should be around the ubiquitous language your organization uses to describe your business domain, rather than the implementation details.
Thinking like a node – some practical examples
Graphs are foundational to most everything we do inside of a computer, and they are the best way to model real-world systems and processes we have.
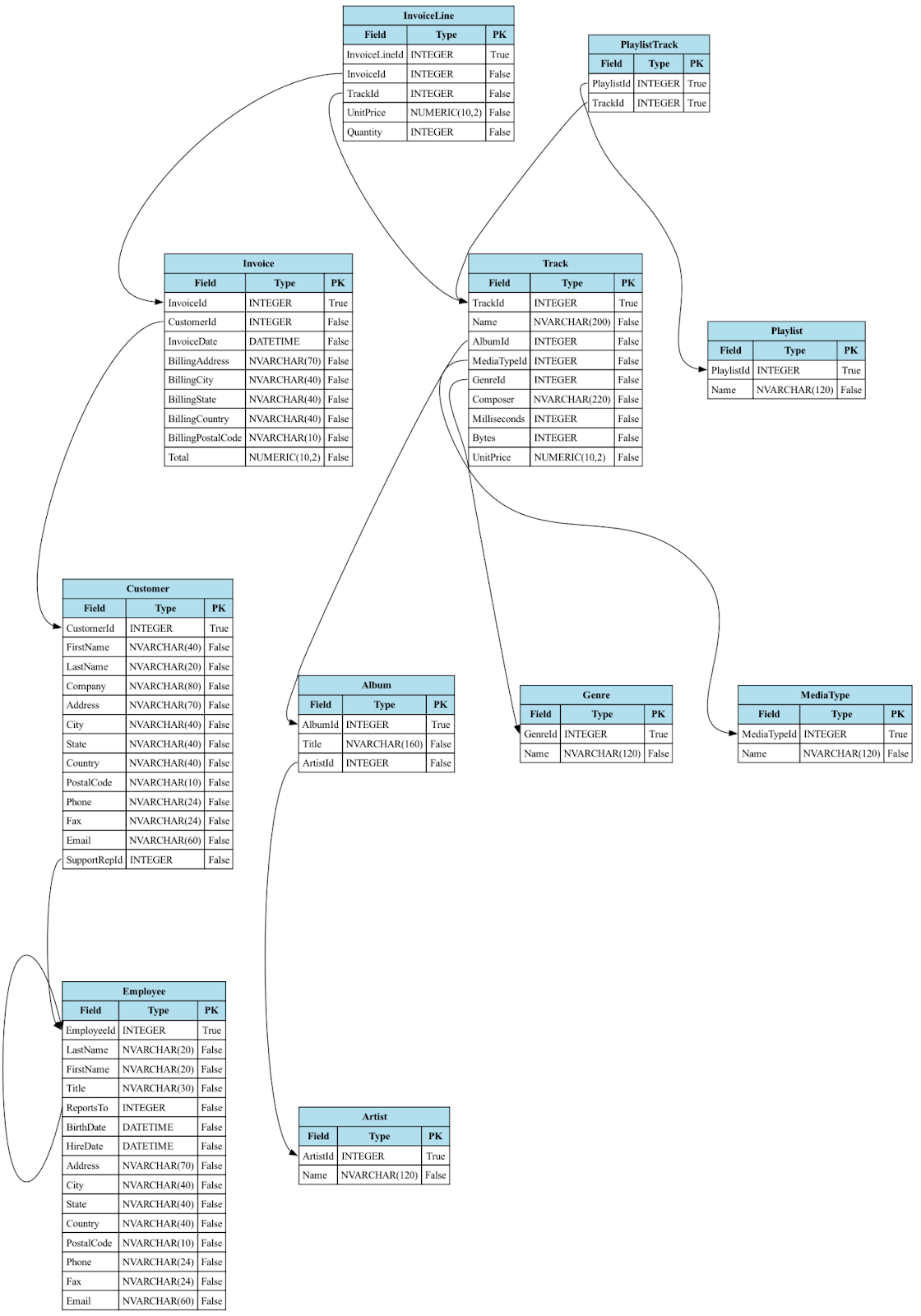
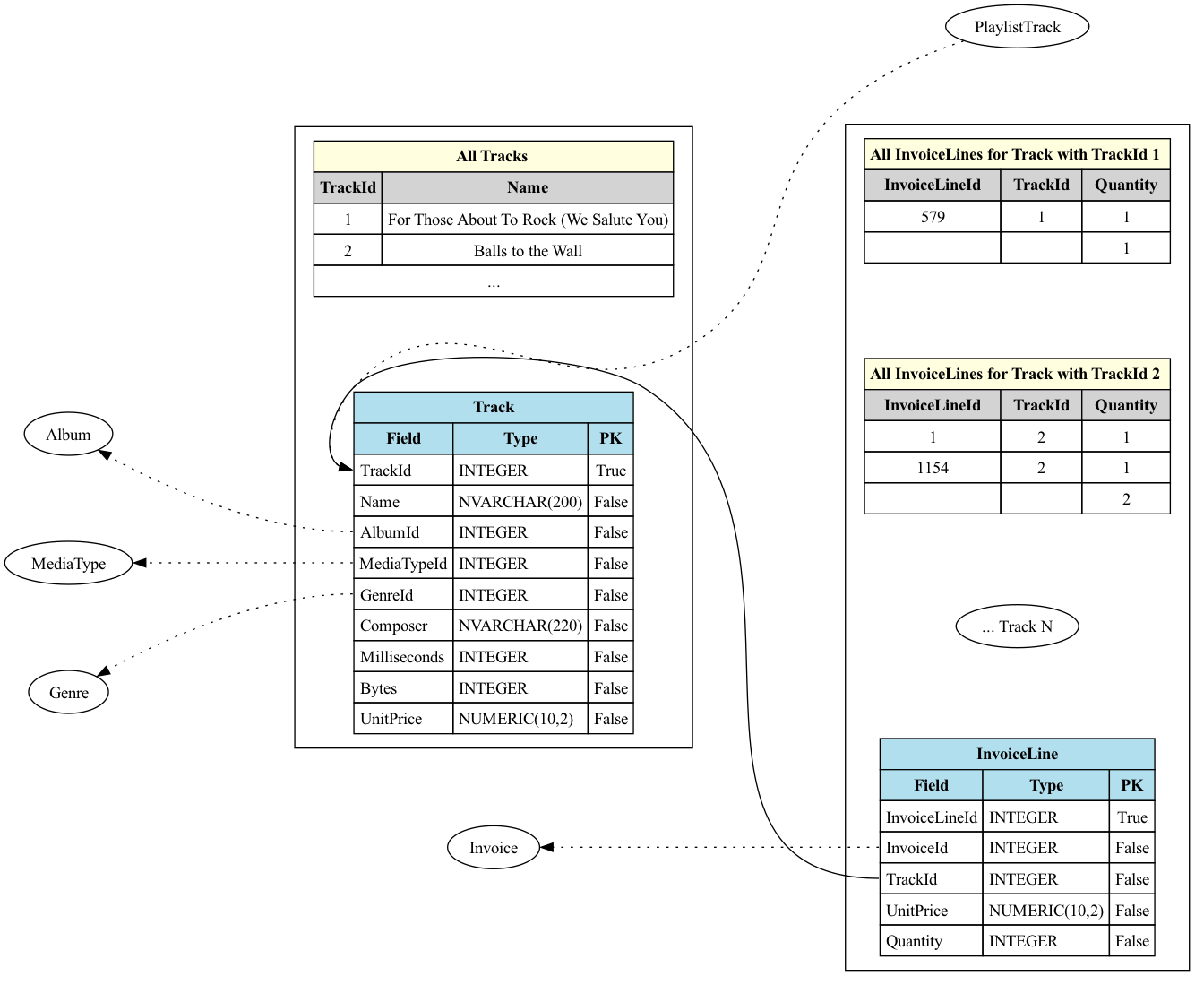
In these examples, we’ll examine the Chinook Music DB in the context of an organization's data domain. (You can download and play with this dataset if you want to from here). While we won’t go over the schema in detail, there are plenty of examples online that use it, and we’ve included an ERD diagram below. If you want to give Hasura a spin and follow along with the examples, simply deploy this onto Hasura Cloud to get started quickly. Feel free to skip ahead to the next section if this content feels familiar.
How does our data model define what we see, talk about, and understand in regards to our business? Let’s jump into a day in the life of our theoretical music store owner, by examining four common real-world questions we might encounter while running a music store.
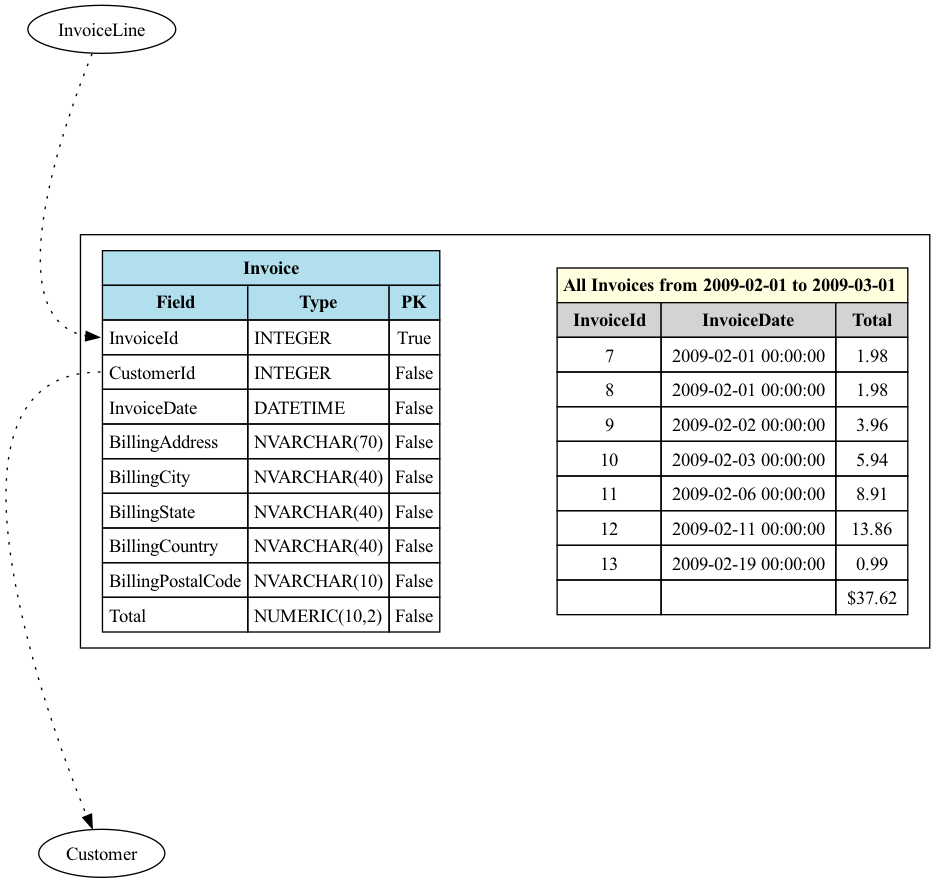
1. How much money did we make in February in 2009?
What this question is asking: What’s the sum total of all the Invoices that have an InvoiceDate that happened in February 2009?
When phrased that way, it’s easy to answer and think about. Start at the Invoice Entity, go into that entity's data, find all the invoices that occurred the month that we want, and sum up the total. It’s easy to answer that question even outside of the context of computer science. Not so long ago answering that question meant going to the Invoices filing cabinet, getting the folder for the month and year, and then pulling out each invoice and adding the totals together.
This is a simple query, as we aren’t traversing any relationships. The root of our question, which is the place to start looking for the answer, is at the Invoice.
Here’s how you could ask this if you were using Hasura:
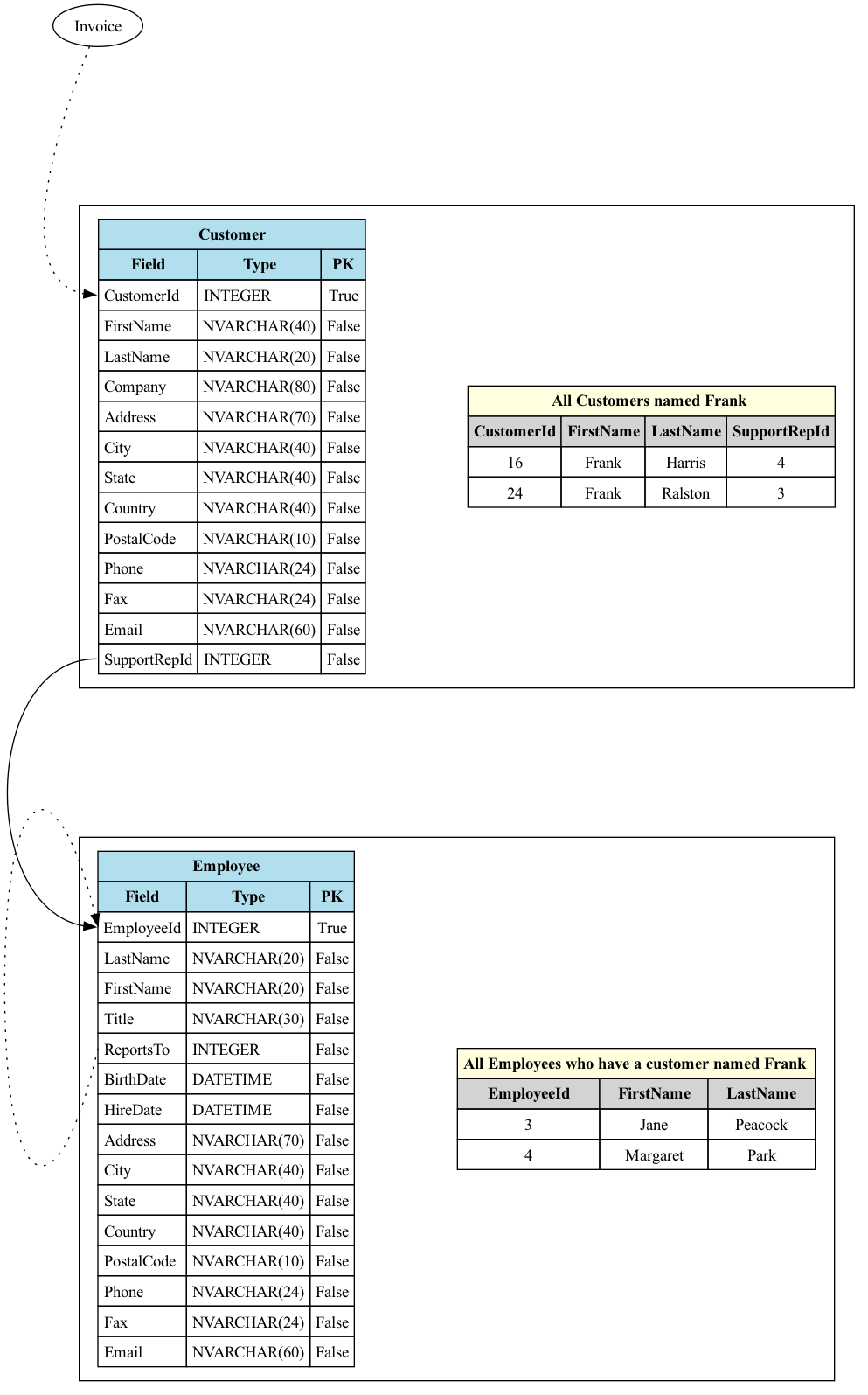
2. A customer named Frank called in and said he emailed support last week but hasn't heard back. Who's his rep and why haven’t they contacted him?
The most important part of knowing how to approach answering a question when data is on the graph is knowing where to start. Once you know how to “take a walk through your data-graph” you can easily determine the answer.
In this case, we start on the Customer node, and we need to find customers named Frank, from there we need to traverse the edge (or, relationship) between Customer and Employee.
The answer to the question depends on which Frank we’re talking about. Frank Harris’s support rep is Margaret Park, whereas Frank Ralston’s is Jane Peacock.
This one’s a bit of a trick question, the answer is that this question can’t be answered right now. If this question is important to the business domain, that isn’t represented in the data model. To answer it might mean asking things like which playlist has been listened to the most, or which playlist has the most upvotes.
As of right now, all we can say about a Playlist is its name, id, and what Tracks it has. For the current state of our database, this would require a discussion around what metrics we want to track and what we would need to alter the schema to track those. Cue a roadmap planning meeting.
4. Which Tracks are my best sellers?
Each time a track is sold, there will be an Invoice that contains that track in its InvoiceLines. (The InvoiceLine can be thought of as a line item on an itemized receipt.) Thus we can imagine this by thinking about starting at the Track node, and then for each Track we can walk across all the incoming edges from InvoiceLine and find every time the track has shown up as a line item for an Invoice. From there we sum the Quantity for that InvoiceLine, which will give us the total number of times each specific track has been purchased.
To answer this question, we’d then want to sort our results and determine which track is the most popular.
In this dataset, it seems that the best-selling tracks have many ties for first place, and the output of the top three for this query is:
{"data":{"answer":[{"TrackId":2,"Name":"Balls to the Wall","InvoiceLines_aggregate":{"aggregate":{"sum":{"Quantity":2}}}},{"TrackId":8,"Name":"Inject The Venom","InvoiceLines_aggregate":{"aggregate":{"sum":{"Quantity":2}}}},{"TrackId":9,"Name":"Snowballed","InvoiceLines_aggregate":{"aggregate":{"sum":{"Quantity":2}}}}]}}
From simple to supergraph, tying it all together.
I know what you might be thinking. How does a toy data model relate to building supergraphs? I think the real question is who said that this toy model couldn’t be a toy supergraph?
Physically, we can put data and compute wherever makes the most sense. (In today’s age, that could mean spilling compute or data onto the edge.) There’s no reason that the logical model we use to represent and talk about things can’t be split up into pieces that are more micro when we physically deploy them. The capability to efficiently perform remote joins across disparate data sources and API’s opens lots of doors for lots of people. We can design and talk about things as if we’re working on a monolith that yields high cohesion and easy governance, yet we can still get the benefits of microservices like loose coupling and scaling ownership. It’s especially compelling when we start to imagine all the different things we could plug into the supergraph.
Some of the data connectors I’ve been building that I’m excited about include connectors for databases like Qdrant, Turso, and DuckDB. The supergraph is super-flexible. It’s not too difficult to learn how to build a custom data connector for whatever you might want to connect to. This makes it easy to add whatever capabilities you need directly onto your supergraph and ultimately helps you ship faster.
While the path to mastering GraphQL and building a supergraph is riddled with complexities, the journey is well worth the effort. For organizations considering the leap, it's important to approach the design and implementation of a supergraph not as a quick fix but as a strategic choice. Embracing this technology with the right tools and mindset, like leveraging solutions such as Hasura, can significantly simplify the transition. This approach not only eases the technical challenges but also aligns with the long-term vision of efficient and scalable data management.
As we continue to innovate in the digital landscape, GraphQL, with its capacity to power supergraphs, stands as a testament to our evolving technological capabilities. Let's embrace this future, with all its challenges and opportunities, to build more robust, efficient, and interconnected systems.
I invite you, the reader, to share your experiences, thoughts, or questions about GraphQL and supergraphs. Let's foster a community of learning and exchange around these exciting technologies, and together, let's embrace the future of web development. Reach out to me at [email protected]