Data warehouses are used to store valuable enterprise data. Data APIs – both GraphQL and REST – are emerging as a tool to power frictionless and high-quality integrations between applications/services and data in enterprise data warehouses. In this article, we will talk about drivers behind the rise of data APIs on data warehouses, challenges with current approaches to building, operating, and scaling data APIs, and how Hasura is addressing those challenges for our customers.
Cloud data warehouses such as Snowflake, Google BigQuery, Amazon Redshift, etc. have seen a dramatic increase in adoption over the past few years. The maturity of the solutions themselves and the tooling (ETL) around them has improved a lot as well, making their adoption and usage a lot more tractable.
With the broader movement to become more data-driven as well as to get more from their data investments, enterprises are constantly looking for ways to bring data into more initiatives, decisions, and experiences. How can the data be shared more widely (but in a secure and compliant way) to enable more internal and external stakeholders to make better decisions? How can data be incorporated into applications to build more delightful user experiences – for customers, partners, and employees.
Top use cases for data warehouse integration
Let's take a look at the top 3 data-first use cases
Data-as-a-product to other teams in the org
Teams that own data want to publish it to other teams in their organization or externally to other partners. Increasingly they want to think of their data as a product.
Example: Buyers with very high returns because of fraudulent reasons
Embedded data features in existing products (apps or services)
End users of digital products are increasingly expecting their product experience to be "smarter". For offline products, users benefit from a digital management and analytics experience. At the same time, product and business teams know that intelligent features can drive increased stickiness, retention and usage of their products.
Example: Show "predicted" end of month bills on a consumption-based billing service. Or, surface a customer 360 type of view for internal marketing and sales teams by aggregating data across multiple tables and data sources.
Integrations to enrich data in other business tools
Enterprise tools and SaaS products (like Marketo, Salesforce, etc.) that are the operational foundation for the business can become a lot more valuable when they are integrated with more data and context, which usually resides in a data warehouse.
Example: Visualising data using Google's data studio.
Data warehouses themselves are evolving to keep up with the demand for extracting more value from data. For example, Google Cloud has been investing heavily in BigQuery ML that allows teams to leverage their existing SQL knowledge to easily create and use ML models.
The desire for integrating transactional and analytical use-cases has led to Snowflake announcing Snowflake Unistore – their unified platform that brings product use-cases to the core CDW value-proposition that they are known for. However, customers are still looking for better ways to integrate their warehouse data into these use cases.
Many are coming to the conclusion that APIs (and more specifically GraphQL APIs) are the most flexible, secure, and performant way to enable these use cases on their data warehouses.
Let’s look at why data APIs are well-positioned to address these use cases.
GraphQL Data APIs are the solution to data warehouse integration
Before we dive into why APIs are the best way to power this new breed of integration needs, let's look at how organizations primarily access data in their warehouses today, and why/how those current approaches fall short for these newer use cases.
The 2 primary ways of connecting to data warehouses is either via JDBC / ODBC connectors in 3rd party applications or by writing SQL (or derivative) queries directly against the data. Both of these approaches are great for traditional analytics and visualization needs. For example visualizing data in a BI or visualization tools like Tableau or Looker; or querying and analyzing data for analytics and reporting use cases.
But this type of direct access to data doesn’t work for these new integration use cases because it tightly couples the consumption layer with the data layer in a way that is hard to maintain, operate, and secure. A data API access layer becomes necessary. Let’s look a few scenarios
Multiple applications/services need access to the same data
Multiple tenants connected to the same database makes it hard to evolve the data and schema of the database, or to provide performance QoS or tiers to different consumers. Building an API layer between the producer and consumer allows decoupling, and provides an intermediate layer that can absorb those changes in a more elegant way.
Enforcing authentication & authorization without an API is painful
IAM in data warehouses are geared towards providing secure access to individuals and analysts, but are not ideal for application/service integrations.Sharing database credentials with multiple applications becomes a management headache and a potential security nightmare. Applications probably have a centralized authentication mechanism that should be leveraged, but databases typically don't integrate with that directly.
Furthermore, entitlements (especially fine-grained policies) that govern access to certain rows or columns of data based on properties of the end-user or the application are hard to manage and enforce in the data warehouses because they don't provide those capabilities or because maintaining those policies in the data warehouse’s proprietary setup makes it hard to scale reviewing & auditing these security policies.
GraphQL APIs allow data consumers to fetch just the data they need
Direct access is fine when the consumer is trying to pull data that lives in a single table / view. But, can be inefficient because of multiple request roundtrips if you need to pull and join data from multiple tables/views/databases, etc. This inefficiency can have a non-trivial cost and performance impact depending on level of overfetching and query volume. REST APIs can also suffer from this limitation. GraphQL was created to solve exactly this problem for transactional workloads, and is gaining popularity for addressing this issue for analytical / OLAP data sources as well.
All these reasons make APIs, and more specifically GraphQL APIs, a more elegant way to address the data integration use cases for data warehouses.
Building APIs the traditional way can be slow and expensive
While GraphQL/REST APIs are great fit for these data integration use cases, building, scaling, and operating APIs can be a time-consuming task, which can in turn cause organizations to shy away from API-driven approach to data warehouse integrations.
Here are just a few of the many things that add time and effort to build and operate APIs.
Creating a single API end point requires developer to build and maintain these:
Boilerplate code for CRUD API
Mapping client types and schema
Baking authentication and authorization is tedious and risky
Validation and error checking code in the API layer
Building GraphQL API brings additional costs. Developers need to write and maintain resolvers to map the GraphQL query to the underlying SQL queries. The effort to write resolvers increases significantly with the richness and complexity of the GraphQL queries, for e.g. if you have filtering, aggregations, complex and/or logic, etc. Furthermore, making sure that the resolvers are written in a way that the resulting GraphQL query is performant takes more planning and optimization.
Operating APIs efficiently brings its own set of challenges. Making sure that the APIs are performant, reliable, and can scale smoothly with load can become a heavy lift, especially as this expertise is not typical in teams managing the central data warehouse. Updating the API to keep up with changes at the database level needs some discipline as well to make sure the consumers have a smooth experience.
Hasura completely eliminates these challenges with traditional API creation and operation workflows. It allows organizations to become API-driven, but without all the effort that goes into API creation, scaling, security, and operations.
Building and scaling GraphQL and REST APIs faster with Hasura
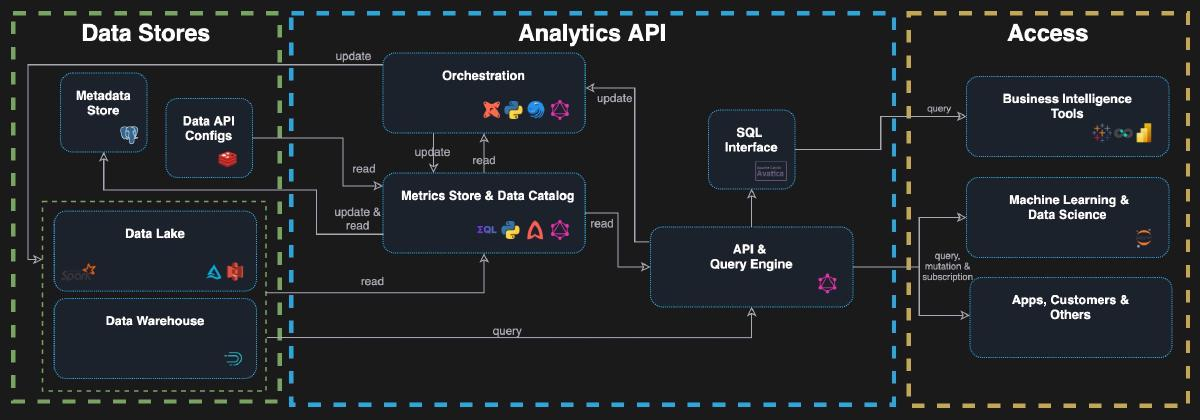
Hasura provides a GraphQL API over transactional sources of data, and over the last year we've been seeing first-hand how developers and teams increasingly need to access data from a data warehouse.
Hasura allows rapid creation of GraphQL APIs (or REST) by just configuring the data sources and the mapping of underlying data models into API models, and then Hasura provides an API that has joining, filtering, pagination & aggregation capabilities built-in. Hasura also has a session-aware caching layer that makes integrations with realtime applications easier with OLAP and CDW systems.
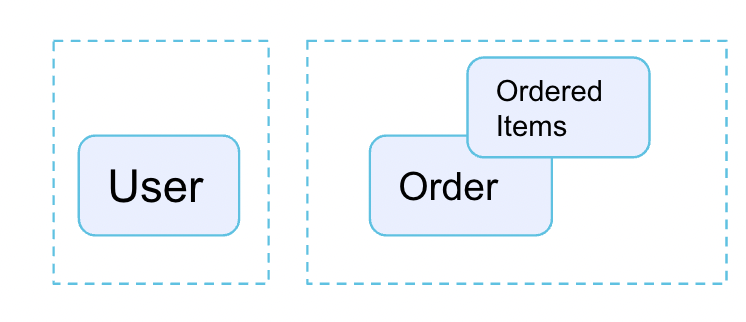
Imagine the following the eCommerce schema in a Data Warehouse
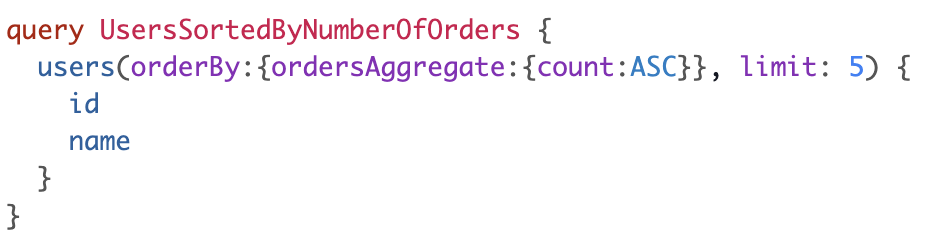
An API call that fetches users based on number of orders they've made, is a normal query to make, but is challenging to represent as a flexible REST API call:
An API call that fetches orders based on what region the users are in, without fetching unnecessary user data:
Streaming Subscriptions
If you have a large amount of data, or "fast moving" data in Postgres, Hasura now allows you to instantly create an API for clients to fetch that data as a continuous stream. This API can be safely exposed to internal or external HTTP clients.
For example, in the users placing orders scenario, during holiday season, there would be plenty of orders coming in every second. We can make use of streaming subscriptions to async load the data on the UI and not bombard the client to fetch orders which are still pending payments.
Hasura is highly optimized for performance, scalability and reliability. Hasura also provides caching and query optimization services, which further help improve performance.
Caching
Now, some queries are more frequently accessed than others. Typically, there could be latency and slow response times due to the size of the response, location of the server (in a distributed multi-region app), number of concurrent API calls.
Hasura has metadata about the data models across data sources, and the authorization rules at the application level. This helps Hasura to provide end to end application caching.
High performance GraphQL to SQL Engine
Internally Hasura parses a GraphQL query, gets an internal representation of the GraphQL AST. This is then converted to a SQL AST and with necessary transformations and variables the final SQL is formed.
GraphQL Parser -> GraphQL AST -> SQL AST -> SQL
This compiler based approach allows Hasura to form a single SQL query for a GraphQL query of any depth.
GraphQL helps make one API call to fetch related data and a precise subset of data, instead of making multiple REST API calls that might return potentially redundant data.
This has a cost implication because only the right subset of data is fetched and a single query is executed to fetch related pieces of data (as opposed to multiple REST API calls that fetch more data than is necessary)
Security
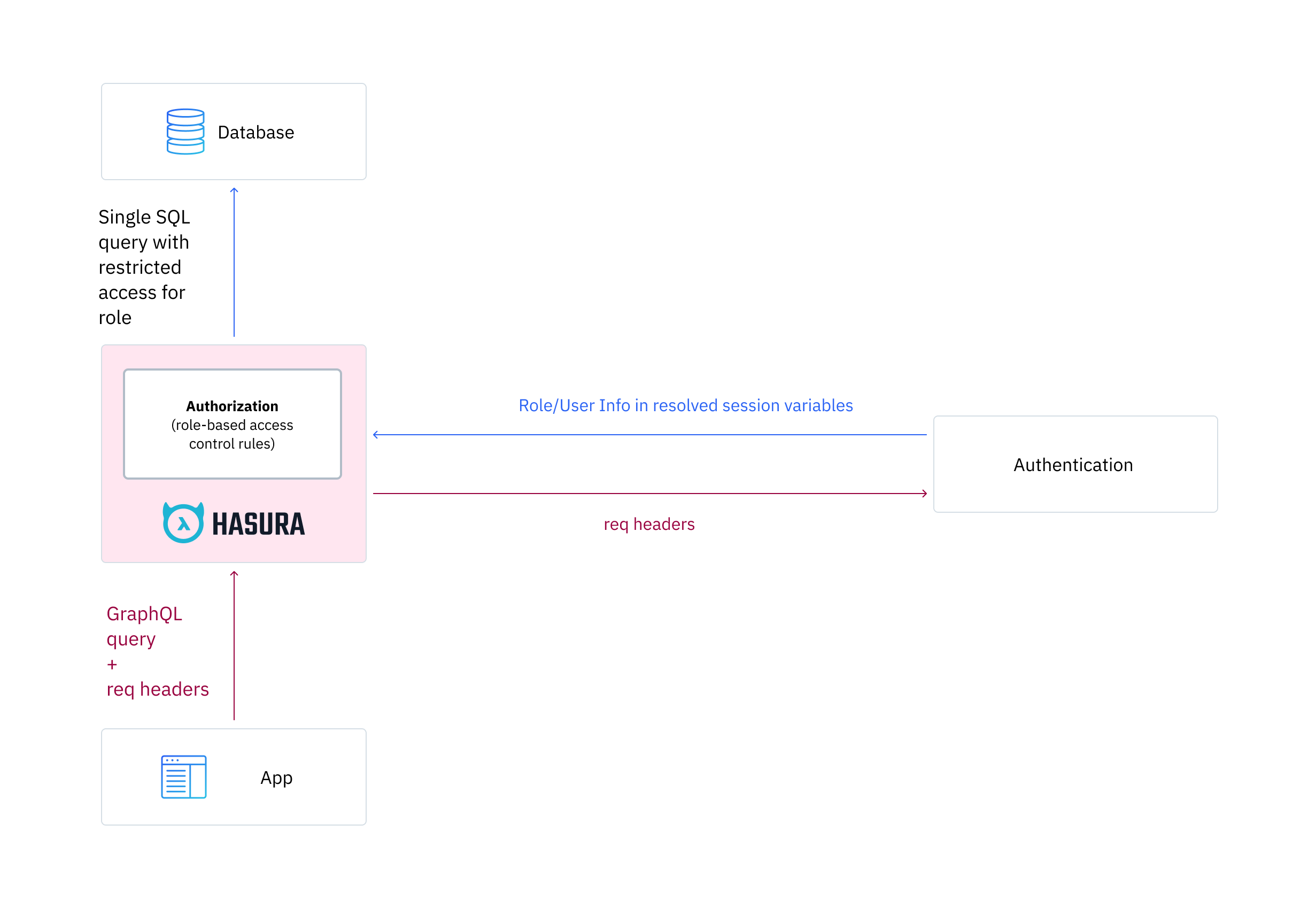
Hasura has a fine-grained authorization engine that allows creating policies to restrict access to only particular elements of the data based on the session information in an API call.
Hasura Authorization and Authentication
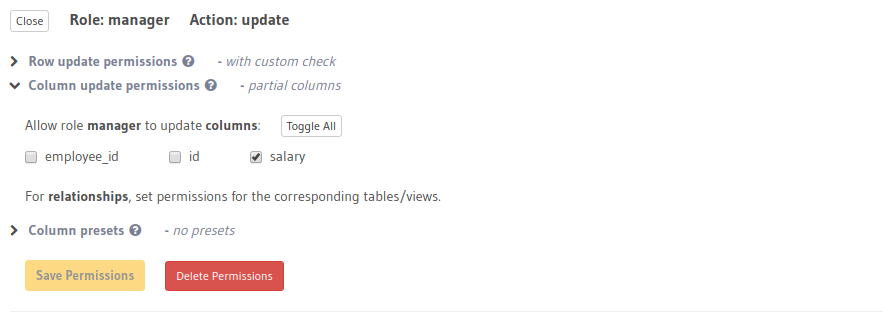
Row level and column level permissions
Hasura supports role-based access control system. Access control rules can be applied to all the CRUD operations (Create, Read, Update and Delete). Some operations can be completely restricted to not allow the user perform the operation.
Row Level PermissionsColumn Level Permissions
The rules can be setup easily using Hasura Console, where you define a role and setup rules for access.
For example, for row level permissions, we can set up filters like
{"user_id":{"_eq":"X-Hasura-User-Id"}}
The above rule is equivalent to saying: allow this request to execute on the current row if the value of the user_id column equals the value of the session variable X-Hasura-User-Id.
Get started with instant API on your data warehouse
Hasura supports BigQuery, Snowflake, Amazon Athena, and Postgres flavors like AlloyDB and Hydra (geared for OLAP). If you and your team are looking at exposing data warehouse data over an API, Hasura can significantly reduce the time and effort to do so, in turn freeing up your developers to do other high-value work with direct ties to business outcomes.
To get started follow our guides to get instant APIs on Snowflake or BigQuery.
Or, reach out to the Hasura team for a custom demo to get all your questions answered about how Hasura can accelerate your path to APIs on data warehouses.