This has been something we’ve been working on since January this year. We’ve used the core Hasura GraphQL engine as a base, made sure that we’re able to provide Hasura as a cloud offering where you don’t think about the number of instances, cores, memory, concurrent users, high-availability, realtime monitoring, caching, tracing, rate-limiting and other things that are infrastructure concerns and not really things you want to spend time on.
Drake says, you ought to focus on building things, not running them!
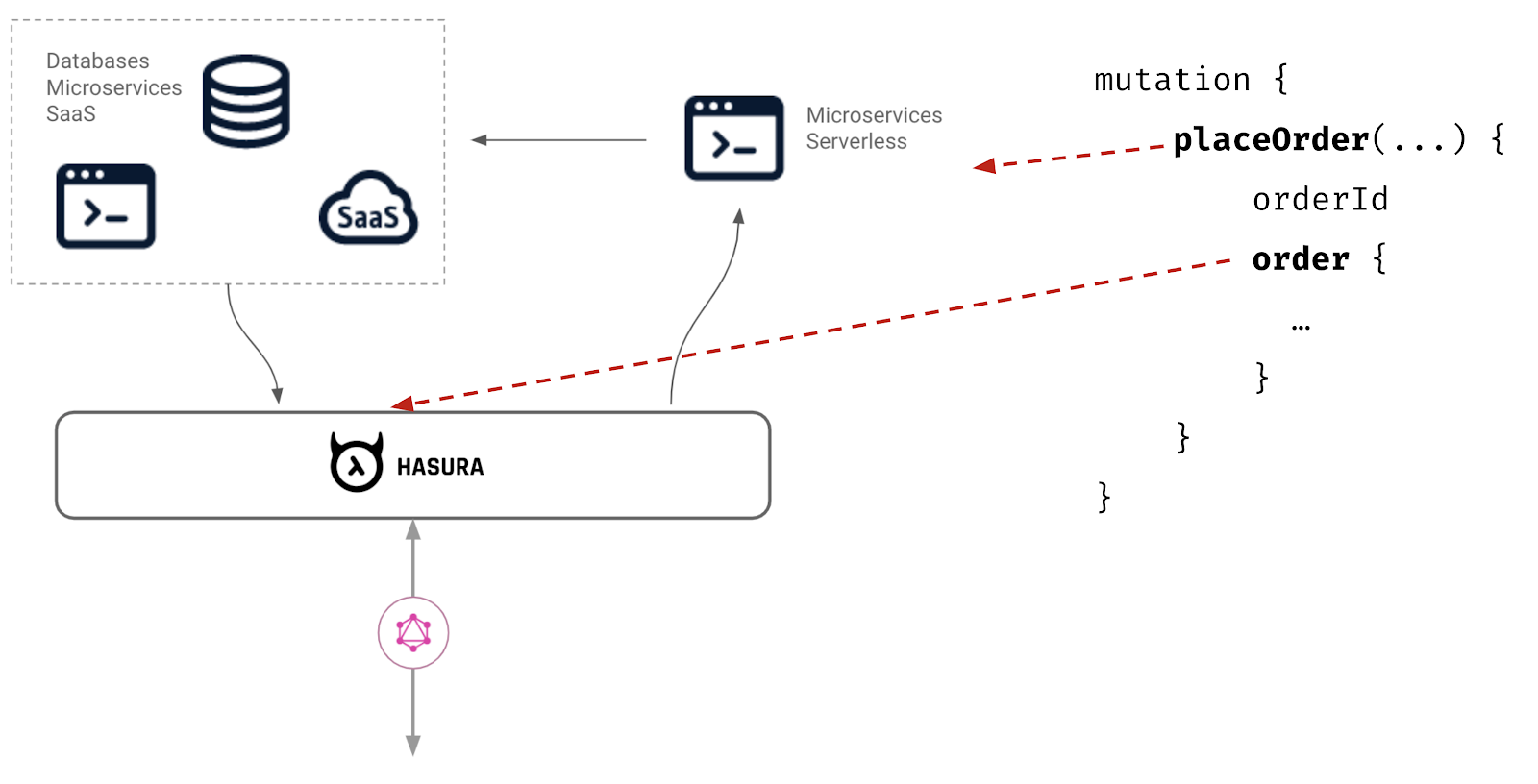
For those new to Hasura, the Hasura GraphQL engine is an open-source service that uses a metadata engine to connect to new or existing data-sources (like Postgres, REST APIs, GraphQL APIs etc) and provide a managed and secure GraphQL endpoint that internal or external applications can connect to.
We want to make GraphQL invisible to API developers, and give API consumers a GraphQL API they love. The logical next step for us, was to make Hasura GraphQL engine available as a managed cloud service.
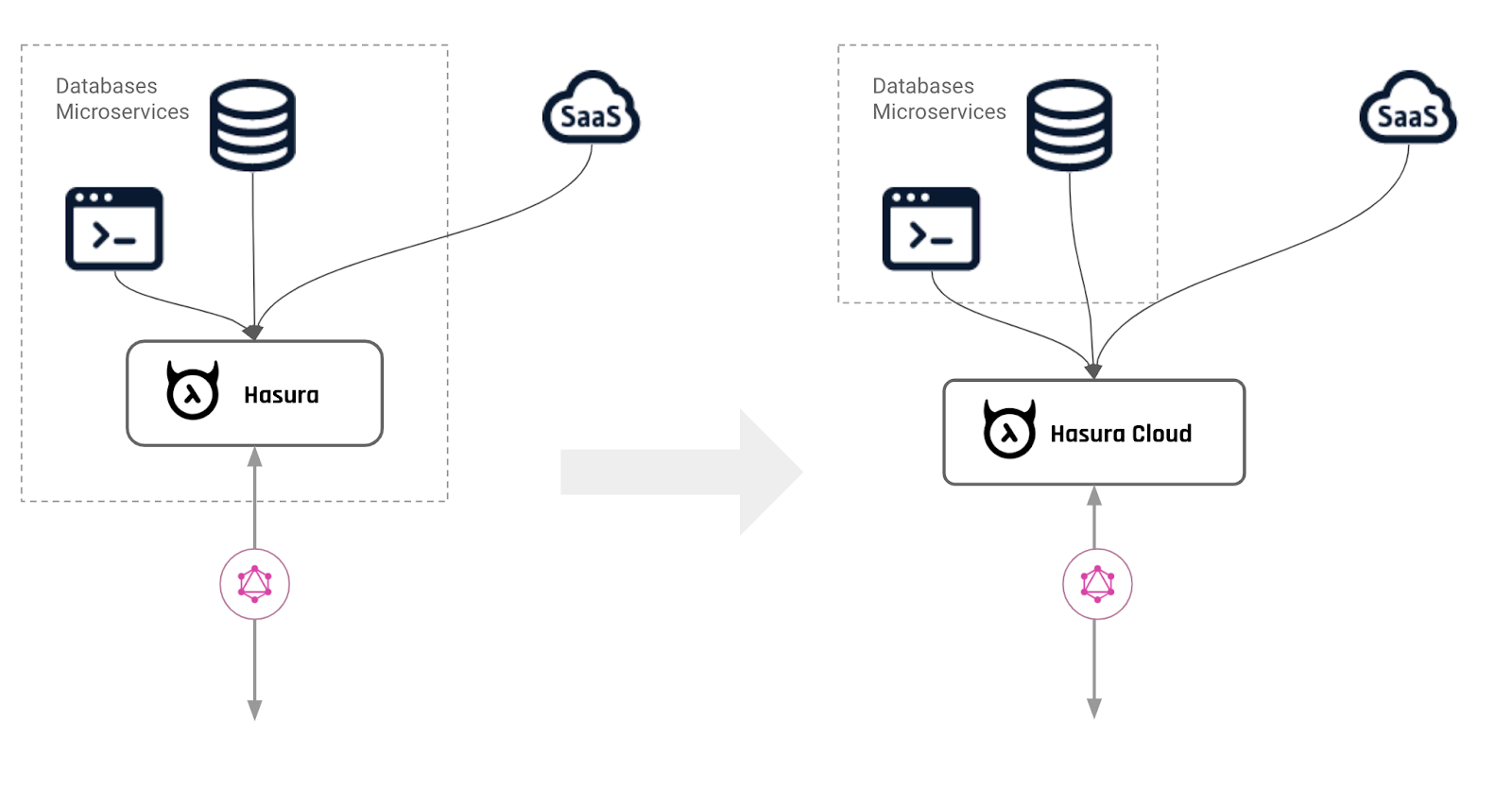
From hosting and running Hasura yourself, to Hasura Cloud.
Auto-scale and serverless GraphQL
Each instance of Hasura is a heavily multi-threaded server that exploits shared memory within the instance to aggressively optimise handling GraphQL queries at runtime. If you’re running Hasura yourself, you can first scale a few Hasura instances vertically and then horizontally. At what CPU or memory threshold should you scale up or scale out? Well….it depends. Hasura’s footprint is different for different kinds of workloads.
If you’re running on Hasura Cloud, you don’t need to care! Hasura cloud doesn’t ask you to think about the number of instances, cores, memory, thresholds etc. Hook up your database and other services, and it just works.
You can keep increasing your number of concurrent users and the number of API calls and Hasura Cloud will figure out how to make sure that your GraphQL API just keeps on giving. 🤓
Ultimately, your API performance will bottleneck on your database. Hasura Cloud ships with monitoring and tracing features that help you understand database query performance and give you insight into what to do. Most DBaaS vendors make it really easy to scale your postgres vertically, or add read replicas to your primary Postgres server.
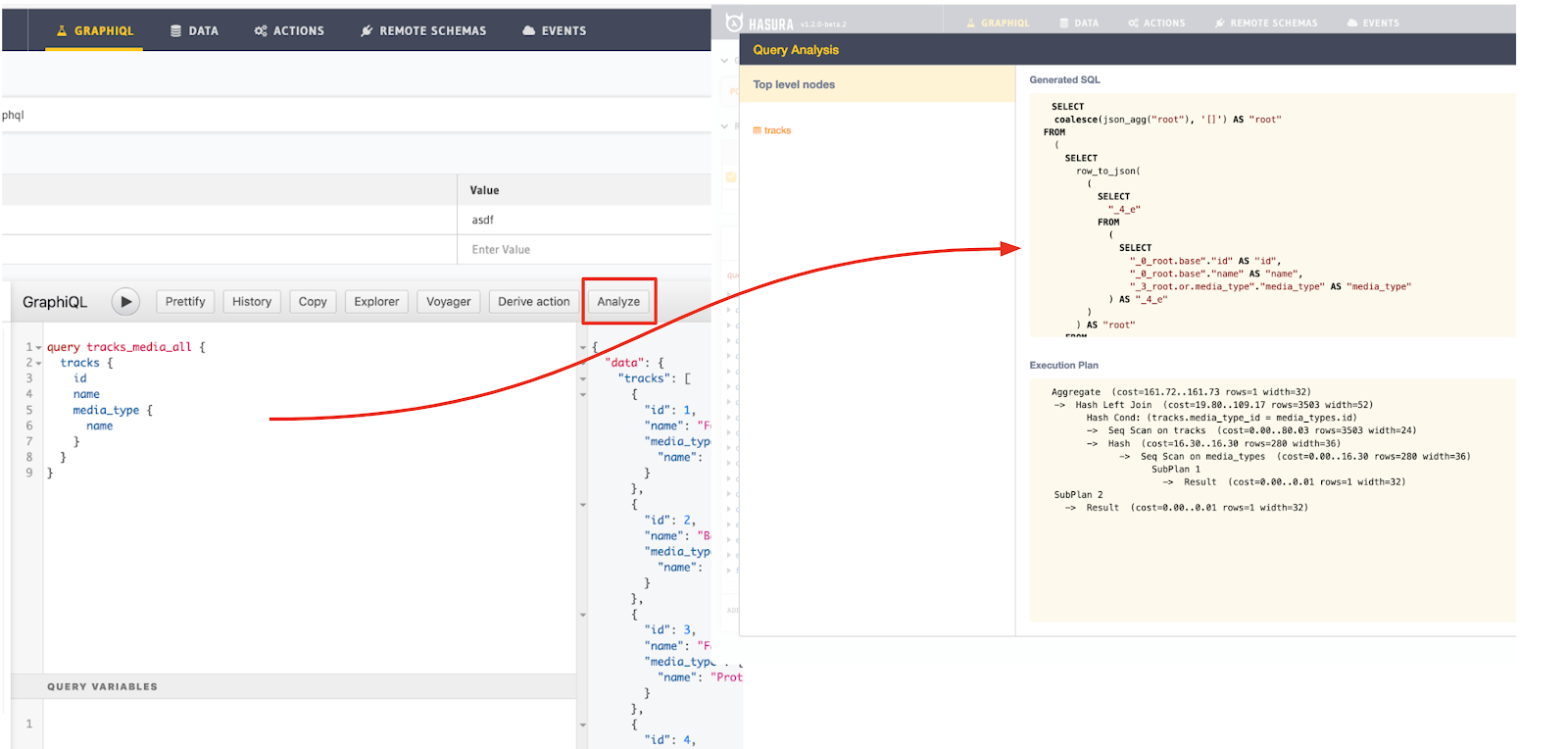
Use SQL query analysis built in to Hasura to improve your database performance
Incidentally, if your upstream services are also written in a stateless way, especially if you’re using Actions with serverless functions or auto-scaling containers, then these will get automatically scaled by the cloud vendor too. 🤘
Hasura Cloud supports data caching by adding an @cached directive to your queries
GraphQL query caching
Hasura GraphQL Engine already offers query caching where the internal representation of the fully qualified GraphQL AST is cached, so that it’s plan need not be computed again. For example, when a GraphQL query with variables and session variables comes in, the generated SQL is already prepared as a statement and exact end-user session based variables and the dynamic API variables (query variables) are zoomed through to the database. This makes Hasura’s queries extremely fast.
GraphQL data (response) caching
Hasura cloud goes a step further and adds support for data caching. We’ve taken the first step, and there’s lots more to do, but here’s how Hasura cloud thinks about caching which is something we API developers usually build inside our app server.
There are many purposes to application level caching, but the most common requirement is usually to reduce the load on the underlying data-source.
Caching authenticated API calls automatically is very hard/painful, because of 2 main problems:
Knowing what to cache given an incoming API call made by a specific end-user:
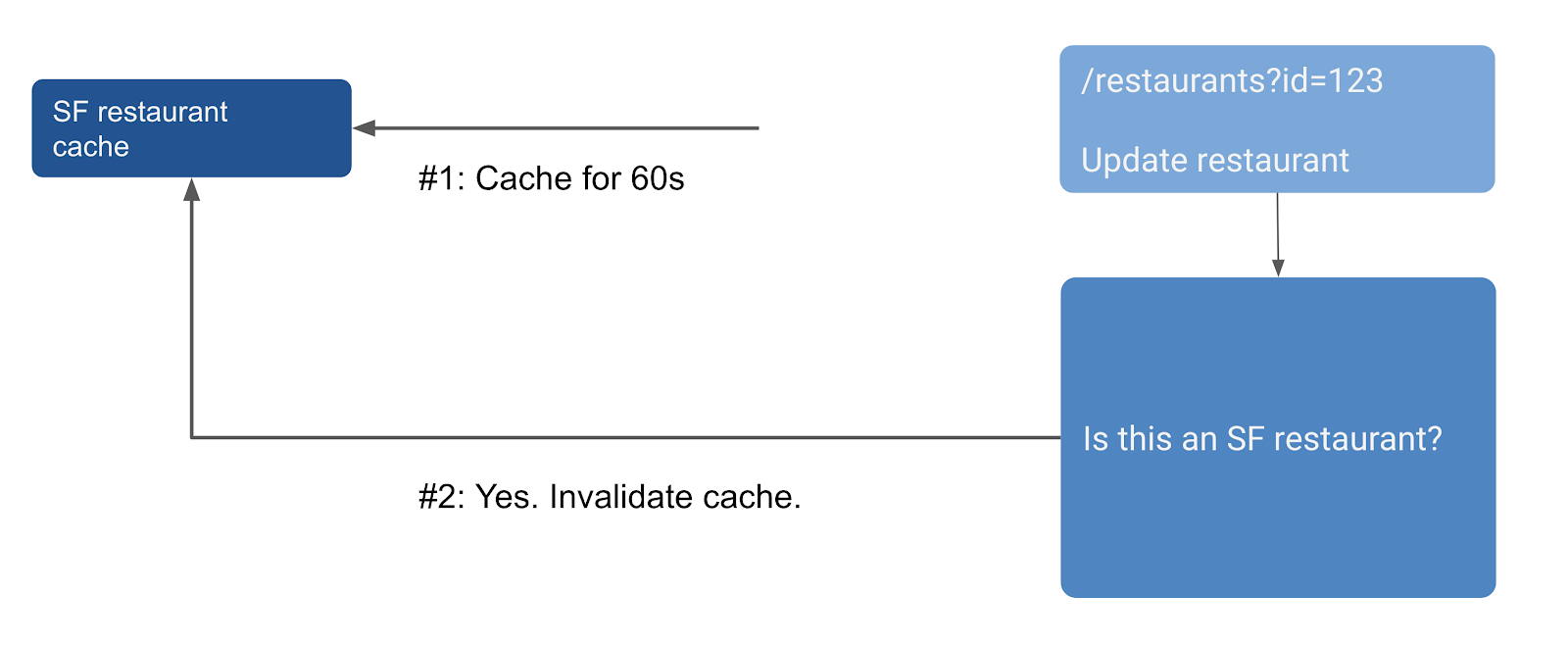
If the API call doesn’t depend on a property of the user, then it is straightforward to say that all API calls will fetch the same data. The cached data can be retrieved from a cache and sent to the API consumers.
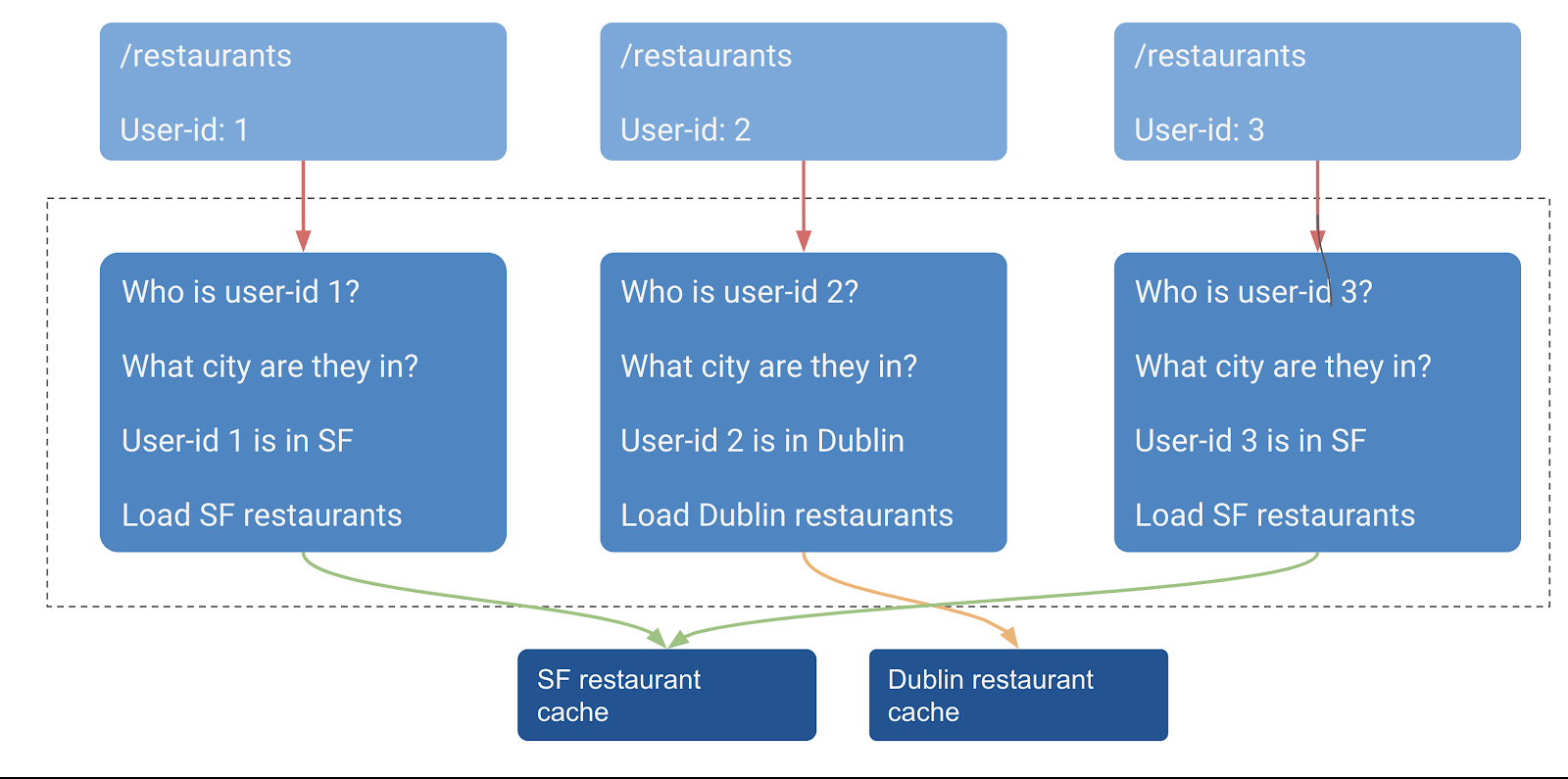
If the API call depends on the property of the user, then we need to know if because of the identity of a user, they would end up fetching the same data that some other user has already cached. Let’s say everyone in the same area fetches the same list of restaurants on their app. This is a dynamic rule, because users can change their current areas and hence which cached entities are fetched depend on who is making the API call at that point.
There are 2 hard problems in computer science: cache invalidation, naming things, and off-by-1 errors.
When users make API calls that perform writes, busting the cache that the same API server or that other instances of the API server are using, is hard.
This is a version of the materialized-view-dynamic-update problem, but at the application level which is potentially fetching from multiple data sources. This is typically why most application server developers using something like Redis typically set a TTL using information from #1 (Knowing what to cache) and deal with the temporary staleness on the UI side.
Because Hasura has enough information about the data models across data sources, and the authorization rules at the application level Hasura has enough information to offer end to end application caching by solving all the problems above.
Today, we’ve launched support for caching authenticated GraphQL API calls that works for shared data (problem 1). How do we handle cache invalidation today? We use a TTL configuration so that state data is refreshed within a time interval.
The good news is that since API writes and workflows pass through Hasura (GraphQL mutations), Hasura can eventually handle automatic cache invalidation too!
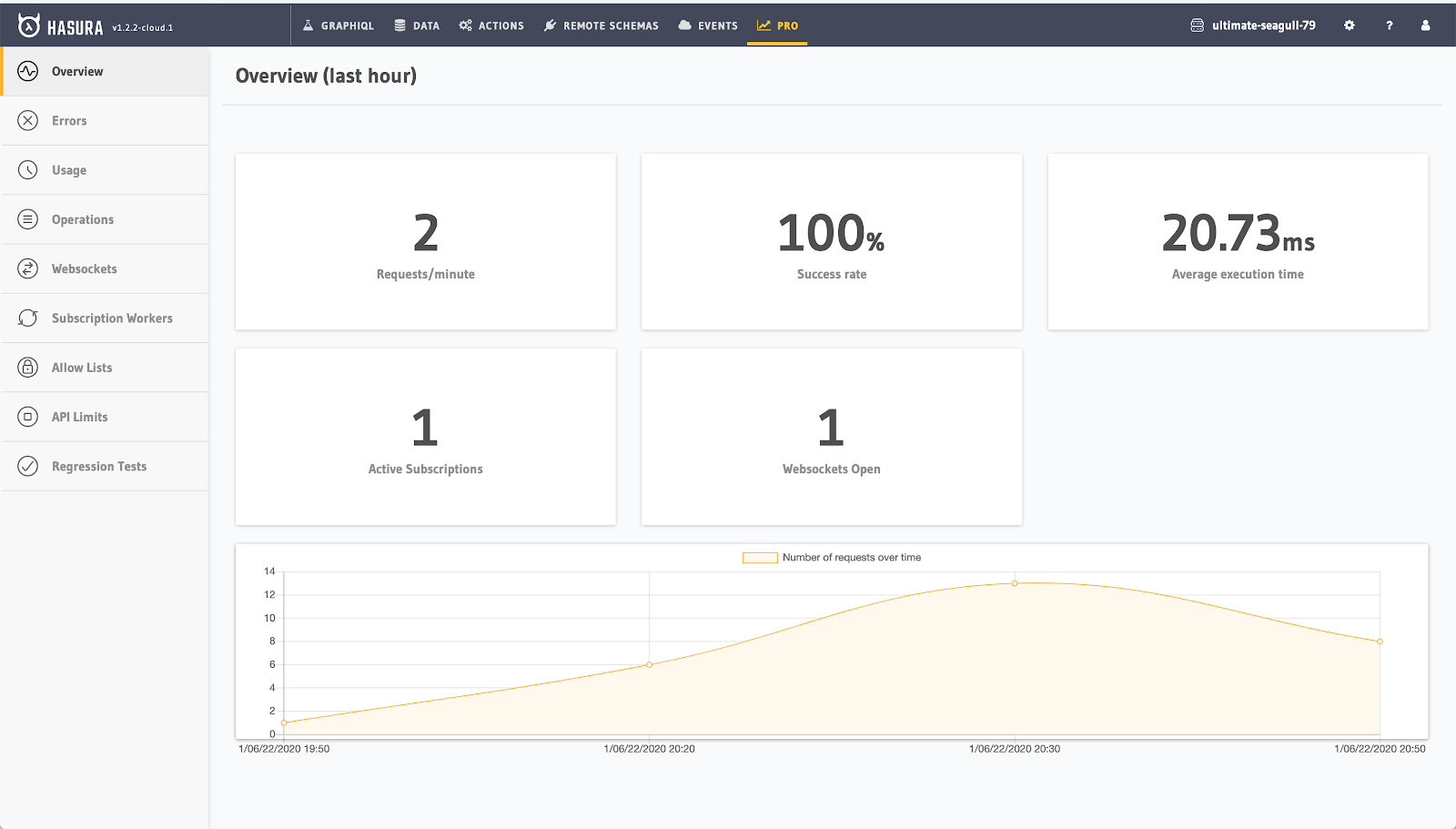
GraphQL Monitoring
Apart from monitoring successes errors (and partial errors) from GraphQL API calls and their responses, Hasura Cloud also adds great support for monitoring websocket connections and subscriptions!
GraphQL Tracing with OpenTracing
Strange things happen in production and it’s hard to know where the problems came from. Tracing requests and responses, end to end and through the various components in your system in production is critical.
Hasura acts as a fulcrum and coordinating point between your GraphQL API consumer, your data models and your custom business logic or external services that you bring in via HTTP (GraphQL Remote Schemas or REST API Actions or Event Triggers).
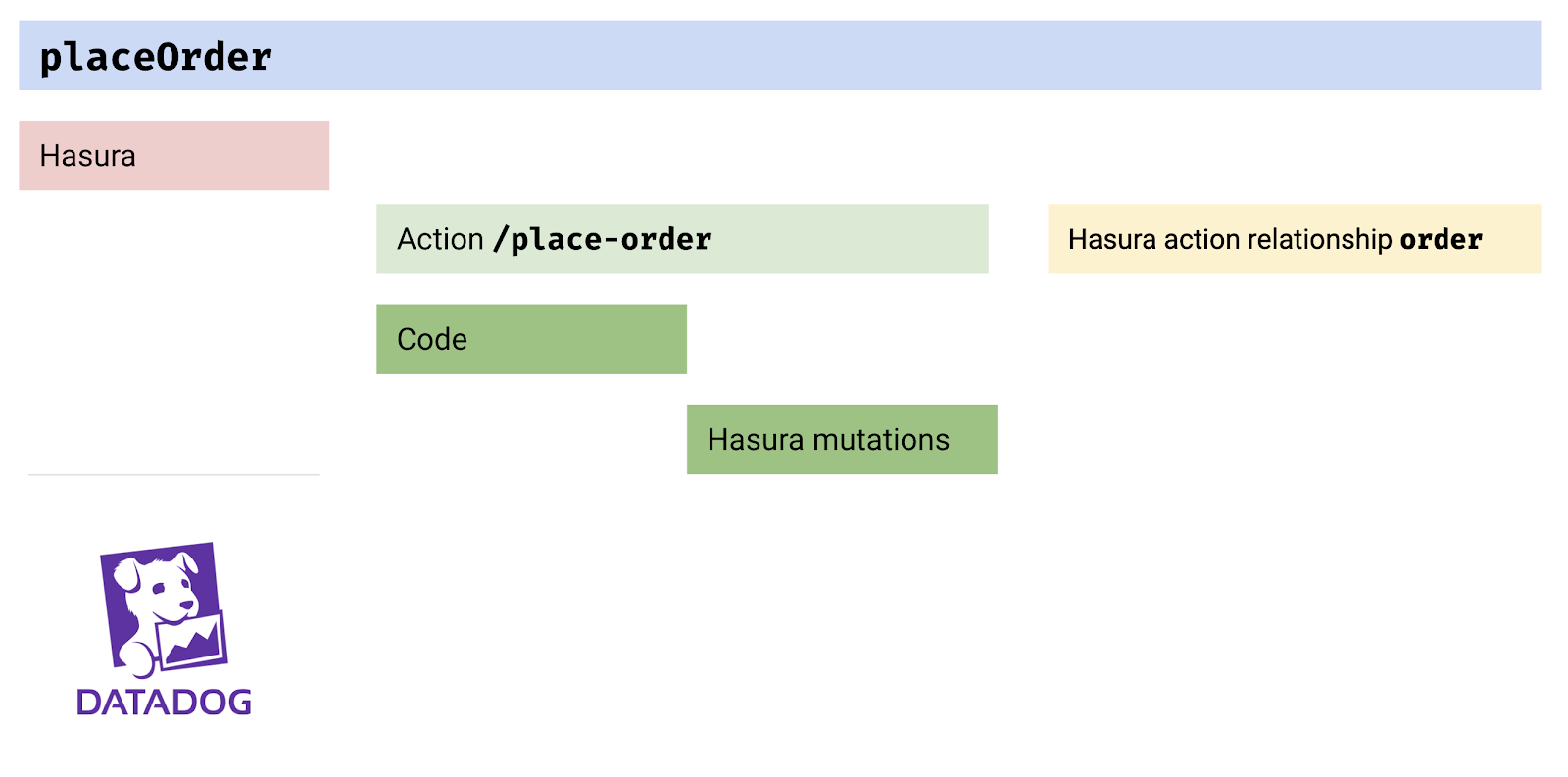
Hasura Cloud adds a deep integration with OpenTracing, so that it can create traces, or respect incoming trace spans. Hasura also forwards trace-ids and span-ids to services so that a distributed trace can easily be collected across your entire system. For example, this is what a trace collected from Hasura forwarding to an Action, that interacts with the database, whose response is then enriched by Hasura looks like when it's visualised end to end.
Today Hasura Cloud supports Datadog as a target to send traces to, and we’ll rapidly be adding more vendors that support OpenTracing over time.
GraphQL Rate limiting
When you’re running a GraphQL API in production, you might need to add some rate-limiting rules. Especially if your API is a developer facing API and not just used by an app. Rate-limiting allows you to make sure that your server and your data sources are protected from sudden spikes from malicious users and also allows you to make sure that your customers or tenants consume your API within reasonable limits.
Depending on what you want rate limiting to do, you need to maintain some state across various concurrent API requests to “count” your users’ limits.
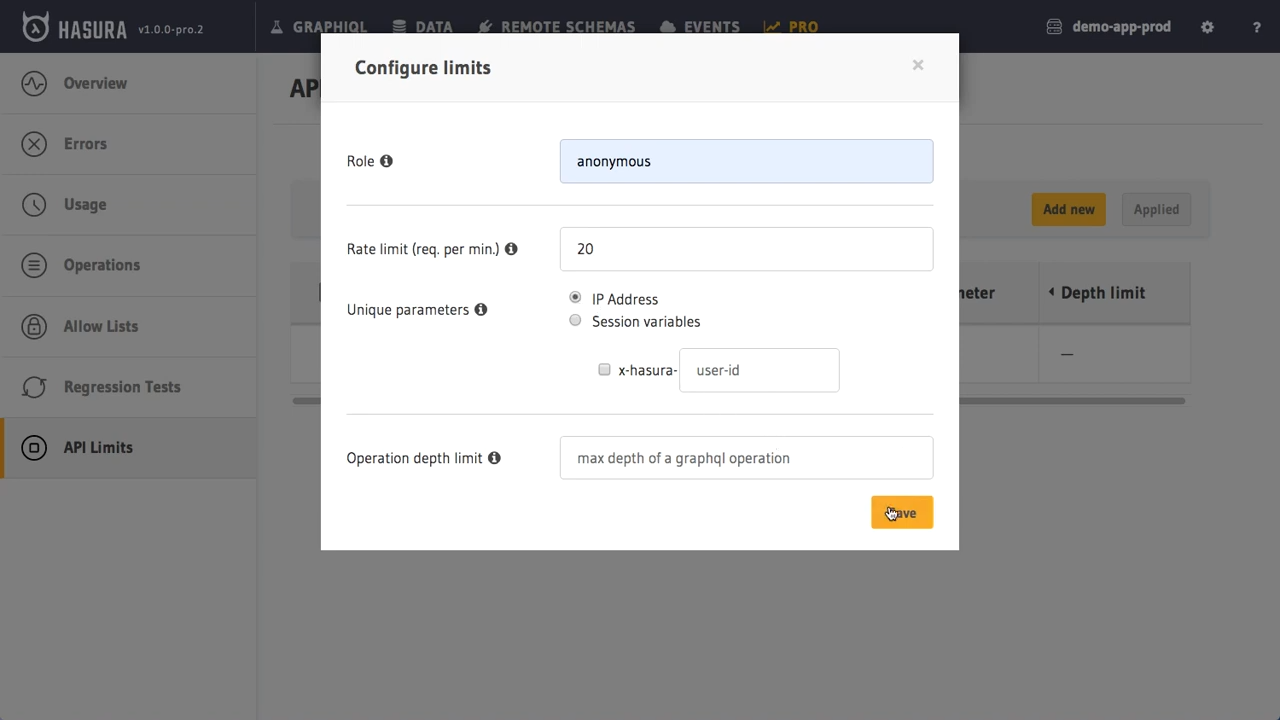
Hasura Cloud offers rate limiting for unauthenticated users (based on IP) or parameterized by end-user session variables. Rate limiting rules can set a maximum number of requests per minute based on the parameters above, and can set query depth limits also. Over time, we will add support for dynamic query cost based limiting as well!
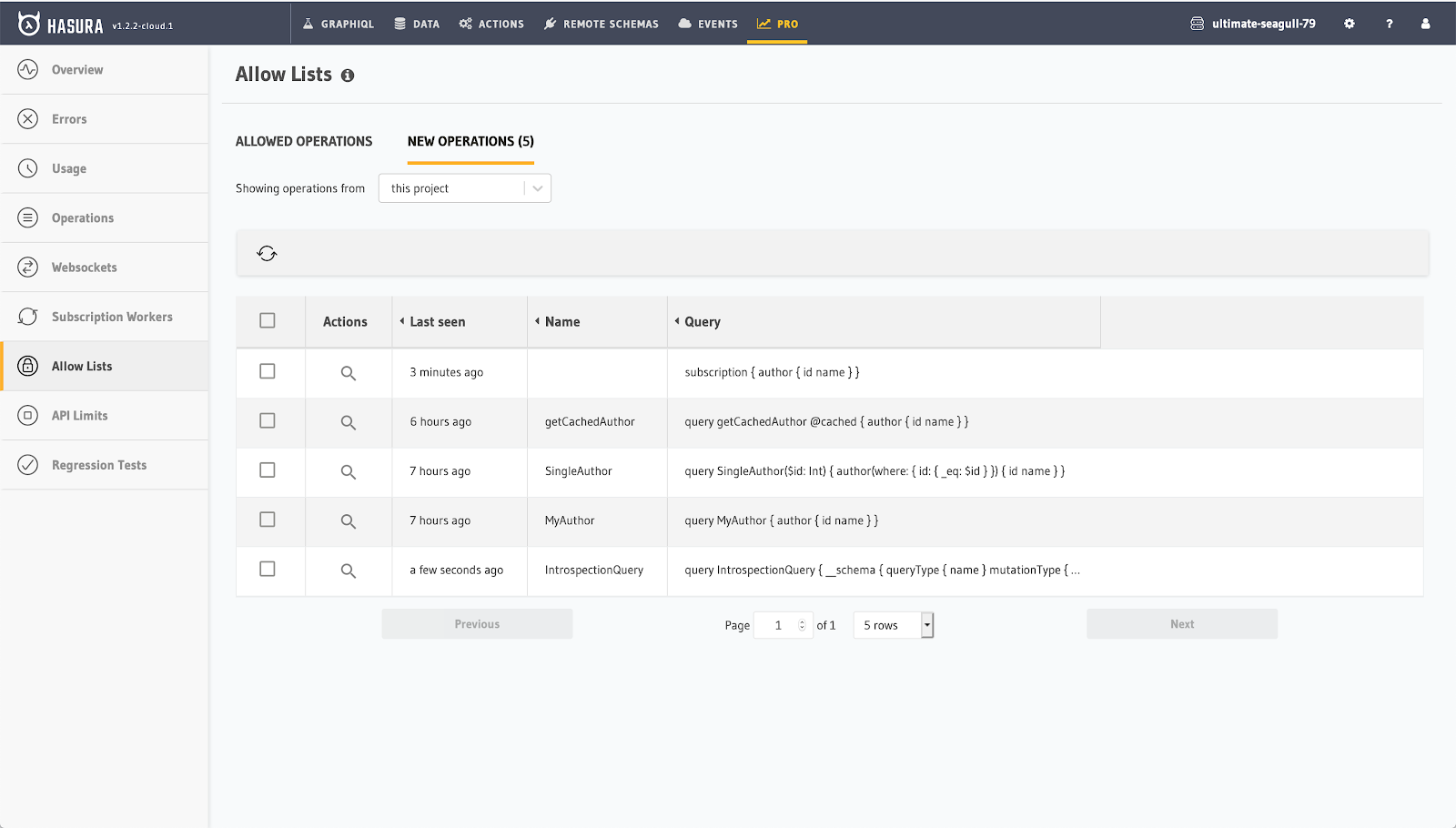
GraphQL Query capture
Hasura cloud captures queries (optionally stripping out session and query variables since they might be sensitive) and makes it available to you for 2 main uses:
Regression testing
Bootstrapping and managing an Allow List
You can export the set of GraphQL queries and mutations that have been captured by Hasura in a given time window and then use it for all sorts of things.
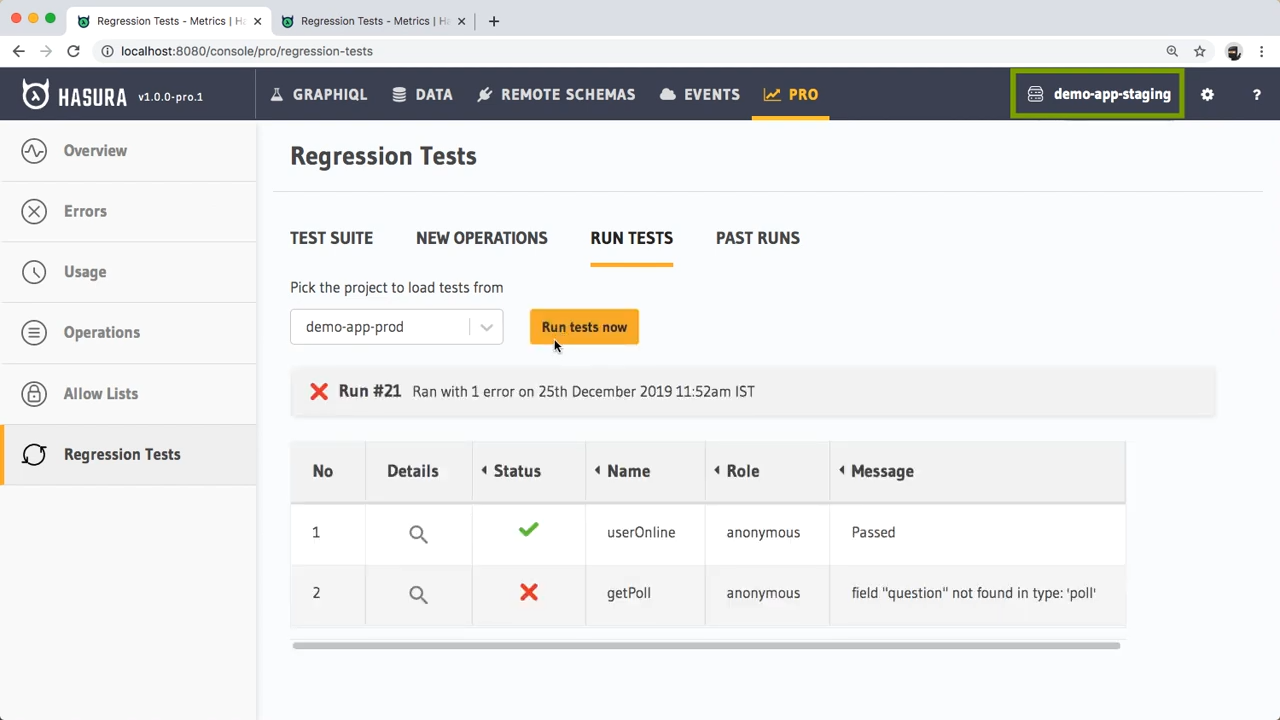
Regression testing: You can run a test in the Hasura console or your favourite test runner against your staging environment as you make changes! This way, you’ll know if any changes you make to Hasura will affect GraphQL queries you’re seeing in production.
Allow-list management: You can also use the set of captured queries to create or update an allow list. For example, your staging project on Hasura cloud can capture queries from your application testing suite and use that to help you build an allow list.
Network security
Hasura connects to databases and services running on systems owned by you. For example, you can connect to Heroku Postgres, or RDS, or cloud SQL, or your own Postgres running on your VM.
While all communication between Hasura and your services can be encrypted TLS/HTTPS you might further benefit from ensuring that your database and your services only accept connections from Hasura anyway.
You can do this with:
IP whitelisting
VPC peering / private link
We’ve also started the process of getting our SOC2, ISO 27001 and HIPAA-readiness certifications so that it’s easier for you to start using Hasura Cloud in an enterprise environment. If you’d like to more, please get in touch!