

Debunking GraphQL Myths and Misconceptions
People well-versed in GraphQL are often found discussing the latest compilation strategy, or the best way to optimize performance of federation. But sometimes, for people new to GraphQL, it’s simply not clear what GraphQL is doing in the first place. (And the name doesn’t help.)
Here are some common concerns/myths about GraphQL, from people getting acquainted with GraphQL, and clarifications to resolve them.
Myth: GraphQL, the query language is designed to let clients perform arbitrary queries
This is true, but just applicable during the development phase for developers who are building the client app. That's what makes GraphQL great. The DX of GraphQL consumption is amazing. The idea is to use tools like GraphiQL, test out different queries required for the client and integrate it in your application. GraphQL is self-documenting and tooling is much better than the equivalent REST spec - Swagger docs.
But, when in production, you typically restrict what queries are allowed with an allow list or persisted queries and simply call them from the client. Wrongly implemented security doesn't make GraphQL bad. Any API can be vulnerable if you choose it to be. REST APIs already sends boatload of objects that clients didn't need anyways.
Myth: GraphQL is a query language, like SQL for graph databases
This is just due to the sheer coincidence of naming!
The name GraphQL is a hint at the modeling and execution semantics. Queries are composed of a root Query field, which has nested fields. Each field can have further nested – and related – fields. This makes for a tree structure, which is a subgraph of the whole data graph that we can query.
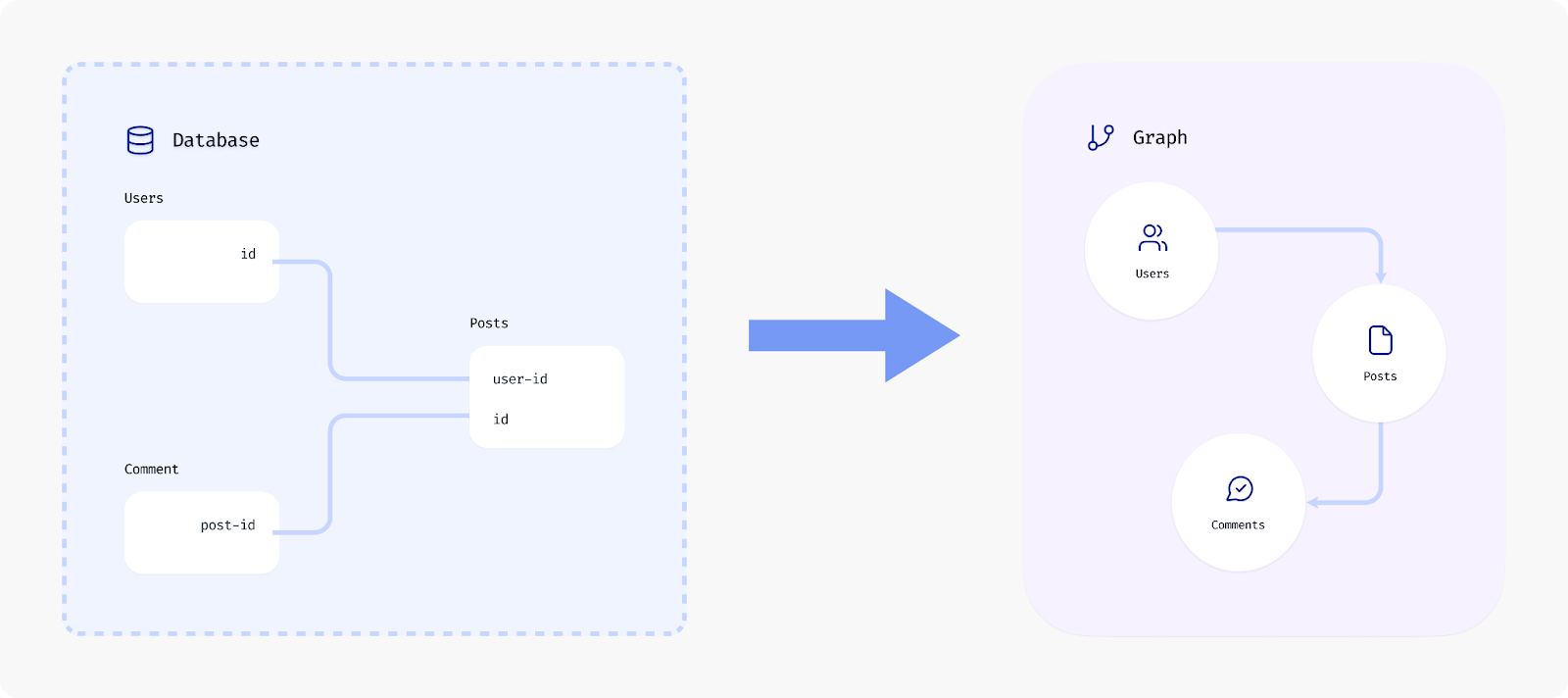
A graph is a very generic structure – any data source can be mapped to it. For instance, for a relational database like PostgreSQL, you could map tables to nodes, and relationships to edges in the graph. The key thing about a graph is that it emphasizes the connected nature of data, encouraging good modeling of the domain by identifying the different entities or models and laying out the relationships.
graphql
query {
posts(where: user_id == 4) {
created_at
content
user {
name
}
comments(order_by: created_at desc, limit: 10) {
body
}
}
}
Every field in a GraphQL schema (which specifies all the allowed queries as a collection of related types) can be backed by arbitrary code – exactly like an RPC endpoint – but with the additional advantage of having complete context of where it sits in the query tree.
Further, because clients query all the related data they need in one go, the whole query is available to the server, which means the server can perform global optimizations across the whole query during the execution. For example, the server can push down requests for related models into database joins, which is otherwise not possible if the client is making successive queries to data related to a previous query in an N+1 pattern.
Myth: GraphQL servers are hard to build and maintain
Everyone agrees that they want a GraphQL API, the question then becomes one of cost.
The majority of complaints about the complexity of implementation and cost of maintenance come from working at the wrong level of abstraction.
Programmers building GraphQL like this often complain about repeated code and boilerplate. You also hear complaints about building layers of wrappers and adapters, and how it's difficult to keep these layers up to date as modeling and functionality evolves.
Teams that successfully scale their GraphQL APIs all seem to converge on the same pattern: They're all building supergraphs! They're all using an engine like Hasura, where they specify the data modeling – the models and relations – and the engine automatically builds the GraphQL API (see how here).
When your GraphQL APIs are based on supergraphs, there's no cruft and you can iterate rapidly. Want to change something in your data modeling or underlying microservice? Simply change the engine configuration and your API keeps pace effortlessly.
Comparing writing resolvers manually to authoring supergraphs is like comparing JavaScript to React or NextJS. There is no comparison. And nothing stops you from using JavaScript when you exceed the limitations of the framework.
Myth: GraphQL has the N+1 query problem
Well, it does and it does not. A naive GraphQL server implementation has the N+1 query problem. With dataloader batching, it really isn't N+1 anymore. Tools like Hasura, Postgraphile compile GraphQL to SQL efficiently. It is much faster than a dev team trying to optimize from scratch. A badly implemented server doesn't make GraphQL bad.
But yes, most tutorials start with the naive resolver methods and that is a problem. This goes back to the previous myth as well – GraphQL servers are hard to build and maintain.
Myth: GraphQL is unnecessarily complex for small teams
The truth is that, for a small project, your tech stack doesn't really matter. At that point, it matters a lot more what tech your team has experience with! If you can get away with using a Google Form instead of building something, you probably should. A landing page could be your startup's MVP to validate a product. As simple as possible... but no simpler.
If your team has a single database and full stack engineers iterating rapidly across the entire stack, building and iterating on features both on mobile apps and the server, especially when you're iterating rapidly on the API itself, then RPC can be far easier to work with than GraphQL. The additional structure imposed by GraphQL can begin to look like a burden. At this stage, you'll often hear developers claim that it's so easy to add and modify RPC endpoints that GraphQL isn't worth it. And maybe they're right.
GraphQL shines as a method to query richly connected data. Building a supergraph creates this richly connected data. You can now model relations across different teams and domains in organizations, a supergraph can model relations across different data sources. Siloed data comes alive and is discoverable.
Supergraphs solve the harder problem of communication. (See Conway's Law). What this means is that every team can own and build their own graph with crystal clear interfaces, and then the supergraph just stitches these together, while making sure that all the constraints are enforced.
This is better than using just a simple API gateway because the supergraph is based on models. Unlike an API gateway, a supergraph is not limited by the structure of the data that the service layers return. We can go further, and begin to look at all our data across all sources as part of a single large source that’s queried flexibly, with a query planner that optimizes queries across the whole supergraph.
When does a small product become a large product, and where do the tradeoffs begin to make sense? Perhaps when the product is validated? Perhaps when you add another data source. Perhaps when you have some clarity on the contracts that you want the API to have and you're ready to share it with the world!
Myth: Caching is hard in GraphQL
“There are only two hard things in Computer Science: cache invalidation and naming things.” – Phil Karlton
The whole caching lifecycle is tricky irrespective of protocols involved. In GraphQL, there is client side caching and there is server side caching. GraphQL with its schema design and the client tooling like URQL and Apollo Client, the frontend caching story is much better than REST. Pre GraphQL/TypeScript, frontend caching wasn't even on the radar. TypeSafe clients are being used on the frontend with granular caching rules.
On the server side, the fact that everything is a HTTP POST request in GraphQL makes it different to reason about caching with existing tooling that is built for years supporting REST spec at the network layer. The mental model is different. Tooling already exists (@stellate) and there is more work to be done in this space. The truth is, caching is tricky irrespective of whether you are dealing with GraphQL or REST. In GraphQL, you cannot rely on HTTP verbs like GET that you typically use to cache in REST. Instead, you need to look deeper in query responses which also may have errors inside.
{
“data”: [], -> cache fields inside this
“errors”: [] -> look for errors here and ignore
}
Conclusion
It’s often not easy for engineers deep in a tech ecosystem to adopt a first-principles point of view and evaluate technology from a first-principles basis.
It is important to understand the tradeoffs and work as a team on both the frontend and backend and you will get the value of different tools. GraphQL is great for being the data layer that stitches together different microservices into a supergraph. The consumption layer can be anything – REST/GraphQL/gRPC. It really doesn't matter at the end of the day. Incrementally adopt any tool that fits your needs.
Hopefully, recognizing these common myths help you better evaluate GraphQL for your needs. And better yet, if GraphQL is a good fit, help evangelize it as a solution for your team or organization.
Sign up now for Hasura Cloud to get started!

20 Nov, 2023
6 MIN READ

