

Product Announcements at HasuraCon’22: making GraphQL the ultimate Data API
- Extend Hasura to any data-source:
- Announcing Hasura GraphQL Data Connector SDK (alpha release)
- API evolution to support emerging data workloads:
- Streaming Subscriptions: capture large data and fast-moving data
- MS SQL Event Triggers: To build event driven workflows on SQL Server with native CDC
- GraphQL DevOps improvements:
- GitOps for GraphQL: Automated CI/CD with Github Integration in GA on Hasura Cloud
- Enhanced observability: support for OpenTelemetry Traces in Hasura Cloud & EE
- Increased cloud-vendor availability:
- Hasura Enterprise on AWS Marketplace
- Hasura on Google Cloud Platform
Introduction
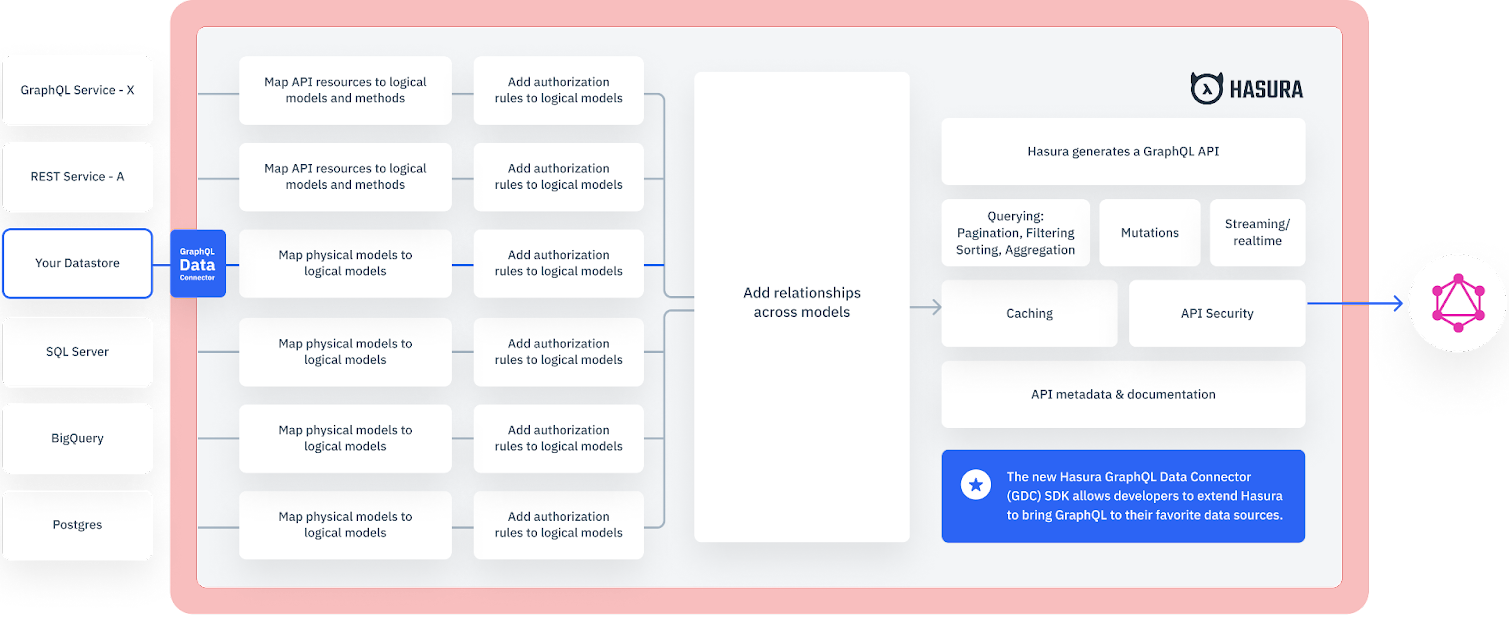
- Application Backend: Hasura is used by application development teams to build the backend of their applications. Hasura takes care of all CRUD APIs, real-time APIs as well as access control for the APIs, leaving only business logic APIs to be written by the developers.
- Centralised Data Access Layer: Hasura is used by data & platform teams to have realtime APIs and centralised authorization and governance for the API for analytical and operational data in their data warehouses & data lakes. Data from warehouses is ELT'd into a Hasura supported relational databases like Postgres to be able to use Hasura's realtime engine. (Watch Dan Keeley's talk at HasuraCon'22 for to see this in action) .
- Federated Data API: Hasura is also used by platform and app teams to create a unified data API for their organization, for other teams or external vendors. Hasura is connected to the different data systems directly to create a unified GraphQL API. With Hasura’s powerful querying abilities, including data federation APIs (cross domain joins between databases and GraphQL APIs) and the authorization engine, the GraphQL Data API can be directly used by applications and other APIs.
- Data Sources (input to Hasura): increasing our coverage for being where your data is, in different data sources, or cloud vendors.
- GraphQL API (output from Hasura): The instant data API that Hasura provides is constantly evolving to support more sophisticated data workloads
- DevOps with GraphQL: As GraphQL becomes part of your stack, we are constantly working towards improving how GraphQL can fit into your existing workflows & production checklists.
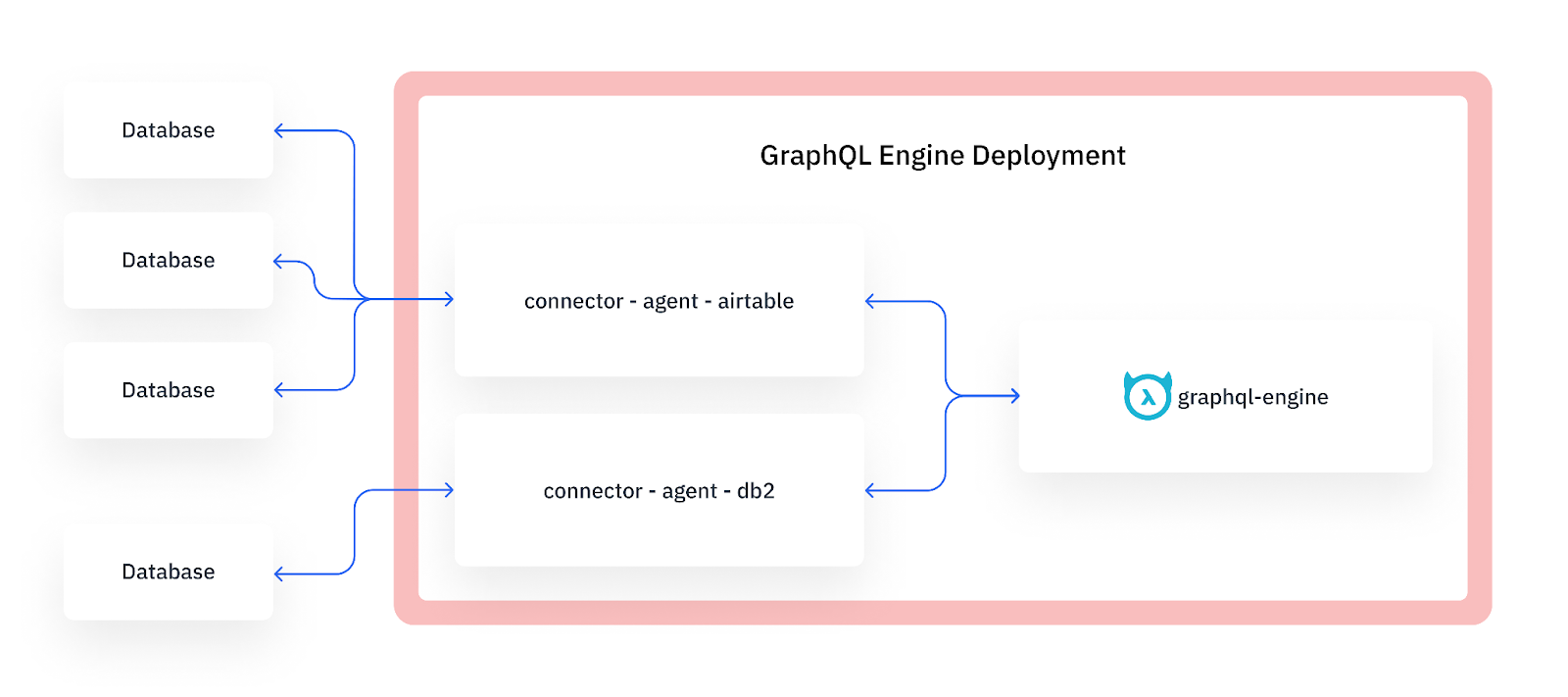
Hasura GraphQL Data Connector SDK (alpha release)
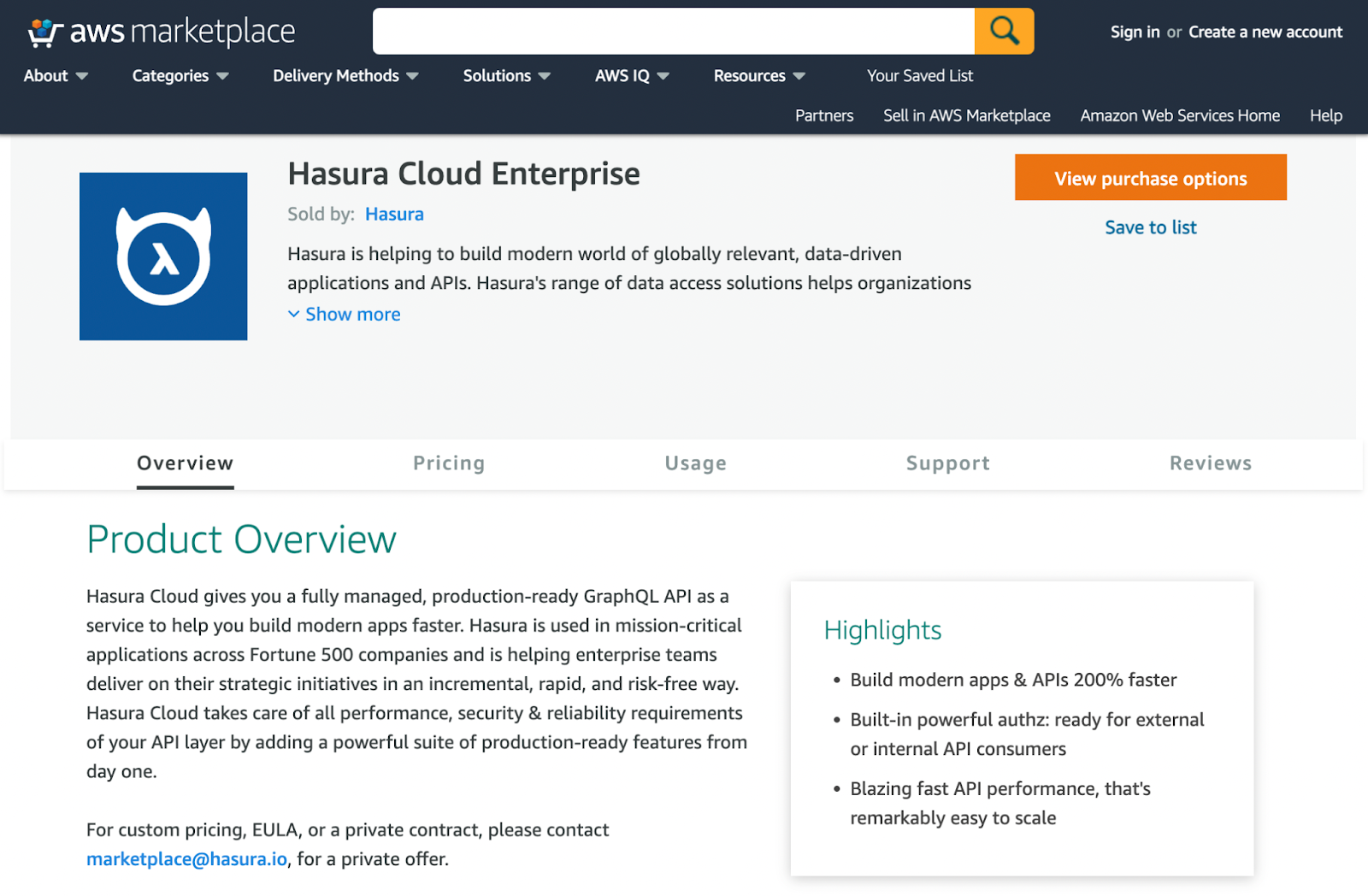
- Hasura Cloud Enterprise Availability in AWS Marketplace: Hasura's Cloud Enterprise offering is now available on the AWS Marketplace. AWS customers will benefit from simplified procurement and billing and the ability to take advantage of AWS discount programs. Get started here.
- Hasura on Google Cloud Platform (GCP) General Availability lets Hasura Cloud and Cloud Enterprise users with databases and other services on GCP create Hasura projects in GCP, reducing egress charges and improving performance due to co-location. Hasura customers using Virtual Private Cloud (VPC) on GCP are now able to peer with their own VPCs - increasing performance and security. With Google announcing some incredible databases, we’re excited to see our users use Hasura with GCP Postgres, BigQuery and new databases like AlloyDB!
- Streaming Subscriptions API allows users to build high-performance real-time apps using Hasura, streaming data to their clients in batches and updating data in real-time. Streaming subscriptions in Hasura GraphQL Engine allows users to stream data using a GraphQL subscription API and the websocket transport protocol. The API can be used to build real-time apps that can receive “subscribed” data as a stream (continuous events). This makes fetching large volumes of data possible and getting new data instantly possible.
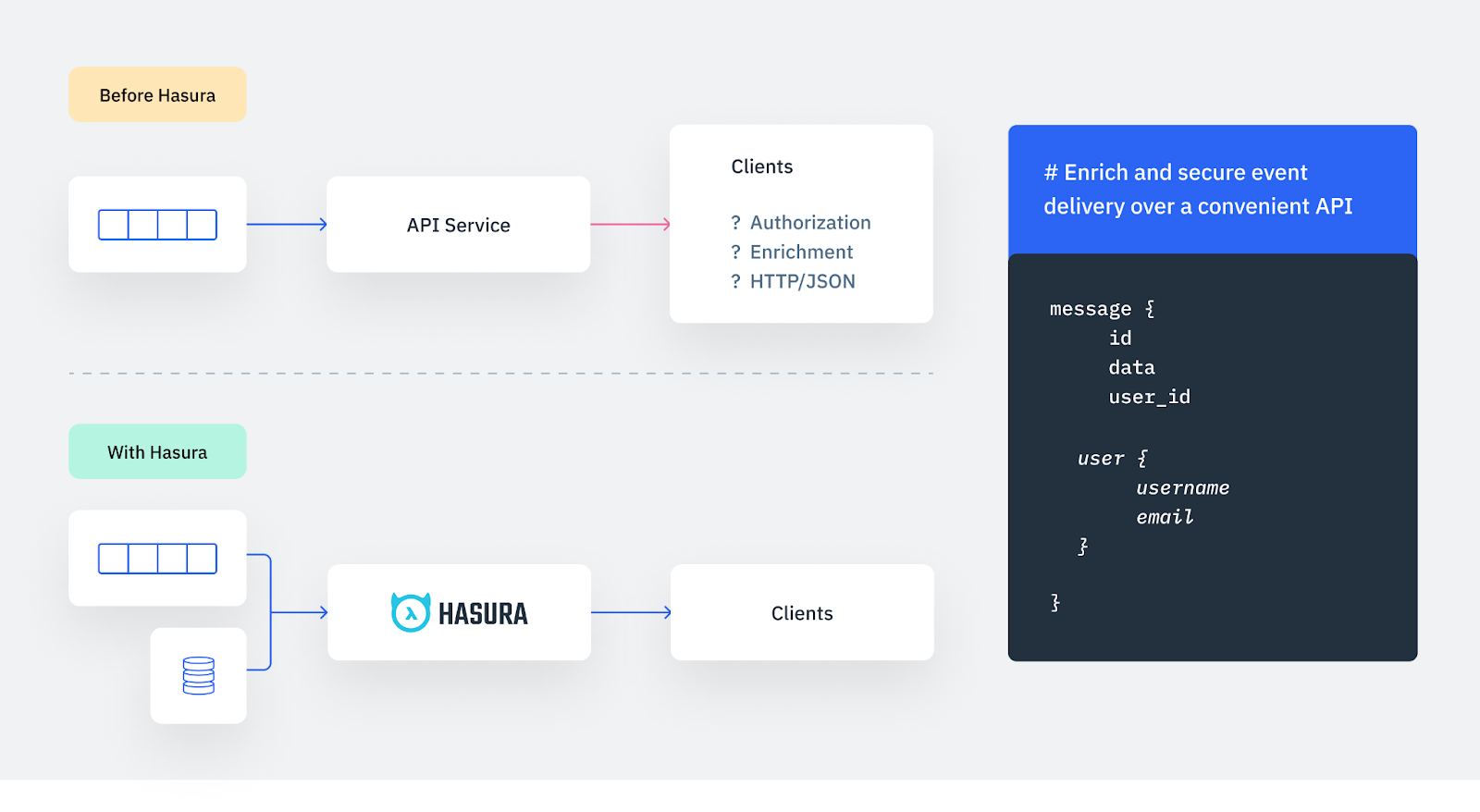
- Event Triggers Support for MS SQL Server enables users to connect business logic APIs with Hasura to integrate asynchronous backend logic into their applications by calling webhooks on table events such as insert/update/delete for SQL Server data sources. Event triggers have been one of the most loved features that Hasura first introduced on Postgres, and we’re now excited to have support for event triggers for MS SQL Server databases enabling users to connect business logic APIs with Hasura to integrate asynchronous backend logic into their applications.
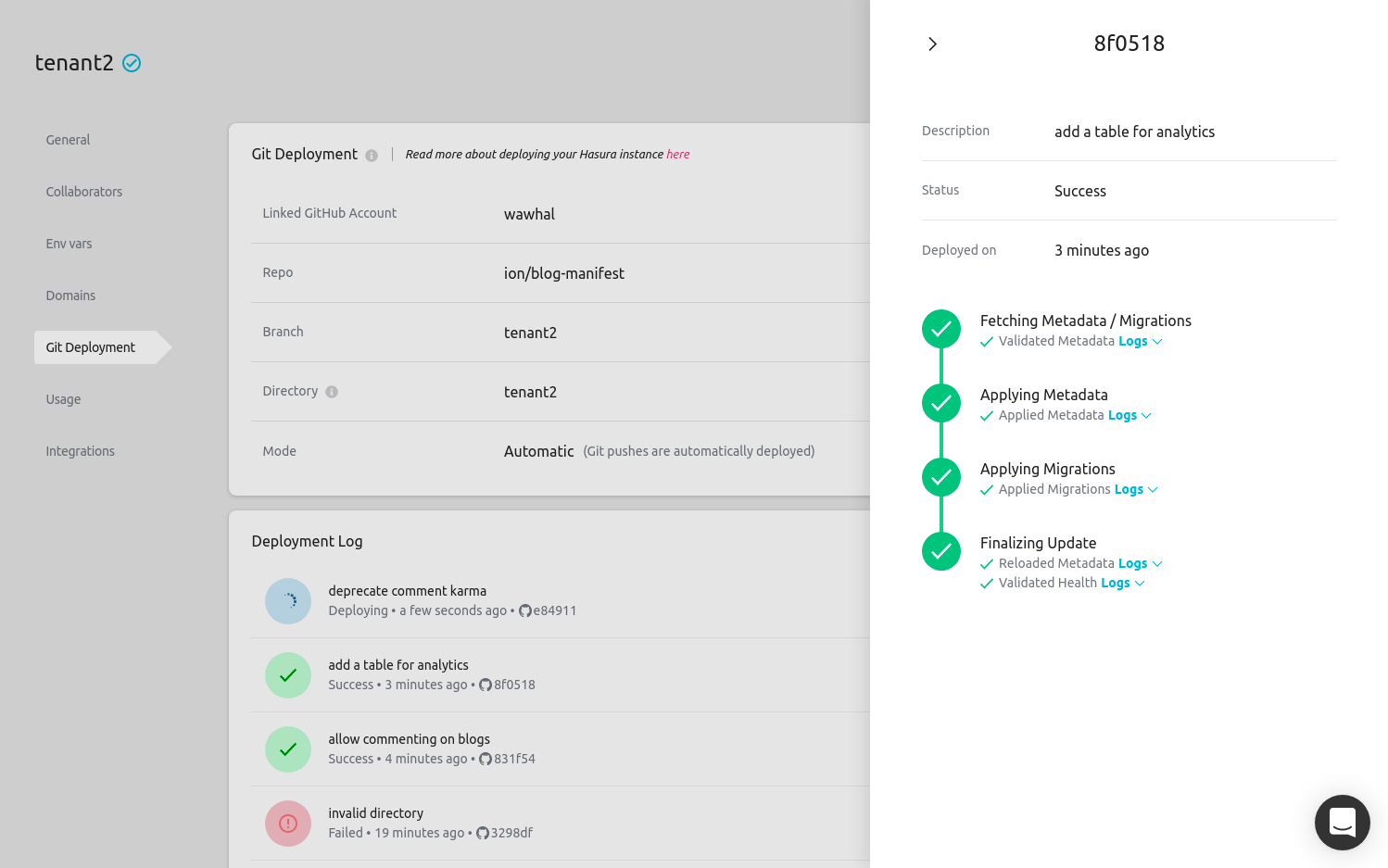
- GitHub integration General Availability increases ease of CI/CD pipeline management, reliability and development speed by helping developers move quickly and easily between local development and Hasura Cloud. A preview apps feature (still in beta) enables users to quickly test changes to metadata migrations and link to GitHub PRs to automatically deploy with every push.
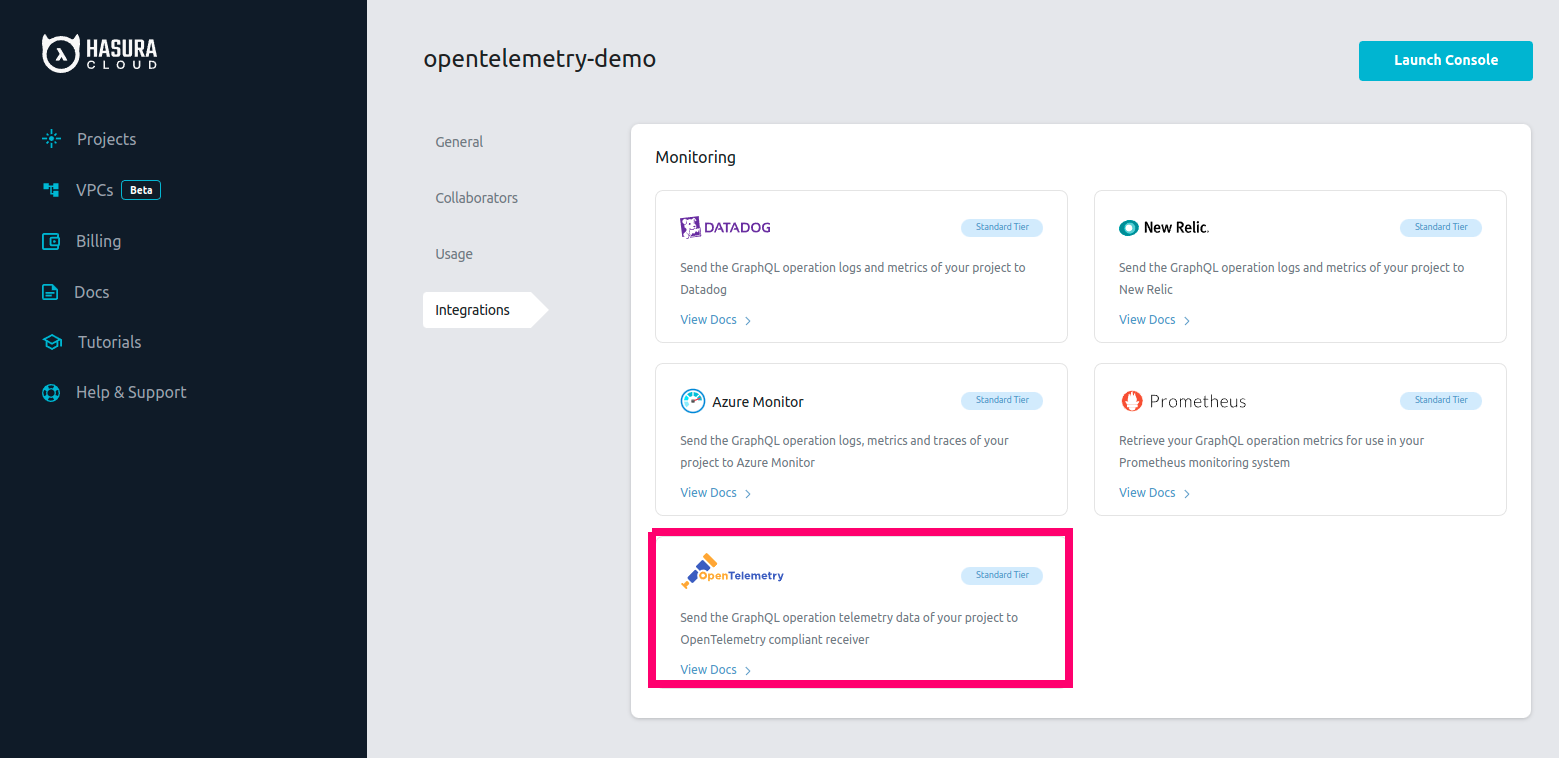
- Support for OpenTelemetry Traces in Hasura Cloud and Hasura Enterprise Editions gives customers enhanced observability through traces in the OpenTelemetry format via OpenTelemetry compatible agents and direct connections with APM tools such as New Relic and Dynatrace. This enables them to provide better reliability and end user experiences for their mission-critical applications through rapid problem diagnosis.

Related reading

