Architect’s dilemma: When to choose GraphQL over REST and why?
Recently, I took a stab at Debunking GraphQL Myths and Misconceptions. The takeaway of that exercise: Use GraphQL for what it is meant to be, understand the trade-offs, and approach problems and evaluate technology from a first-principles perspective.
Along those similar lines, a new tweet thread blew up recently:
The thread talks about GraphQL complexity from a performance perspective and compares it to REST, and I wanted to address some concerns – this time at an architectural level.
More so than this being GraphQL vs. REST argument, it’s important to understand that GraphQL can co-exist with REST APIs, or replace them altogether, and either choice has different implications.
> If you’re interested in the basic differences between GraphQL and REST, read our tutorial on GraphQL vs. REST.
The first step to evaluating these choices is to clearly identify the problem being solved. Let’s look at some use cases where this dilemma comes up:
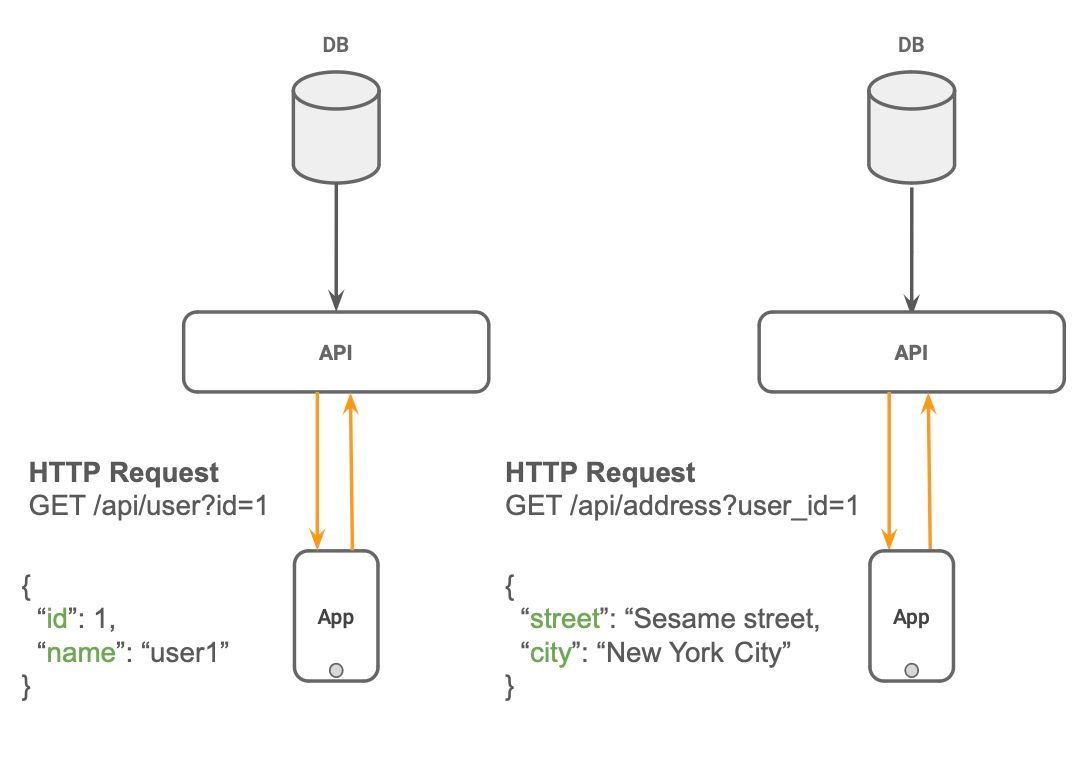
Use case 1: Client side N+1 problem: Reduce client-to-server latency
Consider a use case where your client (web/mobile) needs to fetch data from different entities. A naive implementation would send multiple HTTP calls from the client to the server.
Multiple HTTP REST requests to fetch data from the client
Network latency between client and server will almost always be higher than network latency between co-located API servers and data sources. On the server side, in many cases, it is an internal hop and not an external hop, further reducing latency.
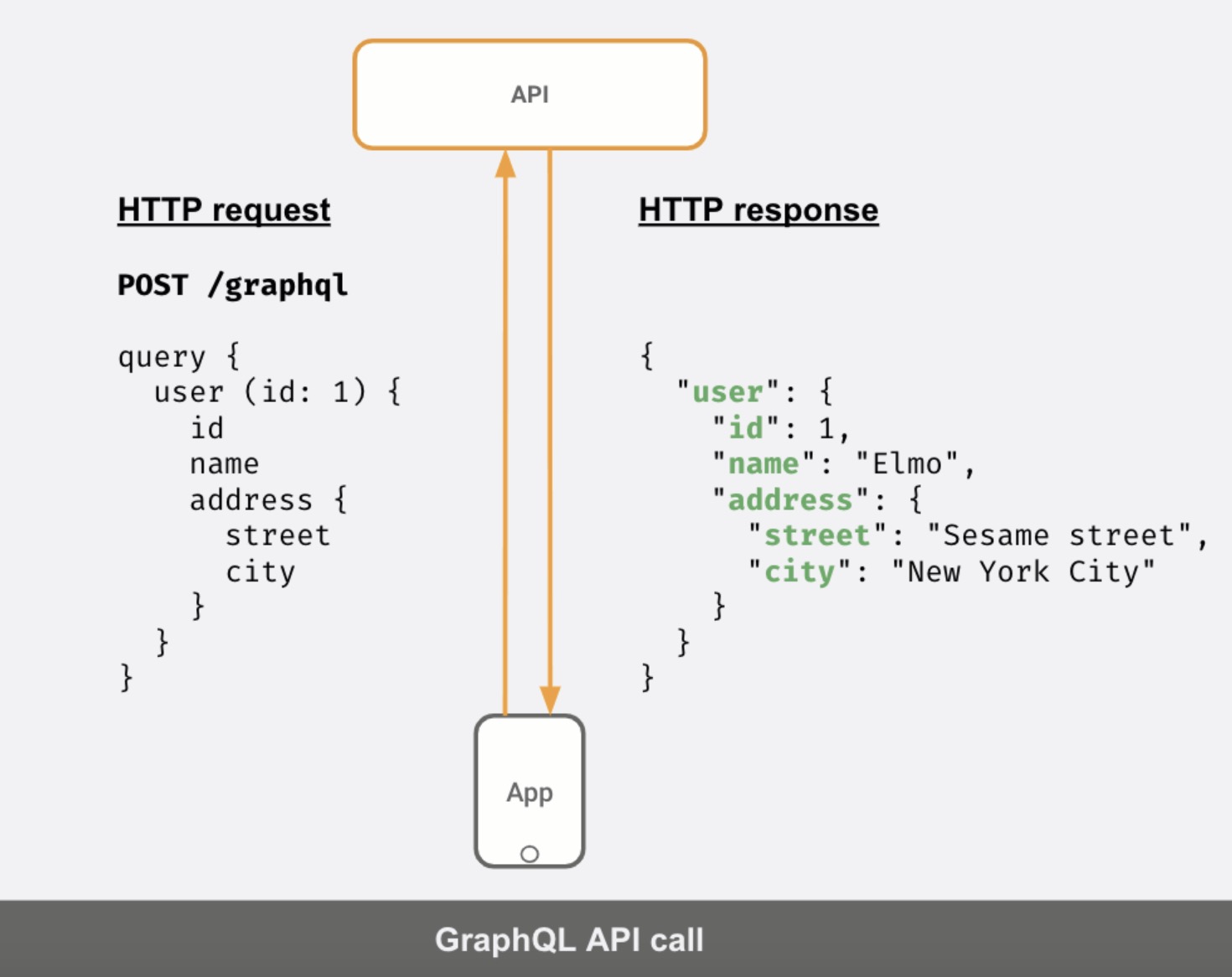
GraphQL is an instant win when there is a client-side N+1 problem like the above. GraphQL makes it easy to query deeply nested data from the client and/or fetch multiple independent entities in the same HTTP request. The multiple calls can be replaced with a single GraphQL query on the client side.
One GraphQL request to fetch exactly what you want
Now, the obvious question is, “Why can’t I use query parameters or dynamic request body to a single HTTP REST endpoint to solve this problem?”
Of course, you can. But here’s why you’d still be better off using GraphQL:
GraphQL tooling is better for parsing this query and there’s no standardization on the REST layer to be able to do this dynamically (ie. there’s no schema/type system).
You get exactly what you ask for – GraphQL maintains the shape of the response exactly the way it was queried, which is difficult to maintain in REST without more boilerplate code.
Using GraphQL, you avoid building more REST endpoints to solve the problem.
GraphQL is the most elegant solution to this client-side batching problem. Here, the N+1 problem is delegated to the server. If GraphQL doesn’t feel as easy as REST – you just need a better approach. tRPC skipped relationships and went all in on just batching, and that server implementation feels easy. Well, the best gRPC frameworks feel just like that.
If you're using GraphQL for "just batching API calls," building GraphQL should be much, much simpler.
Use case 2: Server-side N+1 problem / API integration
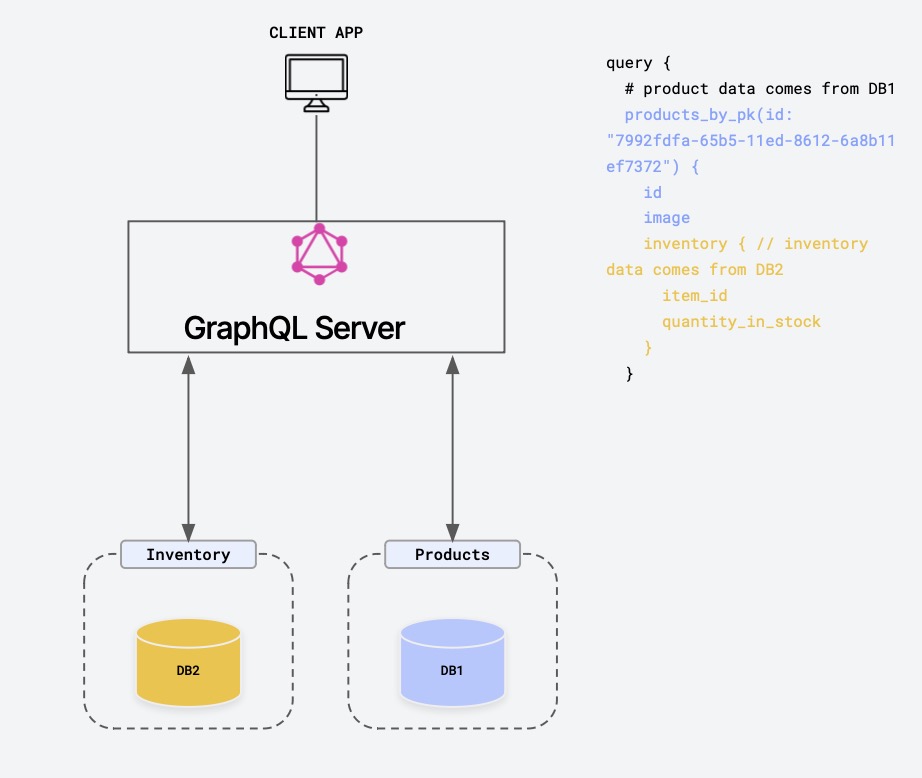
Now consider the use case of optimizing the queries on the server side, when there is a problem of fetching data from multiple sources on the backend.
A naive implementation of GraphQL has the dreaded N+1 problem.
In use case 1, the problem was delegated to the server. Whether the client uses GraphQL or REST to solve the problem, the load on upstream services will be the same. The upstream services could be databases or more REST APIs underneath.
How do you reduce the load on upstream services like the database or APIs?
Beyond adding indexes and fine-tuning the database, fundamentally you have to optimize for the following concerns:
The number of queries sent to the upstream services (N+1 query problem)
The actual query sent to the database should be efficient
Let us address the concerns:
Concern 1: The number of queries to the upstream services (N+1 query problem).
In the case of GraphQL, the number of queries is a fundamental problem, even for a single data source, but this is largely mitigated by using a Dataloader pattern/batching. In the case of REST APIs, ORMs will have similar problems and the best you can do is batch the database queries to reduce the load.
In case of multiple upstream services involved, your server being REST or GraphQL for this doesn’t matter. Essentially you need a good routing solution and an efficient federated server to batch queries across data sources. If anything, GraphQL makes it easy for the client to make this kind of query, one spanning across multiple data sources in the same request.
Concern 2: The actual query to the database should be efficient.
This is related to the first concern, especially in the context of a database being the upstream service. Batching solves the problem of sending too many queries. But you’re still sending multiple queries.
At the outset, you want to reduce the number of unnecessary hits to the DB as much as possible. As the number of requests to the DB increases, the number of active connections will increase and you will have to start managing connection pooling.
If you're using GraphQL to make APIs as flexible and composable as possible, well, you need to implement a query planner. Unlike REST APIs, where you need to optimize every query individually, GraphQL lets you “compile” them, irrespective of the depth of the query.
API consumers (clients) typically want a predictable, well-documented API. REST producers try solving this with OpenAPI specification and by generating Swagger documentation.
GraphQL is fundamentally a self-documented API and is much more predictable due to the schema and type system involved. The schema contract lets frontend and backend developers work independently with a guarantee that data requirements are met.
The type system makes it easy for clients to generate types on the frontend and build a more Typesafe API integration. Tooling like GraphiQL makes it easy to explore APIs.
The queries let you fetch exactly what you want, making it much more flexible than REST, and reducing network transfer with large payloads. It all adds up, eventually.
> You would want to choose GraphQL over REST for this consistent, self-documenting, and flexible API experience.
Summary
Building a GraphQL server that doesn't optimize for the client-side N+1 or the server-side N+1 problem gives you the worst of both worlds.
GraphQL is almost always the better experience over REST for solving the client-side N+1 problem. For the server-side N+1 problem, it depends on the implementation on the backend and well, you need a query planner if you are using GraphQL in the backend.