Building a unified data access layer on domain APIs
One of my job's perks is interacting with Technical Architects at conferences and in more intimate one-on-one chats. Learning what enterprise engineering organizations are trying to build and, more interestingly, how is fascinating. Given what Hasura offers, many of these conversations veer toward design decisions for building a unified data access layer.
You may know this architecture by other names such as a knowledge graph, a unified semantic layer, or in some cases a BFF layer (if one is not being pedantic with the definitions). Going forward, I’ll refer to all these as a data platform or platform.
The motivation is clear to many teams – data is powerful in aggregate, i.e. when all the data available to the organization, regardless of its location (domain) or ownership (team), is leveraged to craft user experiences or to implement certain use cases, interesting things become possible. It’s also become apparent that the rate-limiting factor in such innovation is the accessibility of unified data.
Moreover, research everywhere (page 11) concludes that the #1 factor that’ll decide the outcome of your generative AI project’s success is your data strategy! There’s a lot riding on the success of your data platform initiative.
In other words, enterprise architects are racing against time to connect disparate data sources into a unified data access layer. However, some of them are running into speed bumps when the source in question is an API, and there are several of these bumps to navigate in the modern enterprise.
So I want to spend some time analyzing this particular problem from the lens of not just data API architecture, but also how organization design and incentives cause and affect this problem. To wit, I want to use these two anonymized anecdotes to help us with the analysis:
Enterprise A: A European technology conglomerate looking to build a unified data access layer over a diverse heterogeneous set of domains.
Enterprise B: An American credit card and financial services organization that wants to implement a federated data access layer over thousands of domain services.
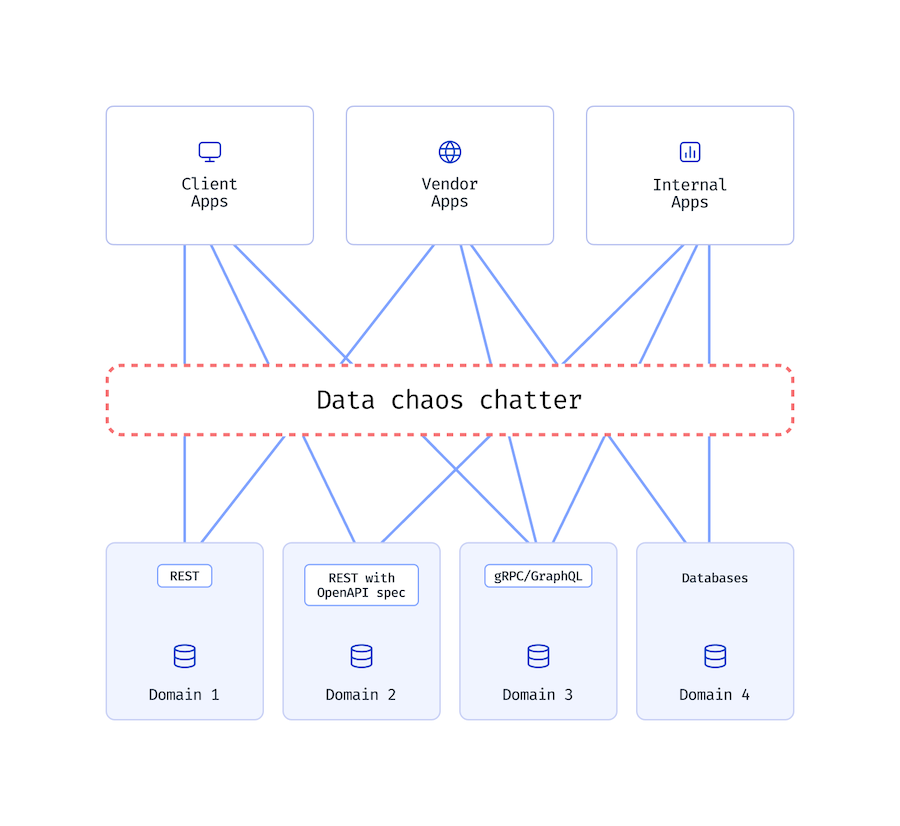
Enterprise data landscape
To cut a long, obvious story short, thanks to patterns like service-oriented architecture (SOA), microservices, and domain-driven design, in every enterprise you’ll find teams that own one or more business domains that power one or more “applications.”
Depending on the scope of the consumer application, the technology stack used, and the SOA maturity of the organization, each of these domains may look nothing like other domains.
Here’s what the domain data landscape in an organization might look like:
Of course, this is a simplified representation of domain data – several nuances are missing, like derived domains, duplicated domain data, etc., but they don’t factor into our analysis just yet.
This is the landscape that architects are trying to harmonize into a single, scalable interface for application developers. What does such an interface look like and what must an effective one deliver? Let’s take a look before we begin our analysis.
Design goals of a data access platform
This is a very interesting topic that we can spend a lot of time on. For the sake of brevity, let’s focus on some of the key requirements (purely from a comparative perspective) of a platform that’s to be the go-to interface for application developers to consume org-wide data.
Functional requirements
Type information: As the gateway to your data, your platform must explain the data it offers by having rich semantic information about it to support data discovery and consumption.
On-demand, self-serve data access: An effective platform makes every slice of data available for developers to effortlessly consume. Think of all the data types and every permutation of relationships between them available for querying either standalone, aggregated, or integrated/composited.
Non-functional requirements
Performance: This cannot be emphasized enough – we are talking about building a distributed aggregation layer on top of other potentially distributed systems. If there are performance bottlenecks in your systems, they will be hit and platform adoption will immediately stop in its tracks.
Timeline and costs: As an architect of this platform, you need to deliver this on time for applications to leverage. Also, in case you haven’t heard, you need this to support any agentic AI use-case strategy your org has in mind.
Analysis
Data sources and unified data access
Different data sources are more or less conducive to being included in a unified platform. Let’s use a combination of the representative set from earlier in this analysis and the requirements of a data access layer to dive deeper into this:
Type information: One way to think about building a semantic layer is that it’s an exercise in hydrating type information from a data source into a semantic layer. The more the semantic density of a source, the easier it should be to connect this source to the platform. It should be easy to see that this is how the different sources rank on this factor:
Source
Type information
Ranking
Databases
Rich type information for every model and its field
Relationship information via constraints
1
gRPC/GraphQL
type information for every model and its field
Relationship information via constraints
2
REST endpoints with OAS
Some type information but not consolidated per model
NO relationship information
3
REST endpoints without OAS
No type information available, will need manual annotation or code to inject this information.
4
Takeaways
Enterprise A: This team will have to work with all the above source types. To quickly demonstrate value, the team can perhaps select higher-ranked sources to be connected to the platform first to show a rich unified schema. Enterprise B: Similarly, this team could prioritize domains with OpenAPI specification but it’s not strictly necessary yet.
2. On-demand, self-serve data access: When it comes to supporting different variants of the same data (standalone, filtering, sorting, aggregated, integrated/composited, etc.), the key factor influencing the ranking of a source is whether it inherently supports the building blocks required for slicing and dicing its data.
So, if you were to compare a set of REST APIs that support a domain model vs. the corresponding database model, you’ll find that most databases have out-of-the-box support for any variant of accessing the model (with SQL clauses like where, group by, order_by, etc.). On the other hand, REST endpoints are only as good as their implementations, regardless of whether they have some metadata like OpenAPI specifications or not.
Source
Access pattern support
Ranking
Databases
Support almost all permutations of CRUD.
1
gRPC/GraphQL
Depends on implementation, usually support some form of filtering.
2
REST endpoints with OAS
Depends on implementation.
3
REST endpoints without OAS
Depends on implementation but also harder to understand behavior without documentation.
4
Takeaways
Enterprise A: This team will have the opportunity to showcase a richly interconnected schema more easily with a database, so it can again choose to prioritize this source type for demonstrating value. Enterprise B: The richness of the access patterns of this team’s platform will depend on what the domain teams have already implemented. Supporting this on the platform side will result in performance issues.
3. Performance: Databases have been around for a few decades and have been hyper-optimized for query performance. APIs (regardless of whether REST, GraphQL, etc.) are engineered ad-hoc and are subject to the expertise of the developer. Depending on the implementation, APIs have at least a minimum footprint per execution.
For example, a popular GraphQL implementation pattern involves writing code that first fetches all the fields from a table in a data source, and then filtering out the fields that aren’t requested to support underfetching. A similar penalty is imposed when you use ORMs. A sports analogy for this would be a relay race where one of your runners is forced to wear a heavily weighted vest, and yet you expect to win!
Takeaways
Enterprise A: This team has an opportunity to contrast the perf of databases against APIs, and use this data to help the org make an architecture decision (using databases in all domains when possible). Enterprise B: If possible, this team could benchmark the upstream REST endpoints to show incompatibility with the scale requirements of the platform with arbitrary querying. The team can also choose to ignore this exercise at this stage and make a case to leverage the underlying database when inevitably presented with a performance problem.
4. Timeline and costs: When talking about time/effort,it’s time for us to also factor in the low-code, metadata-driven pattern of building API and platforms. This is a newer pattern that complements traditional, code-heavy MVC frameworks (think Spring Boot, Django) or even the so-called lightweight MC frameworks (Play, Flask) by automating the boilerplate parts of API code. It does so by leveraging any and all information (metadata) available about the underlying data. This metadata is leveraged to automate the generation of CRUD endpoints that can be customized for business logic (using traditional methods of your team’s choice).
Perhaps it’s now clear why in the previous sections we compared a database with APIs (when an API must also eventually deal with the database). The scope of APIs is greatly reduced when you think about the task of accessing the underlying data (CRUD) as a general-purpose solution (CRUD on any table is general, and CRUD on the `authors` table is specific). In other words, this factor is somewhat of a corollary to the one about type information – the more information you have about the data (and the source), the easier it is to build general-purpose solutions.
With this context, the following is again a very obvious ranking for efficiency and ROI:
Source
Scope for automation
Ranking (with automation)
Ranking (without automation)
Databases
Machine-readable information about the data and its relationships.
1
2
gRPC/GraphQL
Machine-readable information about data and its relationships; this information is not as rich as most common databases.
2
1
REST endpoints with OAS
Machine-readable information but at a per endpoint-level granularity – the complete data domain is not available for full automation.
3
2
REST endpoints without OAS
No machine-readable information is available, automation requires some code to interact with these APIs to convert response data into types.
4
2
Takeaways
Enterprise A: This information helps this team prioritize domains/sources based on their bandwidth. They can choose to prioritize databases in the interest of speed, show results quickly, and prove out the architecture/approach. Enterprise B: As the team needs to connect thousands of endpoints, to demonstrate any kind of effectiveness, this team must leverage as much automation as possible, preferably prioritizing endpoints with OpenAPI specification.
Results
If you’ve ever built schema-based APIs like GraphQL or gRPC, you’d have noticed the duplication in domain modeling (once in the database, once in your resolvers/code, and once in your API schema itself). This is the reason why the next-generation tooling in these ecosystems is predominantly implementation-first (or code-first) – patterns that leverage automation and prioritize efficiently heading to production with no downsides.
This is very much in line with our own analysis, from which the following objective conclusions can be drawn:
Automation based on metadata-driven approaches significantly reduces time to delivery as well as the costs of building a data access platform.
When using such automation, you are better off building your platform on the underlying databases as opposed to using any kind of middleware like APIs (certain safeguards like connection pooling, governance, etc. are needed to make this more palatable – something all metadata-driven low-code tools already offer).
So, why isn’t everyone building data access layers on their domain databases? Well, the tide is beginning to turn as you can see here (not an exhaustive list, and there are several similar tools in the developer ecosystem with their own users). However, some of these peers of yours had to work around some organizational challenges to make this happen.
Organizational structures and incentives
Domain teams are, by design, expected to operate in their own sandbox, supporting their suite of business applications or stakeholders. They have their own roadmaps, KPIs, and incentives.
When not designed well, platform initiatives are typically at odds with these incentives, creating additional work with no let-up in regular task deliverables. This is the biggest reason why platform architects are delegated to using pre-existing domain services (typically REST, increasingly RPCs), instead of collaborating on new and scalable designs.
You also cannot blame the domain teams – in the absence of a proof of concept of metadata-driven approaches in your own organization, there’s no benchmark to convince domain engineering teams to revise their positions. So, how does a platform architect proceed from here? Let’s take a look at some best practices.
Best practices for building data access layers on domain services
People
Executive sponsorship: Platform initiatives require executive sponsorship and endorsement. Better yet, if the domain teams report to the same engineering leader, this leader must publicly champion the initiatives and design incentives for the leaders of the domain teams. In other words, platform initiatives cannot be unsanctioned innovation crusades.
Collaboration: Platform initiatives must take domain teams along for the journey, preferably as early as possible in the design phase. Domain teams need to be proactive in allowing the organization to connect their domain to the data platform by partnering with platform architects, buying into the design early, and when success is demonstrated, championing the design to other domain teams. Starting small with 1-2 domains as proof of value is highly recommended.
Typically, enterprise data access platforms are federated systems (unless you choose to just centralize all your data, which only works for certain use cases and is generally not recommended at scale). Successful federation projects of any kind require cross-domain/team participation and collaboration. Ultimately, the success of such projects will come down to a set of people with a shared vision of innovation and how to achieve it.
Tooling
It’s important to talk about tooling before we get to processes, as your choice of tooling will determine the latter.
Federation vs. centralization: As we briefly alluded to in the previous section, pick a federated data platform approach that builds on existing domain data, without centralizing it. As architects dealing entirely with existing domain services, the temptation to get your own copy of data and then do as you wish might loom large, but one must resist it. Data transfer tech starts seamlessly but quickly becomes a nightmare. Domain data duplication results in governance headaches (data quality issues), lack of clarity about the source of truth, and the inefficient collaboration needed to sort these two issues out.
Exceptions to this rule Suboptimal data sources: If your underlying source isn’t conducive to arbitrary querying, you may want to explore virtual databases like Trino, etc., which can layer a more performant (materialized views) and accessible interface on top of unwieldy data sources. Scale: In certain contexts, like high-volume banking/FinServ, overwhelming scale dictates the creation of more queryable data copies in the form of operational data stores (ODS) or hot data layers, etc. It's also best to think about these performance improvement compromises as ephemeral data stores that can always be recreated from source data and are generated using a configurable approach. Caches are another example of this.
Automation, Automation, Automation: Platform initiatives are hard enough of a challenge to let go of any advantage that can be leveraged through automation. Pick architectures and tools that do the heavy lifting for you. The developer ecosystem has matured enough to recognize this and you’ll find plenty of options, both for individual sources/domains and for the platform layer itself. If your domain services have any kind of metadata, like OpenAPI specification, use it. If not, look at interesting patterns that allow you to infer this metadata from code that interacts with undocumented REST APIs, allowing you to automate the process of connecting these APIs to your platform.
Governance: Unifying your data is only the first step in building an effective, production-ready data platform. You’ll need to secure your data, be able to audit the use of your data, assess its quality, and enable some kind of data governance strategy. All this in addition to figuring out how to enable a virtuous cycle of data discovery and fulfillment.
Process: If you leverage modern tooling and automation, your process requirements become more straightforward. In essence, what we’ve described above derisks you from change, so you need fewer processes/workflows to support your platform.
Some key processes that you may want to implement regardless are:
Integration/regression testing: If you’re building a system on top of other systems, you’ll need to include some form of testing to ensure these two are in sync and that traffic to your platform isn’t disrupted by changes in an upstream system.
Data quality and use review: Remember the virtuous cycle of data discovery, fulfillment, and usage? Assuming your tooling supports data use auditing, there’s a lot of value in platform stakeholders reviewing the use of the platform and its met/unmet requirements.
Conclusion
Building a unified data access layer is one of the most critical requirements in the modern enterprise, and yet it could be an expensive proposition as well, with a high risk of failure. To get the most out of this investment, pick the best architecture and best tools. Make the tradeoffs that allow you to head to production first, demonstrate value, and iteratively improve your data access layer.
For some architects, this translates into proving success with a platform built on domain services, before leveraging this success to directly, safely, and securely connect domain data sources to the platform. Several migration and dual adoption patterns are available to make this transition. As always, the key is to take that first step.
In the next post in this series, we’ll look at a tutorial on how to quickly build a platform on a couple of sets of REST endpoints. To make things interesting, we’ll also connect one of the upstream data sources to the platform to compare and contrast the value from each type of source.
Ready to learn more? Get your copy of The data doom loop: Why big corporations are failing at data management.