Building Stateful Apps with Serverless Functions and Postgres
How should your serverless functions interface with a database to manage application state?
This post explores the different ways to deal with application state when writing business logic in serverless functions. We'll primarily use Postgres as the database when talking about these different approaches, and often use Hasura as one of the glue solutions between your serverless functions and your Postgres database. However, the ideas in this post are generic and can be carried forward to your favourite database solution.
TL;DR
Approach #1: Connect to Postgres directly from your serverless function
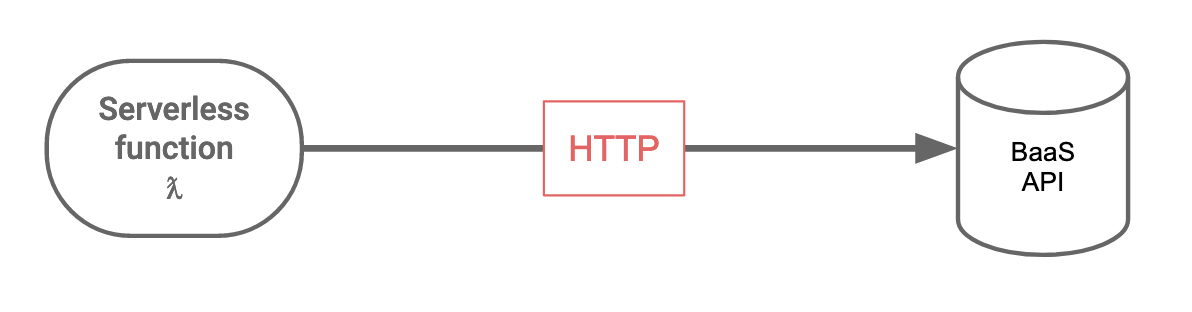
Approach #2: Use BaaS APIs from your serverless function
Approach #3: Trigger serverless functions on Postgres events with rich event payloads
Approach #4: Combine approaches above and use Postgres to orchestrate a workflow with the serverless functions driving state transitions
Introduction
Serverless platforms do not allow the developer to write code that holds any long-term state. This is because the serverless runtime is launched on-demand and is short-lived i.e. all the resources are deallocated after a request is completed.
These are few examples of things that you can't approach in the same way you did when you were writing a normal API server and may take for granted:
Writing to disk directly, like saving a file to a folder
A global variable that holds information across multiple requests, say a counter that keeps track of how many requests this API server has seen.
A database connection pool that your API server maintains with a database even when there are no requests
In this post, we explore some of patterns with real world use-cases which can help you in building your next app with serverless functions. Let's cover them one-by-one!
1. Connect to Postgres directly
The most common way to store application state for a server-side application is by using a database. However, connecting to a database directly from a serverless function naively is not the wisest idea, because while you can suddenly invoke a 1000 serverless functions, the database can't suddenly scale to creating a 1000 database connections.
Here are a few best practices to connect to Postgres to read/write data or run a database transaction from your serverless function:
Create a connection to your database by following the best practices from your cloud-vendor which helps serverless functions reuse a database connection across invocations (kind of like a connection pool):
Create your state in entirety at the beginning of the function.
This is to avoid executing multiple calls to the database which can incur performance cost as well as running cost. Gwen Shapira talks more about such database access patterns in this blogpost: https://thenewstack.io/managing-state-in-serverless/
Try to use an ORM-free data layer as much as possible.
This is because with ORMs, you need to define the data models first and you will have to do this for every function. This could mean writing lot of boilerplate and keeping all of them in sync with the underlying database. As you do this, you'll realise that you were better off writing a monolithic API server instead of serverless functions that were independent of each other!
Consider using good SQL clients or no ORM clients like massivejs.
Consider using an external connection pooling agent for your database like pgBouncer
If you are using DB transactions, then keep in mind the concurrency limits of your database. Transactions are costly and don't scale easily. Depending on your load, you may have to leverage a reliable external connection pooler like pgBouncer [0]. In fact, DigitalOcean provides its managed Postgres database with connection-pooling built-in [1].
2. Use BaaS APIs
One of the easiest ways to manage state is by not managing it yourself ? .
Backend-as-a-Service (BaaS) solutions abstract away some of the complex performance and concurrency concerns when dealing with persisting state. Your code in the serverless function uses HTTP APIs (stateless) and treats the BaaS solution like a black-box. The BaaS itself deals with actually managing and persisting state even as thousands of concurrent pieces of code might be reading, writing or modifying data.
Here are examples of BaaS services your serverless function might use:
S3 style APIs to read/write object or file type data. All major cloud vendors now provide a S3 API.
Hasura GraphQL APIs to read/write data from Postgres
Algolia to read/write to a search index and database
One of the neat things about using BaaS is that your function appears to be totally stateless. Consider the following code which uses Algolia to populate a search-index:
const algoliasearch = require('algoliasearch');
exports.function = async (req, res) => {
const data = req.body.book;
var client = algoliasearch(process.env.ALGOLIA_ID, process.env.ALGOLIA_KEY); //from env vars
var index = client.initIndex('book_index');
index.addObjects([data], function(err, content) {
if (err) {
console.error(err);
res.json({error: true, data: err});
return;
} else {
res.json({error: false, data: content});
}
};
As you can see, this function is essentially making one API call to a BaaS which does the heavy-lifting with state.
3. Trigger serverless functions on Postgres events with "rich" event payloads
Events are the underlying mechanism the cloud vendor uses to provision resources for a serverless function and then run it, by passing arguments to the function from the event payload.
If the event payload contains all the data and context necessary for the serverless function to run, then you don't need to read data from an external source.
This brings us to the third approach of writing serverless functions that need state. You can capture events from your database, like Postgres, and use them to trigger your serverless functions.
However, to be useful in a real-world context, these events need to contain all the related data and relevant context. Just the id or the operation (insert/update/delete) details are typically not enough.
A detailed event payload is more useful
In our case of working with Postgres, event payloads should typically contain:
Row data
Related data to the row (joined in via other tables)
Application user session information, if applicable
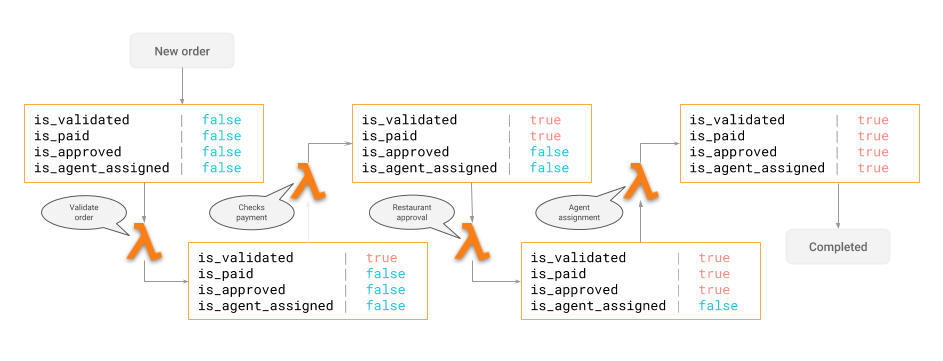
4. Postgres & serverless functions in a workflow as a state-machine
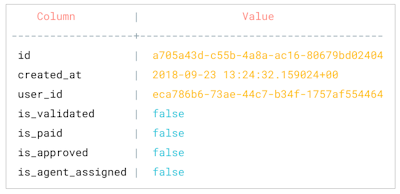
Most complex apps have workflows or progress via state-machine transitions in the backend. Consider a food-ordering application with the following data model:
Order table
The entire ordering workflow, comprising of important business logic steps like validation, payment, approval, delivery agent assignment can be thought of as a series of transitions to the state of the order table.
Orchestrating a workflow using Postgres and serverless functions
Each column in the order model can be considered to be updated by a specific serverless function that runs the complex business logic to actually make that transition appropriately and modify the state with more information.
This approach then becomes a mix of approaches 1/2 and 3:
Trigger serverless functions on database events (updates on specific columns trigger specific serverless functions)
Serverless functions can go and update state in the database while running their business logic via approaches #1 and #2!
Building stateful applications with serverless functions is not hard for most use-cases. The basic idea is to delegate the heavy-lifting to expert systems. Using some of the patterns described here, developers can extract the most amount of value in writing business logic in serverless functions.