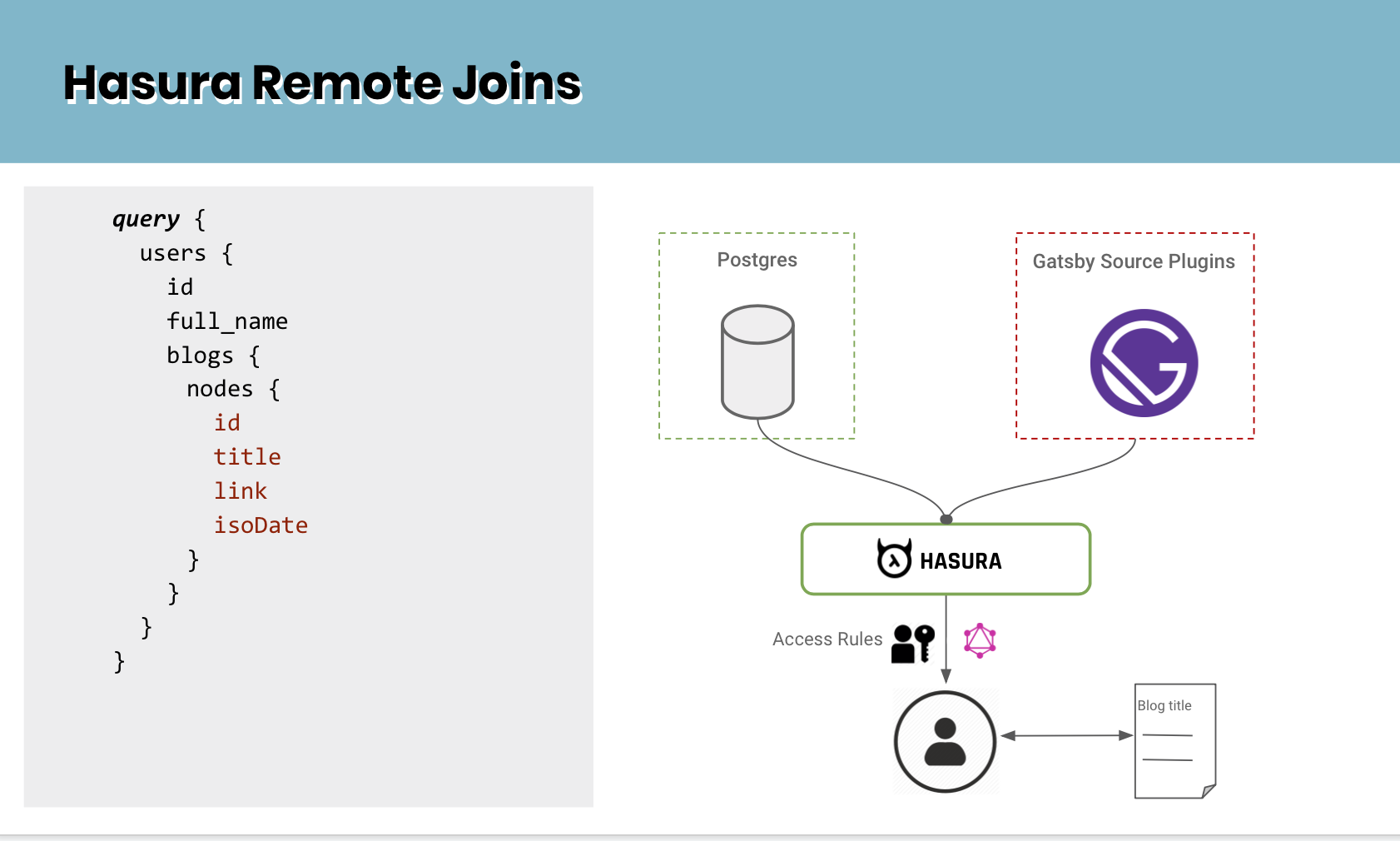
Data Federation in GraphQL using Hasura Remote Joins and Gatsby Source Plugins
This post is a part of our Remote Joins (available from v1.3) series. Remote Joins in Hasura allows you to join data across tables and remote data sources.
Before we dive into the actual use cases, let me introduce some terminologies and technologies being used.
What is Data Federation?
Data federation is a concept that allows for aggregating data from distributed sources together into a single, common data model but "pushes" down the execution to underlying sources. It doesn't contain the actual data. Instead, it contains metadata about where different data sources are located and how to fetch them on demand. Think of it as accessing a virtual database that contains all the data ever required for your application.
With Data Federation, there is a clear separation of concerns. Teams can independently work on their service and incrementally adopt federation. There are a lot of benefits that comes along but that's for a different post.
Hasura Remote Joins
Remote Joins in Hasura is the feature that enables Data Federation via GraphQL. Remote joins can join data across databases and other sources like APIs. These APIs can be custom GraphQL servers you write, 3rd party SaaS APIs, or even other Hasura instances.
GraphQL enables federation more easily by design, via a schema and a type system. In Hasura, you would declaratively configure your external data sources as Remote Schemas. You can then go one step further to connect these remote schemas with the database or establish relationships between different remote schemas.
The eventual goal is to aggregate every data requirement into a single graph that is type-safe, documented automatically and lets all clients access them with ease. Hasura becomes that Data gateway powered by GraphQL.
Gatsby Source Plugins
Alright, let's switch focus towards the example use case for this post - Gatsby Source Plugins. Gatsby allows you to pull data into your site using GraphQL and source plugins. The data in Gatsby sites can come from anywhere: APIs, databases, CMSs, local files, etc. Source plugins are written for different data sources by the community or by companies behind various SaaS APIs.
For example, the gatsby-source-filesystem plugin knows how to fetch data from the file system and the gatsby-source-contentful plugin knows how to fetch data from the Contentful source and so on.
Gatsby uses GraphQL to enable the app to declare what data it needs. All of your source plugins are merged to a unified schema. Though the catch is that, Gatsby uses GraphQL at build time and not for live sites. But they do serve the GraphQL endpoint during development. We are going to make use of this endpoint as an experiment to see what use cases open up.
Hasura Remote Joins with Gatsby Source Plugins
Try it out on Hasura Cloud
Alright. Let's try this out. Start by creating a project on Hasura Cloud. Click on the Deploy to Hasura button below, signup for free and create a new project.
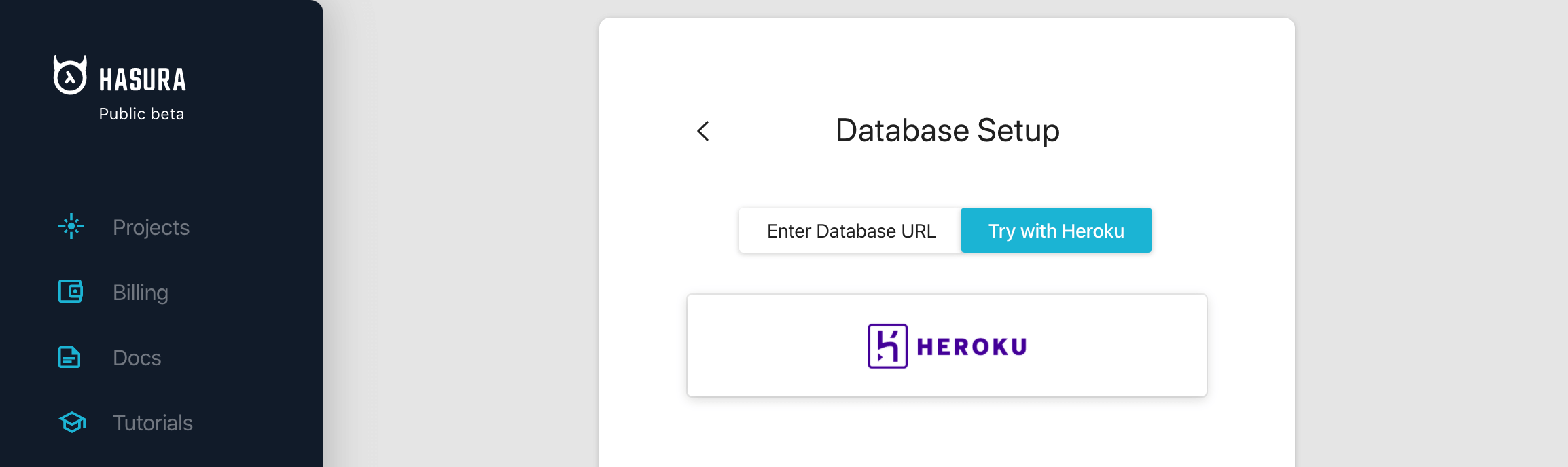
Hasura requires a Postgres database to start with. We can make use of Heroku's free Postgres database tier to try this app.
Setup Hasura with Heroku Postgres
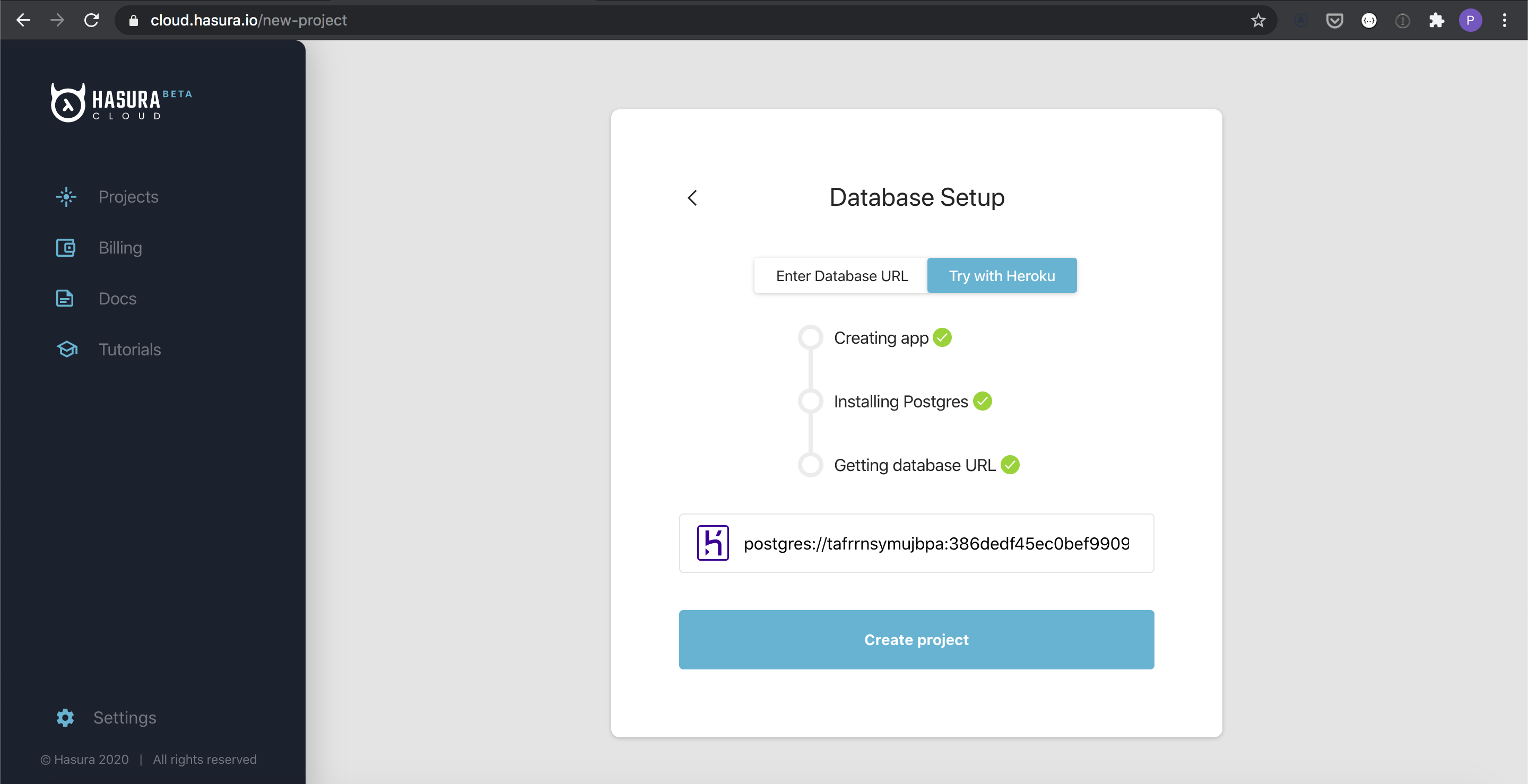
After signing in with Heroku, you should see the option to Create project.
Once you are done creating the project, click on Launch the Console button on the Projects page for the newly created project and the Hasura Console should be visible.
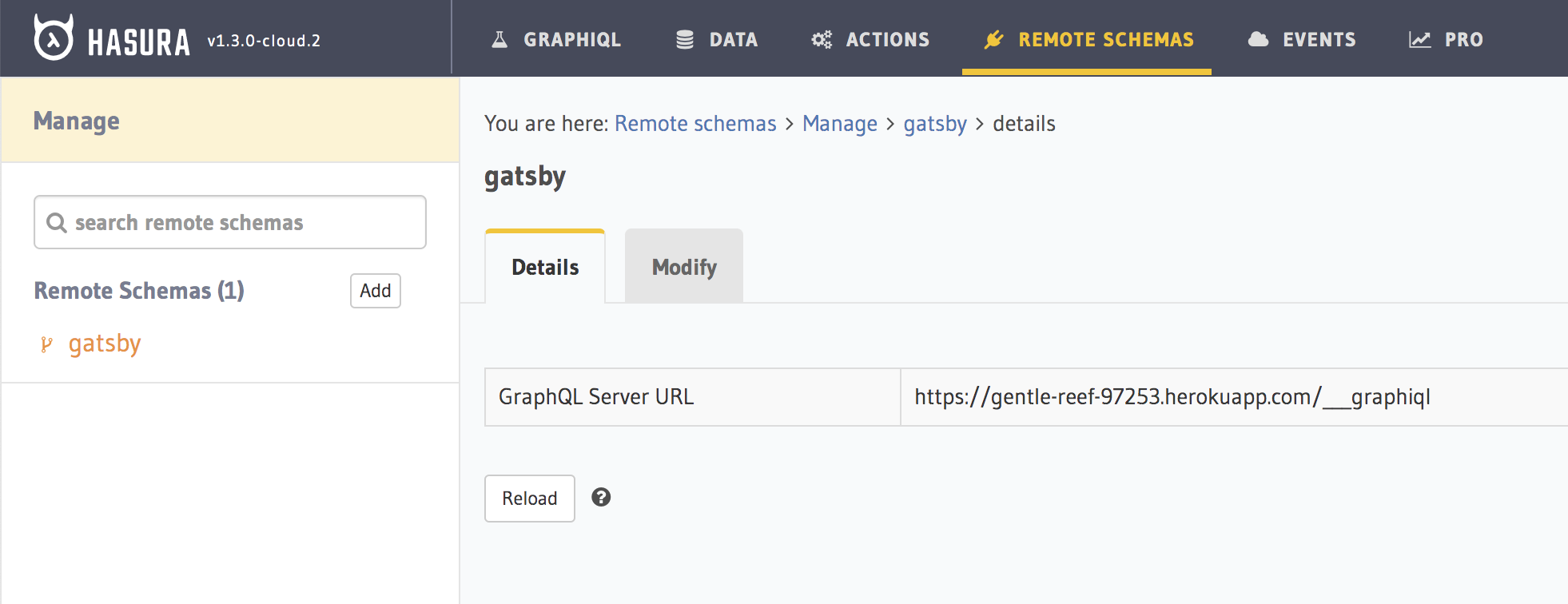
Add Gatsby as Remote Schema in Hasura
Gatsby serves their graphql endpoint at /___graphiql that loads the GraphiQL UI tool on GET request and works as a graphql endpoint on POST request.
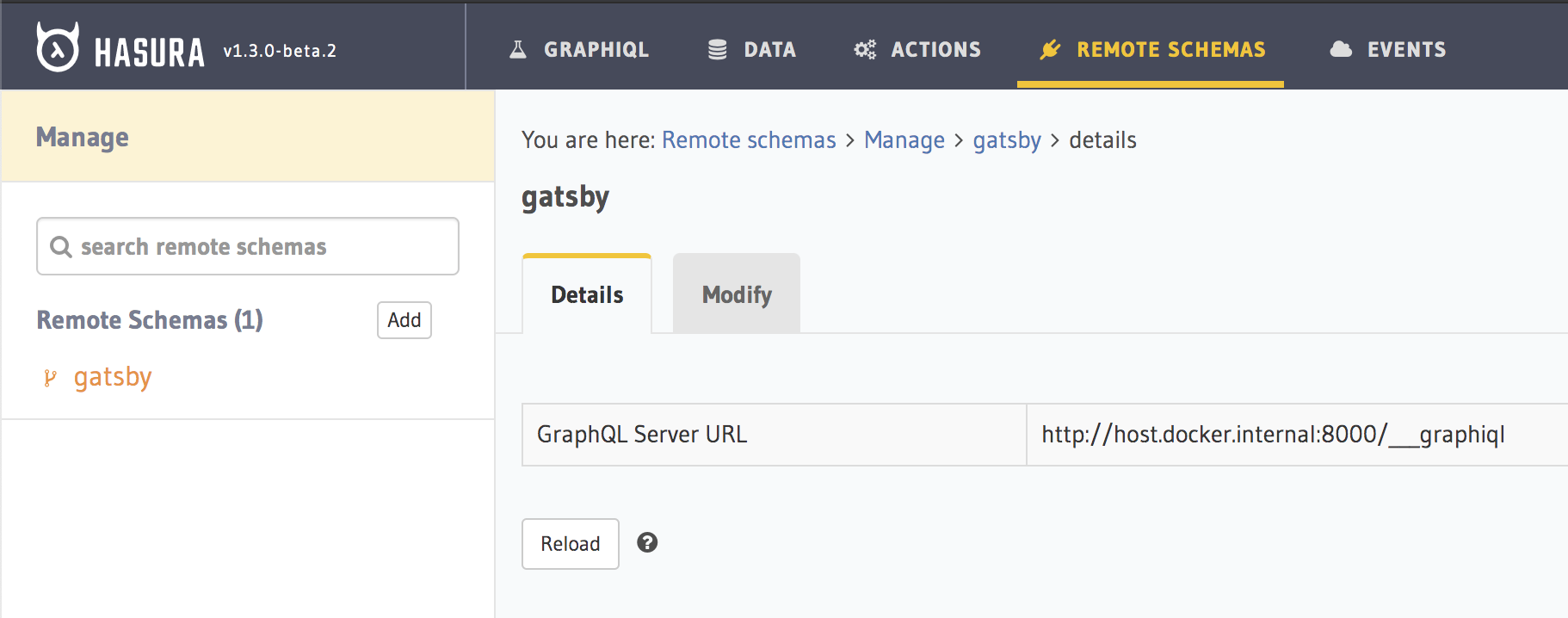
In Hasura, under Remote Schemas, we will add this endpoint to explore the different data sources added via Gatsby.
Deploy Gatsby Dev Server to Heroku
For Hasura Cloud to communicate with Gatsby's GraphQL endpoint, we will deploy the dev server of Gatsby on a public endpoint. Install the Heroku CLI.
On any Gatsby project, run the following commands to deploy on Heroku.
# create a heroku app
heroku create
# git push to deploygit push heroku master
This will create a Heroku app and deploy the dev server. The app starts by using the start script npm start as the entrypoint. Typically the start script for Gatsby is gatsby develop and that runs the dev server exposing the GraphQL endpoint.
Once you have the Heroku app deployed, copy the app URL and add the suffix /___graphiql . For example if your Heroku app URL is https://gentle-reef-97253.herokuapp.com, then the GraphQL endpoint for the same would be https://gentle-reef-97253.herokuapp.com/___graphiql.
You can add this endpoint as a Remote Schema in Hasura.
Gatsby Remote Schema added to Hasura
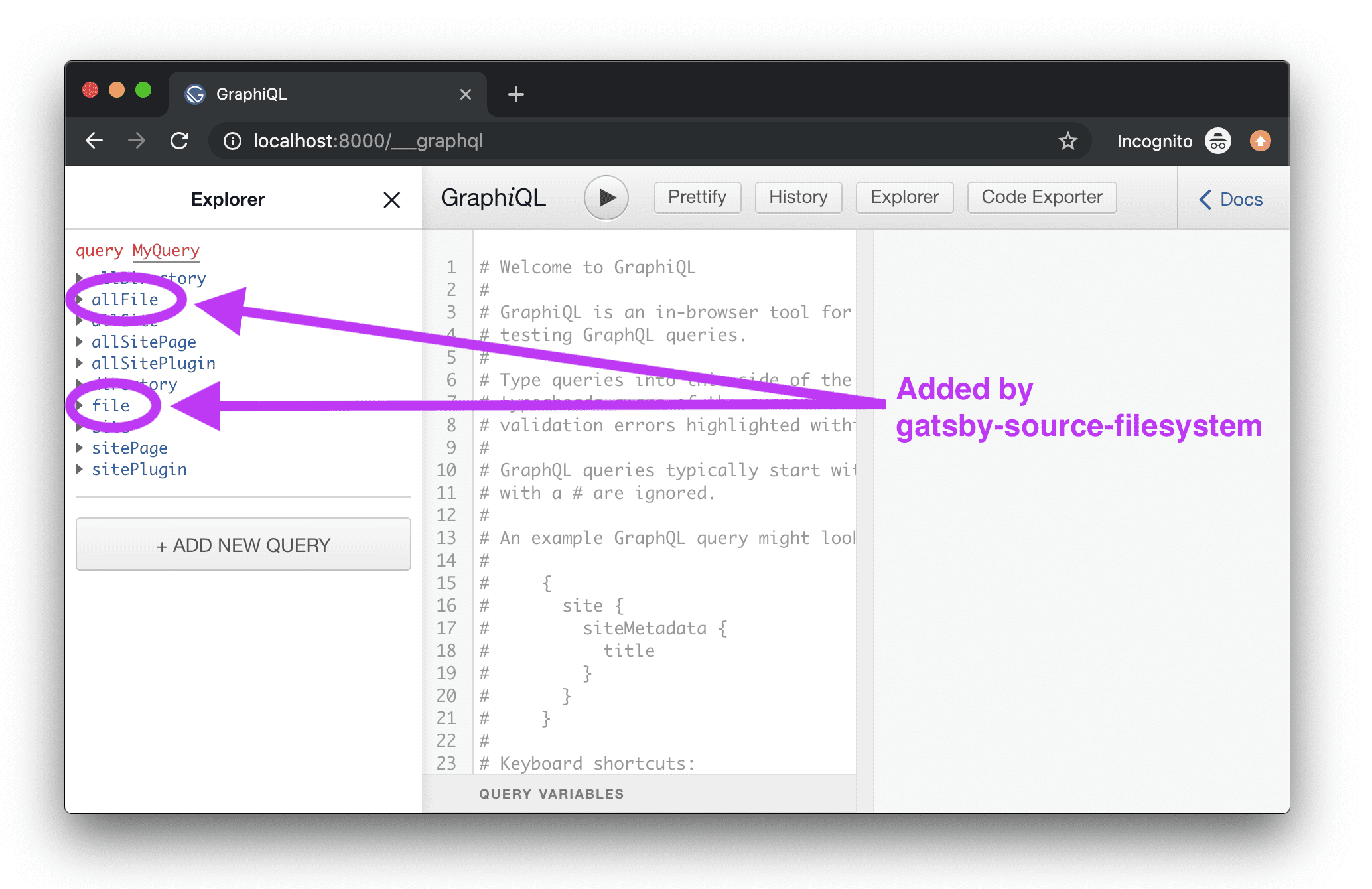
If you want to try out Hasura and Gatsby locally, run gatsby in development mode - gatsby develop and add the endpoint http://host.docker.internal:8000/___graphiql as the remote schema endpoint. (where host.docker.internal can be used in Mac and localhost for linux)
Gatsby Remote Schema in local dev
Use Cases
Let's look at some of the data federation use cases that are possible with Hasura and Gatsby's GraphQL APIs.
CMS Providers
Gatsby has support for lots of headless CMS options and lets you bring data from any of the popular providers. Here's a list of headless CMS providers that have a source plugin with Gatsby.
For example, Contentful has a source plugin. You can configure this with the following in gatsby-config.js
You can now join data from contentful with data in Postgres. Let's say you have a common id stored in both Postgres and Contentful for an entity product. You can now establish a relationship between these two nodes via the schema exposed by Gatsby.
Filesystem
The gatsby-source-filesystem creates File nodes from the files present in your local filesystem. In combination with transformer plugins, you can perform specific transformations, like using gatsby-transformer-json to transform JSON files into JSON data nodes and using gatsby-transformer-remark you can transform Markdown files into a MarkdownRemark node to get a HTML representation of the markdown.
Source: Gatsby Tutorial
In your gatsby-config.js you can add plugins and configure data sources. For example the filesystem plugin will have a configuration like:
Here, you specify which directory you want to create Nodes for and Gatsby will take care of the plumbing required to serve it via GraphQL.
Now under Hasura's GraphQL endpoint, you should be able to query this directly. This gets interesting, when you can map files to a user record in Postgres. Yes! This is where Remote Joins come in.
Remote Relationships
The users table has the following fields.
id
full_name
picture_path
Using the picture_path column, we can establish a relationship to the file query type in Gatsby's schema.
Cloud File Storage Access (S3)
The filesystem plugin gave you access to your local directories. There are also plugins to access files from cloud storage services like Amazon S3 and Dropbox etc. You will be using gatsby-source-s3-image for S3 and gatsby-source-dropbox for dropbox.
Using the file URL, you can access metadata about the file from S3. Again, a simple example; this can be joined with users data to get metadata about the user's profile picture.
Accessing Git repos
gatsby-source-git can be used to pull files from arbitrary git repositories. For example, you can make a query like
And get access to the repo's tree structure. The remote join can be used to merge blog posts written in markdown in the repo tagged to a user.
Git repo becomes the source of your markdown files and each user in Postgres is tagged to a set of markdown files as blog posts.
RSS Feeds
gatsby-source-rss-feed plugin lets you pull data from an RSS feed into Gatsby's GraphQL API. A user can subscribe to multiple blogs and data can be fetched from the subscribed blog. A typical query with remote relationship for this plugin will look like the one below.
With Hasura remote joins configured, you can make the above query to fetch the list of items in the feed. If you are following blogs of favorite sites, there will be a RSS feed for most blogs and topics. Since this is public data, it can be fetched on demand.
There are more such categories of source-plugins, like social APIs of Twitter/Facebook and content sites like Wikipedia that can be leveraged.
Caveats
The GraphQL API exposed by Gatsby only runs on a development server. Since Gatsby compiles a site into static assets, the production server doesn't expose or need to expose a GraphQL API to the client.
There's an RFC to add support for this by running an additional server using something like gatsby api-server. Until there is an official merge/release for that, you will have to run gatsby develop which might consume more resources and is probably not optimised for production. But from the limited experience of using this, it should be good enough for most small apps. If there's a complex use case, you might want to add some layer of caching.
The Nodes are created during the initial load of the gatsby server and the data along with it. In case there are updates, you might need to restart the server to reflect the changes and hence in a highly dynamic scenario this solution might not scale.
The gatsby dev server needs to be put in front of a proxy which will do basic token authorization. If you are self-hosting both Hasura and Gatsby dev server in the same cluster, you can choose to not expose Gatsby to the outside world.
Community supported solutions like graphql-gatsby is a decent alternative, where you can choose to run a custom Node server with direct access to Gatsby's GraphQL schema and resolvers. This also lets you configure some form of authentication between Hasura and Gatsby's server and you can continue to use Hasura Cloud.
Summary
GraphQL and its ecosystem enables Data Federation more easily than before. Gatsby source plugins opens up a lot of possibilities to add data sources from different places and makes it an interesting combination to federate data using Hasura remote joins.
Gatsby's plugin ecosystem is huge with over 2000+ plugins of which 600 are source plugins alone. Do note that, this approach is more or less an experimentation till we have an official and stable api-server from Gatsby or the community.
What kind of Gatsby Source plugins are you using the most? Which data federation use-case do you think will be relevant for you to perform with Hasura and Gatsby? Do let us know about it in the comments!