Introducing Instant GraphQL APIs for Snowflake Cloud Data Platform
Real-time access to data is essential for building modern applications. However, as the data footprint in an organization grows and spreads, it creates unique challenges for developers who need to aggregate data across multiple sources and develop the necessary APIs to securely and efficiently access and serve the data required to power their applications.
To help development teams with these challenges, we're excited to announce the beta release of our new GraphQL Data Connector for Snowflake. This powerful new database integration will allow Hasura users to instantly create a unified GraphQL API that runs read-only queries across all your Snowflake data. Hasura drastically reduces the time and effort required to build and secure data APIs, allowing teams to quickly power their analytical applications with data aggregated in Snowflake.
Important - This beta release of the Hasura GraphQL Data Connector for Snowflake supports read-only queries. During the beta period, the connector is available for Hasura Enterprise Edition (EE) and all Hasura Cloud customers. Once this integration moves to General Availability (GA), it will only be available in the Hasura Enterprise plans. For more information, read our docs.
What is Snowflake?
Snowflake, often referred to as a Cloud Data Platform, provides a way to bring together and easily access data siloed across multiple sources. Snowflake enables elaborate application development, collaboration, and more across a wide spectrum of data sets, all in the cloud. This provides massive horizontal scalability along with other capabilities that meet a wide variety of application, reporting, and other data consumption needs.
Building Applications with Snowflake and Hasura
Hasura customers across many industries, such as construction, energy, financial services, healthcare, and human resources, use Snowflake to house critical data needed to derive insights and make data-driven business decisions. Many of these customers also use or want to use Snowflake data to directly power analytics in internal and external data applications. Or they want to open their Snowflake data – in a safe and controlled way – to internal or external stakeholders to make data-driven decisions. However, this journey has some challenges.
The resource-intensive nature of building an API, especially if they intend to build multiple apps and services that use data from Snowflake.
Customers have to maintain and manage secure connections to Snowflake so only the authorized individuals and applications have access to this business critical data.
To address these challenges, our new integration with Snowflake helps by:
Providing an instant GraphQL API on Snowflake to access data securely.
Providing a unified GraphQL endpoint across Snowflake and other data sources such as PostgreSQL, SQL Server, BigQuery, Amazon Athena and CockroachDB. GraphQL is an extremely flexible query language for APIs and a runtime for fulfilling those queries with your existing data.
Bringing Hasura's out-of-the-box capabilities to Snowflake, such as:
a. Query response caching allows you to cache responses in Hasura for frequently executed queries as opposed to retrieving the data from Snowflake every time. This greatly improves application performance and consequently your end-user experience.
b. Declarative authentication and authorization
c. API Security
d. Integration with your custom REST API application workflows via Actions and Event Triggers
e. Observability to ensure the reliability of your application stack
The new data connector for Snowflake introduces new ways to query, correlate and aggregate data, enabling Snowflake customers to do more with their data and increase the ROI on their Snowflake investments across the board.
What Can I Build with Hasura and Snowflake?
We’ve seen some really creative use cases that are only possible by integrating Hasura with our new Snowflake database connector. Below are a few examples to explore with your team.
Surface Analytics Data in Customer-facing and Internal Apps
Embedding analytics directly into applications is not only creating great user experiences, but it’s also helping teams build a competitive advantage. Quick and efficient data access is essential for building applications like an internal customer service dashboard that surfaces real-time analytics and helps deliver world-class customer support. With Hasura GraphQL, development teams can quickly build a unified API for Snowflake that efficiently serves up data from multiple tables, all within a single query, instead of making multiple fetches to individual tables. This saves developers countless hours of writing additional APIs and queries required to surface data from Snowflake.
Share Snowflake Data with Internal and External Consumers via APIs
In an effort to be more data-driven, organizations want to open their Snowflake data to more internal and external stakeholders, giving them the data they need to make better decisions. But given the critical and sensitive nature of the data often stored in Snowflake, organizations are often hesitant to do this through typical built-in connectors (eg. JDBC) and prefer to share just the data they want via APIs. API services allow them to provide data access in a secure, controlled, and limited way. With the Hasura connector for Snowflake, customers can now generate those APIs in a fraction of the time it would have otherwise taken to build. With the built-in Hasura authorization engine, customers are also able to easily implement access privileges into the API layer.
Combining Data from Snowflake with Other Sources for a Unified API
While Snowflake is often used as a central data warehouse, large organizations can still have critical data stored in other locations for a variety of reasons. Architecture or security designs, legacy databases that have yet to be migrated, or siloed business units can all lead to data being stored in locations outside of Snowflake. This poses a challenge when building applications that require data across those multiple sources. Hasura GraphQL creates an easy and efficient way to combine Snowflake data sources with additional data sources. For example, maybe a company needs to map order data and shipment data during order fulfillment. Combining these data source silos drives better product insights for things like returns, quality issues, and buyer profiling. all through a singular unified API.
What’s Included in the Snowflake Connector Beta?
The Hasura connector for Snowflake currently provides query support only, along with a host of other standard Hasura features called out above. For example, connecting two tables is a standard Hasura feature that really stands out when working with denormalized reporting data that is often used in Snowflake. For a full list of capabilities, visit the documentation.
How Can I Get Started?
To get started, you will need
An existing Snowflake account instance and data to connect Hasura to query against.
A Hasura Cloud or Hasura Enterprise Edition self-hosted setup - version 2.16.0 or later.
While the Snowflake connector is in beta, it is behind a feature flag. Please follow the steps outlined in the documentation to learn how to enable it.
Navigate to the Data tab as shown and click on Connect Database. The following dialog requires four steps:
Select Snowflake (beta) from the dropdown. This will then shape the rest of the connection form elements for the appropriate data needed for the Snowflake connection.
Set the name you’d like the connection to be listed as.
Add the JDBC connection string to your Snowflake instance. The JDBC connection string will need the URI path with credentials, warehouse, database, role, and schema added to the string. It would look something like this.
jdbc:snowflake://[URI instance to connect to]?user=[theUser]&password=[superSecretPassword]&warehouse=[THE_WAREHOUSE]&db=[the_db]&role=[role_like_PUBLIC]&schema=[schema_to_use]
Once those steps are done, click on Connect Database.
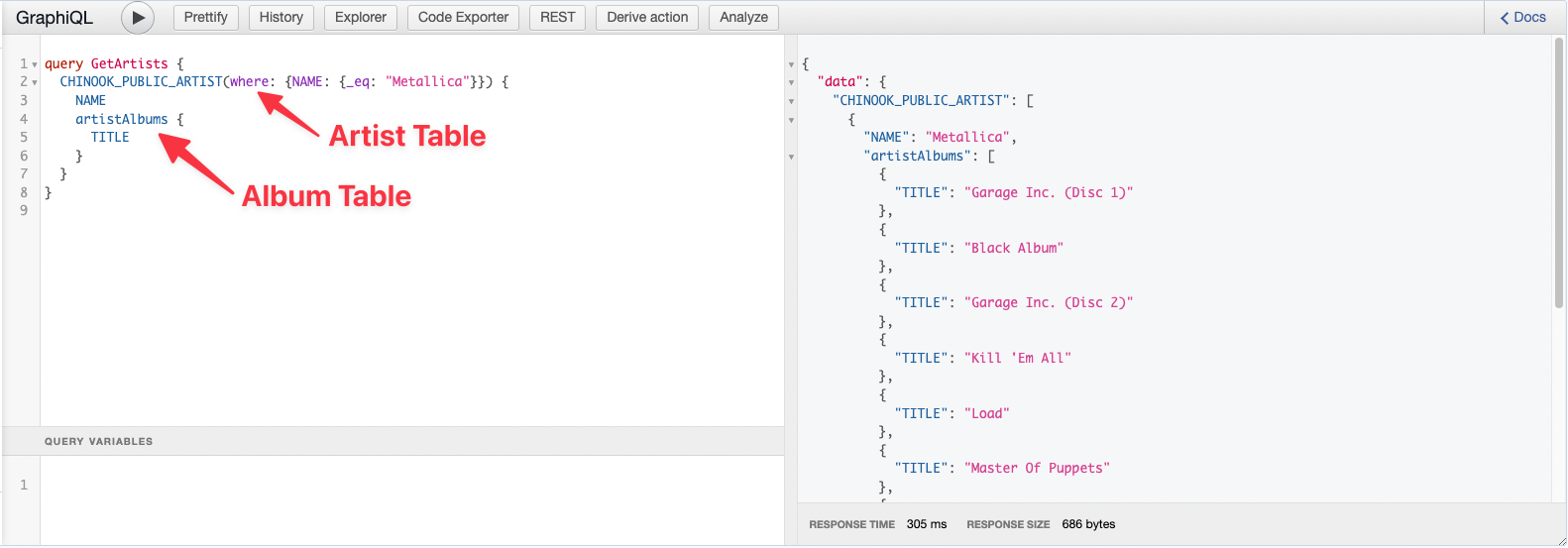
From there, you can select tables and query against those tables just like you would in any Hasura GraphQL API connected database. Let’s say, for example, you want to query a band along with the band’s albums. That query would look something like this, with the inferred nested object of albums returning as an array.
Correlative data across disparate tables within reporting tables are difficult requests to process. With Hasura connected to Snowflake, users can easily add relationships between tables to bring data together into a single GraphQL Query.
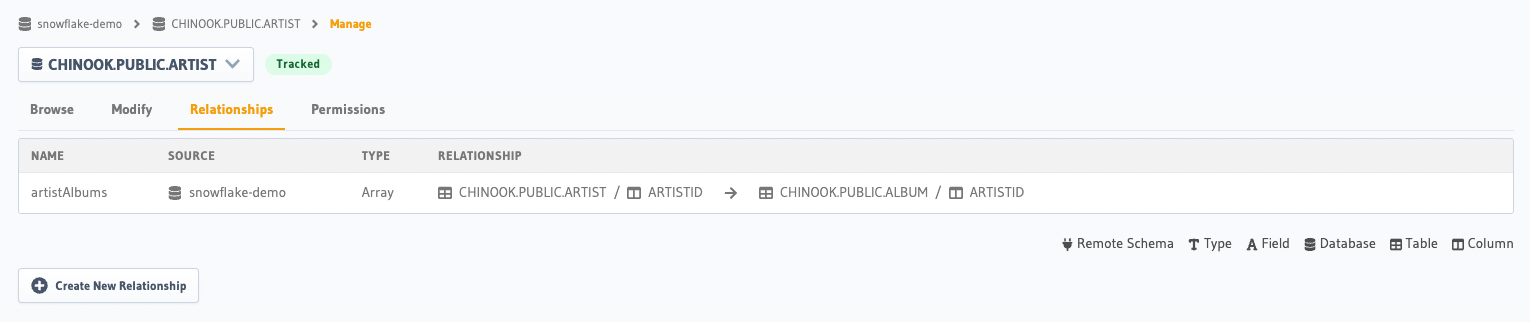
A tactical example can be seen with the relationship shown in the console here. In this example, we have a music library database where we are trying to define a relationship between the Artist and Albums table.
Hasura connects the Artist table to the Album table so that a relationship can traverse either direction when querying.
The following query shows how a nested query works based on that relationship, adding power to queries when working with Snowflake. Users now have multiple queries issued from a singular GraphQL query. Thereby reducing your query complexity, keeping the number of client calls minimal, and improving the readability of your code base.
Adding caching is extremely easy. For example, using the query listed above, we can add the directive as shown.
We are hosting a live webinar on this topic on Jan 11, 2023, where we will do a technical deep dive on the connector, cover use cases, and more with a live demo. It’s a great opportunity to connect live with the technical team behind this capability. Register here.
Want to see a custom demo sooner? Get in touch with our team by signing up here. Put in “Snowflake demo” in the notes, along with more context of your use case for Hasura+Snowflake.
What’s Coming Next
A reminder, this is the beta release, and we’re moving quickly to add new functionality for Snowflake as well as support for additional connectors. In the coming months, we’ll be building features like GraphQL mutation support for our API, and Snowflake will be one of the first connectors to receive that update.
If you’d like to discuss Snowflake, request new features, or just ask questions about Hasura and Snowflake, join our Discord.