HasuraCon'21 - Cross Database Joins with GraphQL and all the other exciting announcements
If you haven’t heard, today is the start of HasuraCon (our annual user conference). Tanmai Gopal (CEO and Co-founder) has just dropped all the major announcements as a part of his keynote address entitled I want data; I want it now. The future of application development.
In the keynote, Tanmai talked about the evolution of data access over the years and our mission at Hasura to make data access simple, fast and secure (irrespective of where your data lives), and with a developer experience that you will love!
Here is everything we are announcing today, and we have detailed demos for each of the product announcements over the 2 days of our conference.
Hasura 2.0 is stable
Cross Database Joins with GraphQL
Schema Sharing
Git based CI/CD workflows on Hasura Cloud
Oh, and lest we forget, Hasura GraphQL Engine just crossed 250,000,000 (yes, that is millions!) downloads in less than 3 years!
2.0 Is Stable
Firstly, and with all gratitude to our community, we have officially released Hasura version 2.0.0. This marks the ‘stable’ release of the 2.0 train.
If you want to get started right away, the 2.0 upgrade guide is in the docs.
Here is a recap of what Hasura 2.0 brings:
Connecting multiple databases simultaneously:
Hasura 2.0 allows bringing in multiple databases simultaneously to a single instance of Hasura GraphQL engine (or a scaled up cluster of Hasura instances). Instead of having to supply a single env var, you can now add and remove database sources ON THE FLY on a running Hasura instance!
Hasura 2.0 also marks a major underlying architectural change to set up the foundation of adding more databases to Hasura. Today Hasura supports Postgres, SQL Server and Big Query (beta), and multiple instances of any combination of these. You can read about the engineering behind this here.
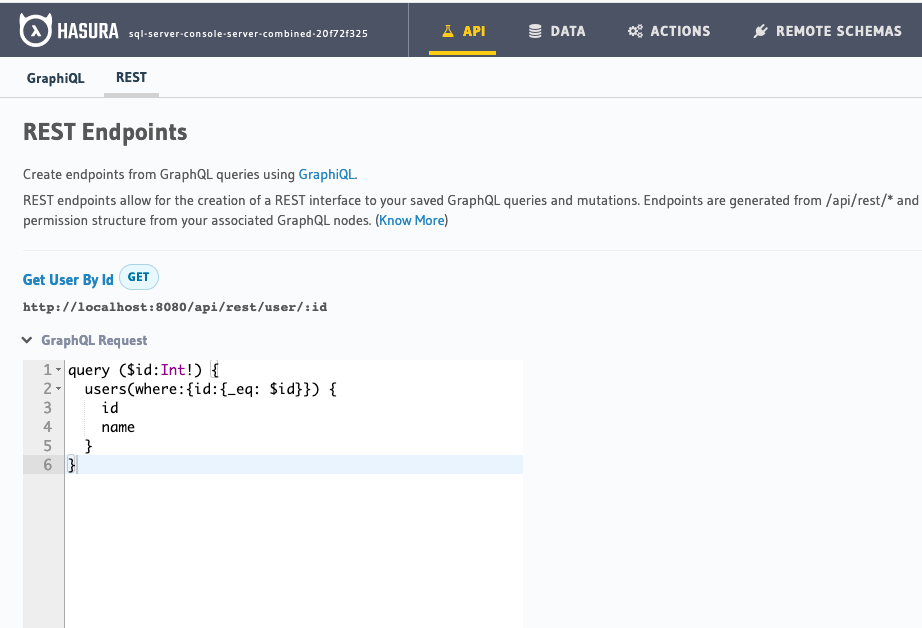
2. Support for REST, in addition to GraphQL, for the user facing API
Organisations have REST APIs, and these aren’t going away anytime soon. With the support for REST, you get the best of both worlds - GraphQL’s advantage of self-serve consumption of data with a single API endpoint, as well as the ability to convert the perfect GraphQL query to an idiomatic REST endpoint such that you can integrate with your existing REST tooling, support external vendor APIs and not have to maintain multiple API engines forever.
Create a REST endpoint from a GraphQL query template
3. Authorization engine enhancements:
Hasura contains a sophisticated authorization engine - very similar to RLS style authorization in the database world. With 2.0, we added 2 key capabilities to our authorization engine:
Authorization on remote GraphQL services (your own GraphQL services or external GraphQL APIs you don't own).
Support for inherited roles, to compose multiple roles (fine-grained RLS or ABAC style policies) together on the fly.
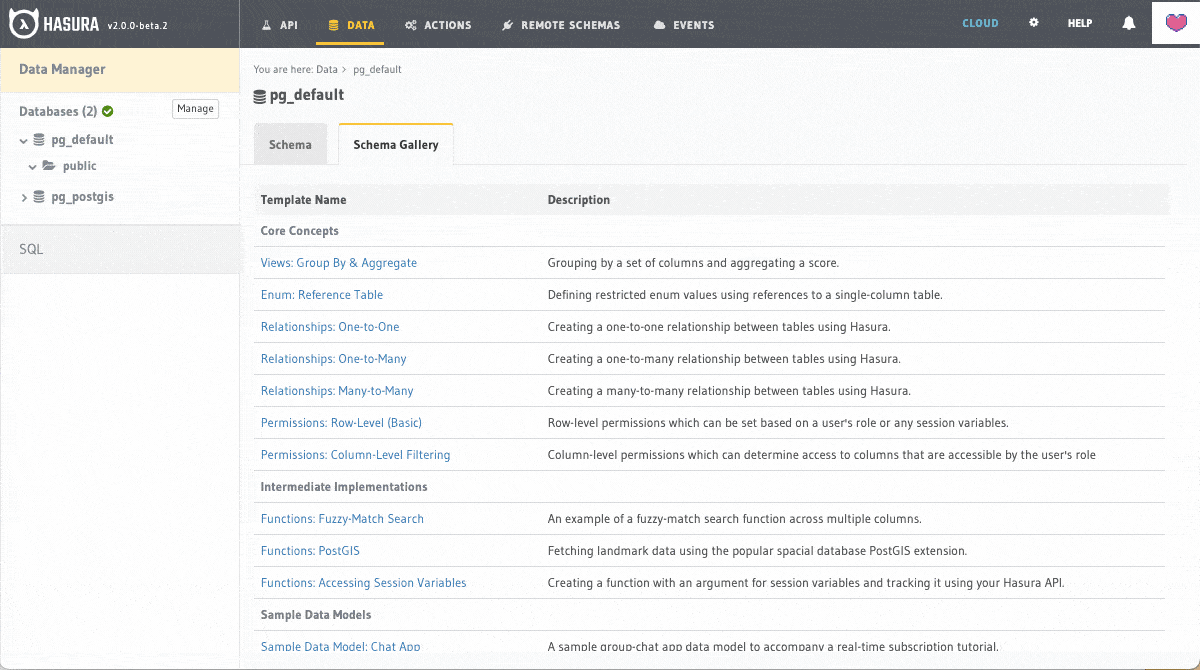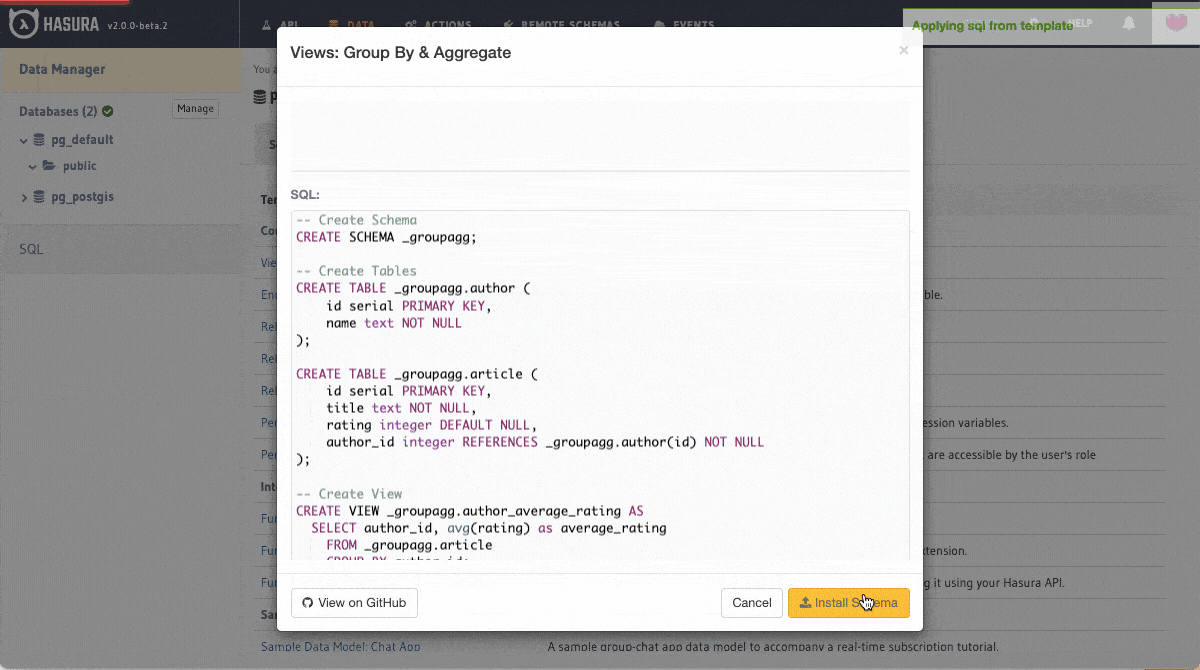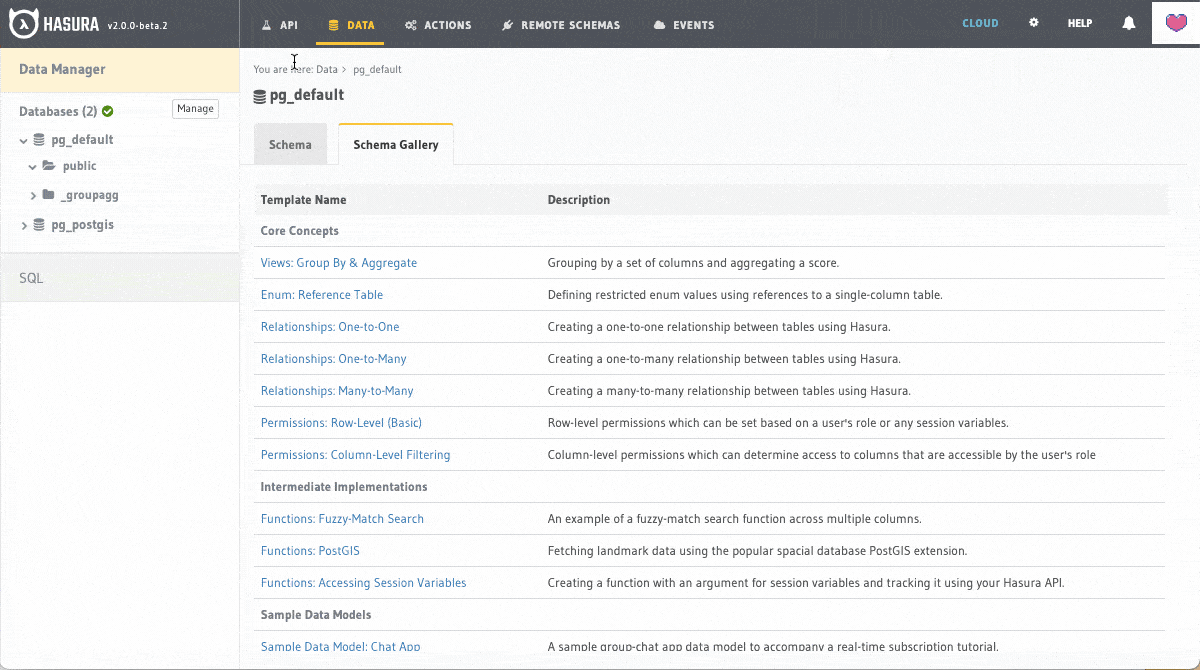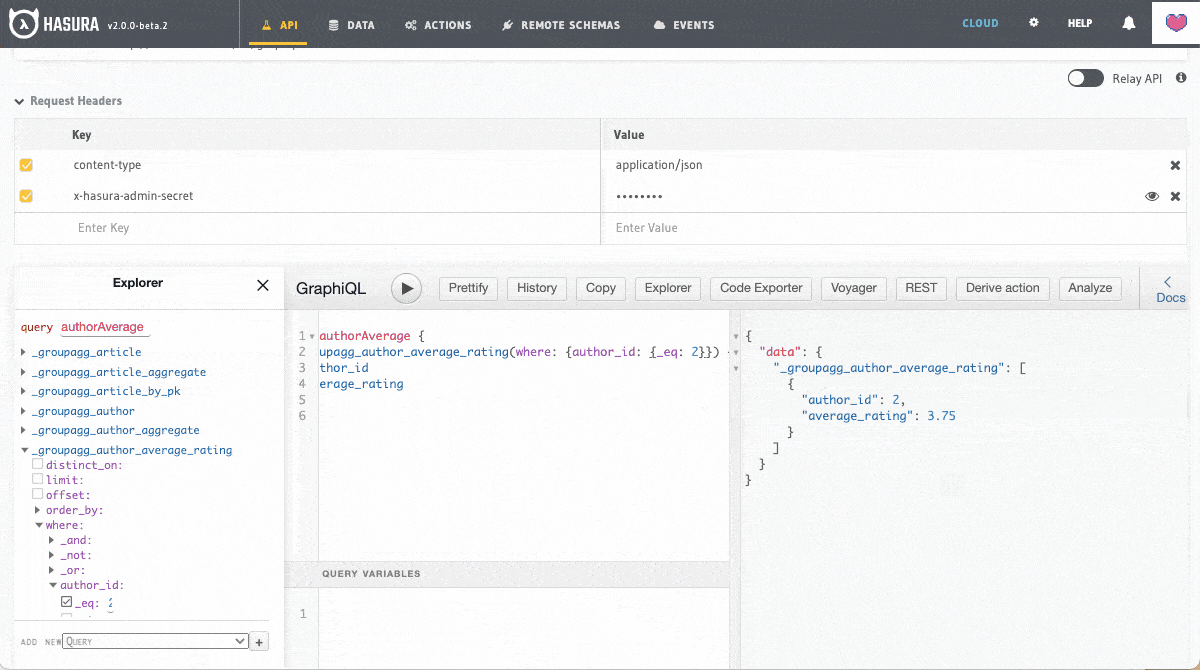
Cross Database Joins with GraphQL
Data is everywhere and is usually stored across multiple databases and data sources. Different teams in an organization might have their own database. Different types of workloads could mean that you have specialised databases for specialised use cases. In enterprises there is often a mix of legacy databases as well as modern ones.
We introduced Remote Joins last year to join across databases and remote GraphQL servers.
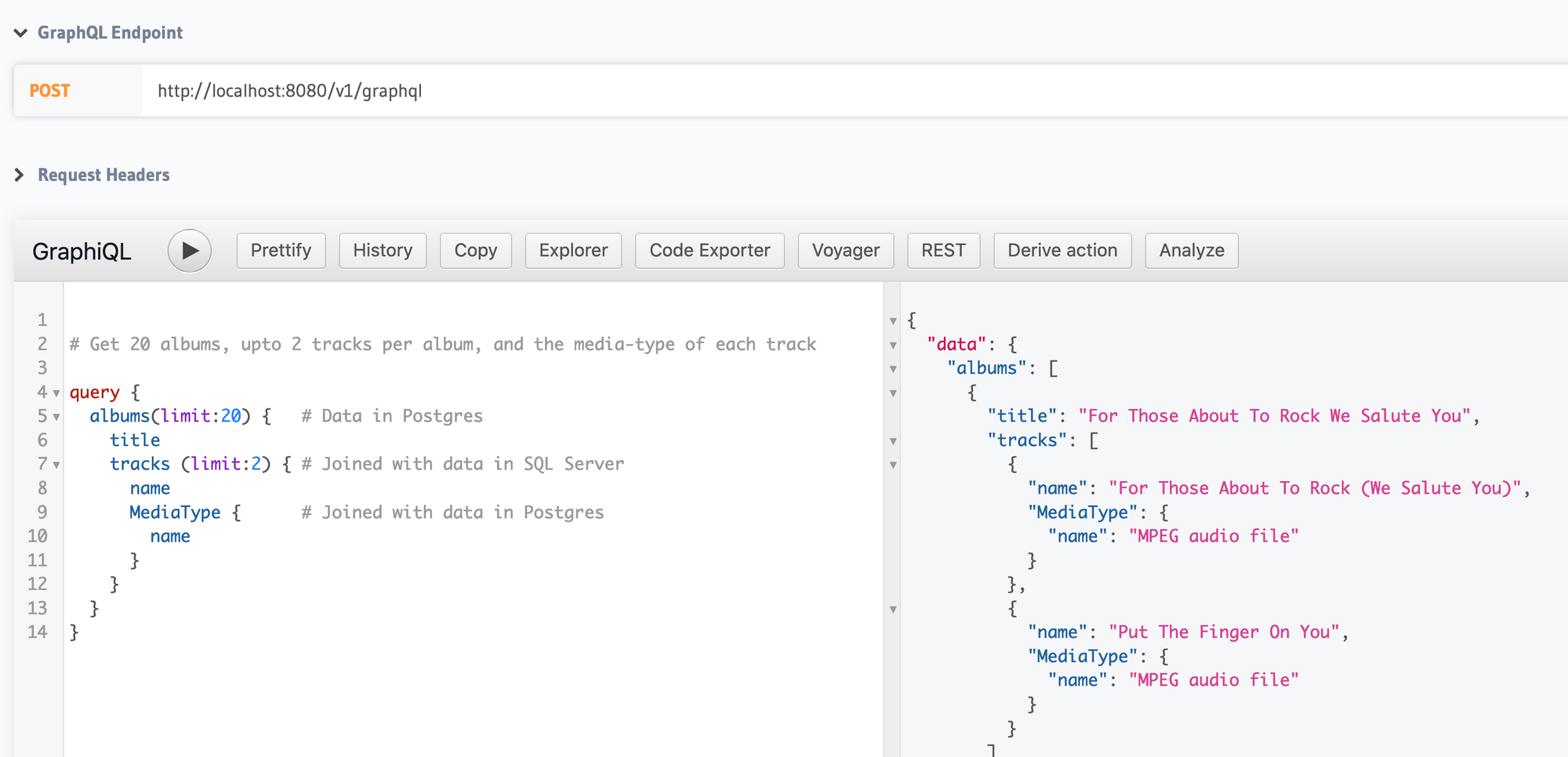
With Cross Databases Joins at the API layer, we have taken Remote Joins to the next level. All you have to do is configure Hasura to connect to your databases and, with no upstream changes to the underlying database, you can start querying across them!
With a single GraphQL query, Hasura will let you fetch related data from multiple databases with authorization baked in. Hasura federates the GraphQL request to the underlying databases giving you the experience of all the data being in a single database!
A single GraphQL query can be used to fetch data across multiple databases
Join the detailed talk about this feature at 10:20 PST: https://hasura.io/events/hasura-con-2021/talks/the-evolution-of-remote-joins/
Schema Sharing
What did you do when you loaded up your first Hasura project? Maybe you created a sample table, were following a tutorial, or tried implementing a feature. With schema sharing we're bridging the gap for beginner -- and power -- Hasura users by bringing installable samples of permissions, relationships, and advanced Hasura features; as well as data models, logical implementations, and extension examples. With these installable schemas you and your team will be able to not only get up to speed with Hasura, but also be able to embrace the power of the database that runs through your API.
Schema Sharing in Action
Make sure you attend Martin’s talk at 10:50 am PST today to see this in action: https://hasura.io/events/hasura-con-2021/talks/hasura-schema-sharing/
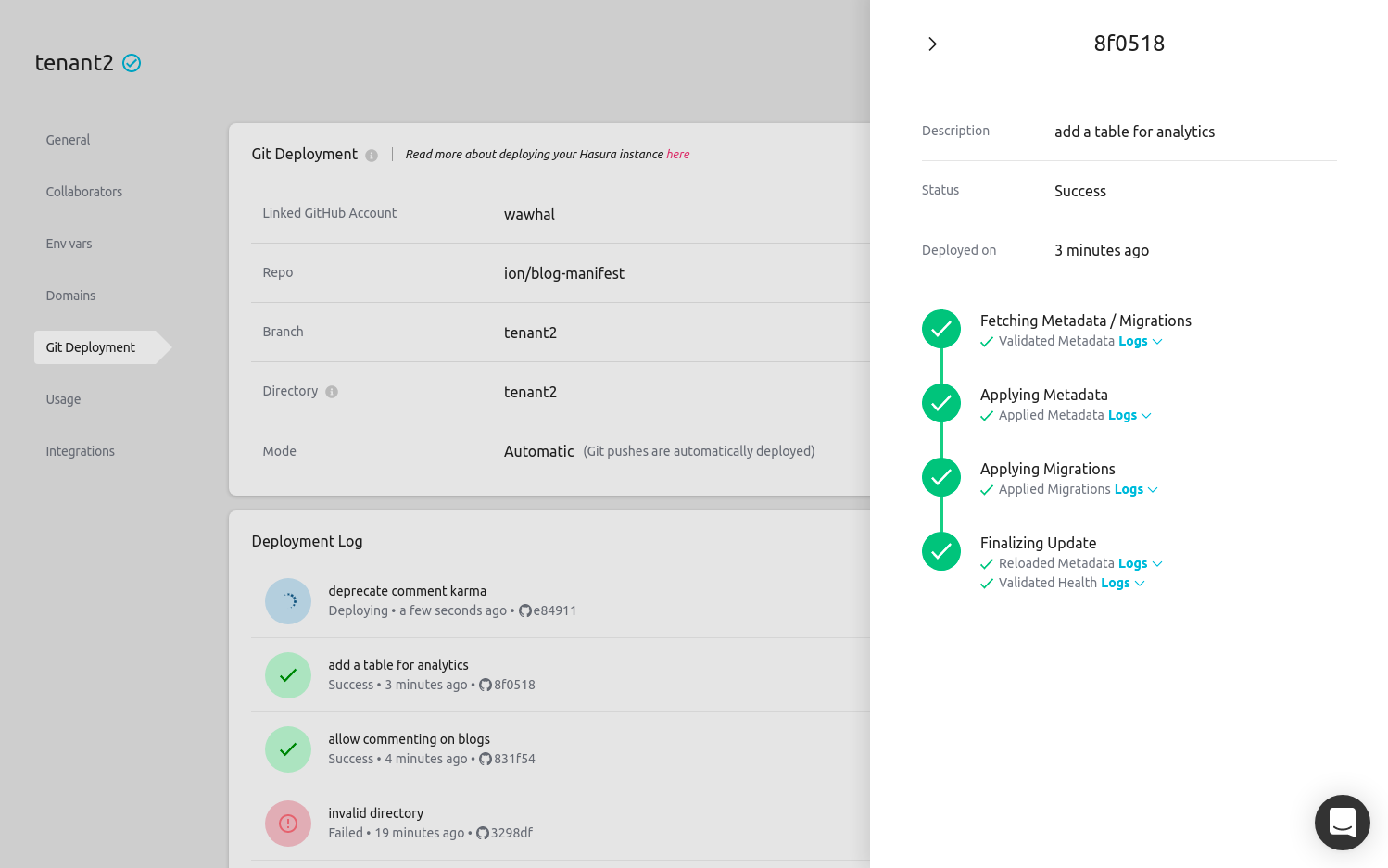
Git-based Workflows for CI/CD on Hasura Cloud
From development to staging to production, we all want to automate everything that can be automated. With this feature on Hasura Cloud, you can deploys your local migrations to staging and production by a simple git push. You can also get preview apps for every main pull request on your git repository.
Automatic GitHub deployment with Hasura Cloud
Attend Rishi’s talk at #HasuraCon tomorrow at 9:30 am PST for all the details & the demo: https://hasura.io/events/hasura-con-2021/talks/ci-cd-and-hasura/
Stories about Hasura in Production
We have a super packed agenda with many technical deep dives from our engineering and product teams! We also have users & customers of Hasura talking about how they’re using Hasura and their experience in production! If you join HasuraCon (and there is still time) you too can find out how Hasura is powering applications at startups & Fortune 500 organizations.
Building & Scaling Pipe: In this fireside chat, Rajoshi will be speaking with Peter (Director of Engineering) & Yasmin (VP of Marketing) from Pipe about their growth from the lens of building & scaling their tech, team and culture.
Modernizing a 30 year old stack at the US House of Representatives: We have Andrew, Adam and Glenn from the Office of the Clerk at the US House of Reps speaking with our co-founder & COO Rajoshi about how they have modernized a legacy system with GraphQL & Hasura.
Here is the full agenda for the 2 days of talks at the conference! Join the conversation using the #HasuraCon.