In this post, I’m going to talk about the product vision of Hasura, our technical design philosophy, how Hasura compares to other technologies in the landscape and finally some FAQs about Hasura.
If you just want to start quickly, then our Hasura Tutorials provide tutorial content across a variety of frontend frameworks, Hasura backend tutorial, and also an introduction to GraphQL fundamentals.
At Hasura, our mission is to make application development faster than ever before. As the technology landscape today evolves, we believe the key bottleneck that needs to be addressed is making data accessible.
Especially in enterprise environments, adopting best-of-breed technologies, modernizing applications or building new capabilities is critically dependent on being able to work with online/realtime (OLTP) data.
Two important trends have emerged over the last few years:
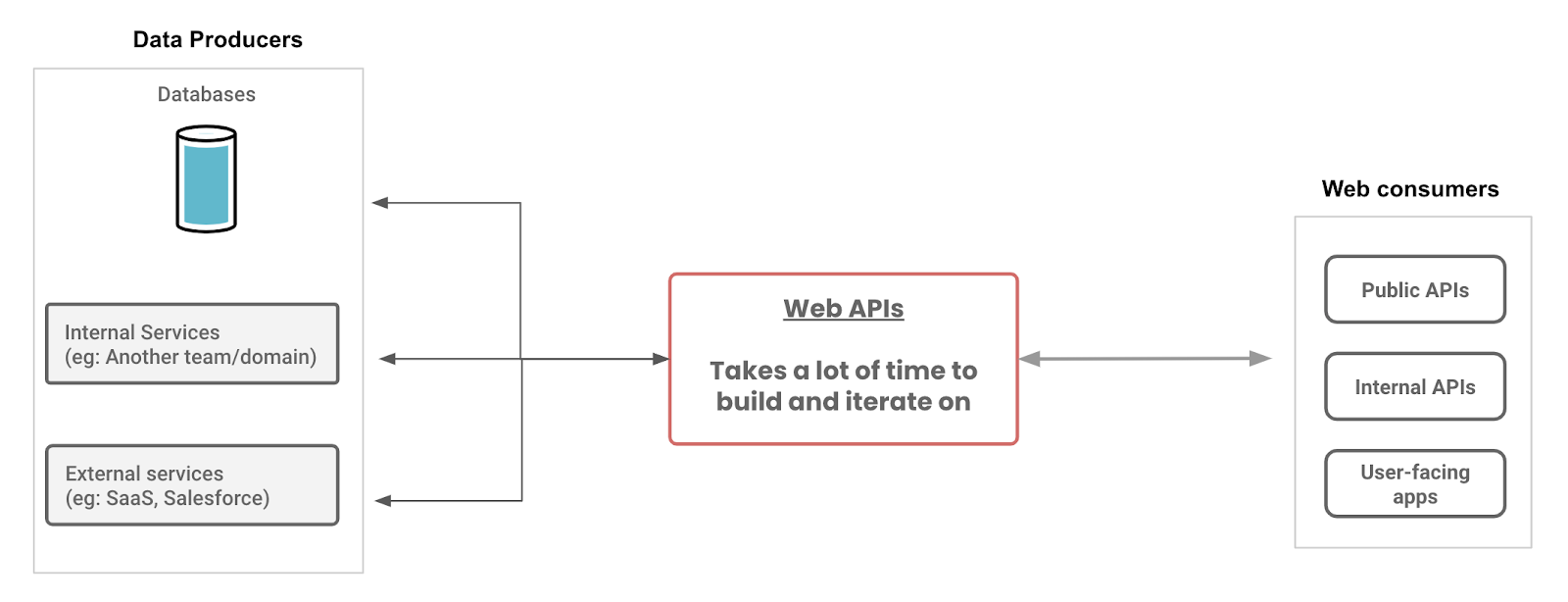
Data is no longer in a single data-source. Operational data is increasingly split across multiple sources viz. workload-optimised databases, SaaS solutions and even internal services
Developers are consuming data in insecure & unauthorized compute environments (eg: web/mobile apps) and increasingly stateless & concurrent compute environments (eg: web/mobile apps, containers, serverless functions).
This necessitates building a data API that is able to connect to multiple data-sources, absorb some domain-specific logic, and provide the required security and performance/concurrency.
This is tedious work and a solid time-suck. It is work that is semi-repetitive (eg: integrating different sources, exposing CRUD APIs) and also simultaneously domain specific (eg: authorization rules).
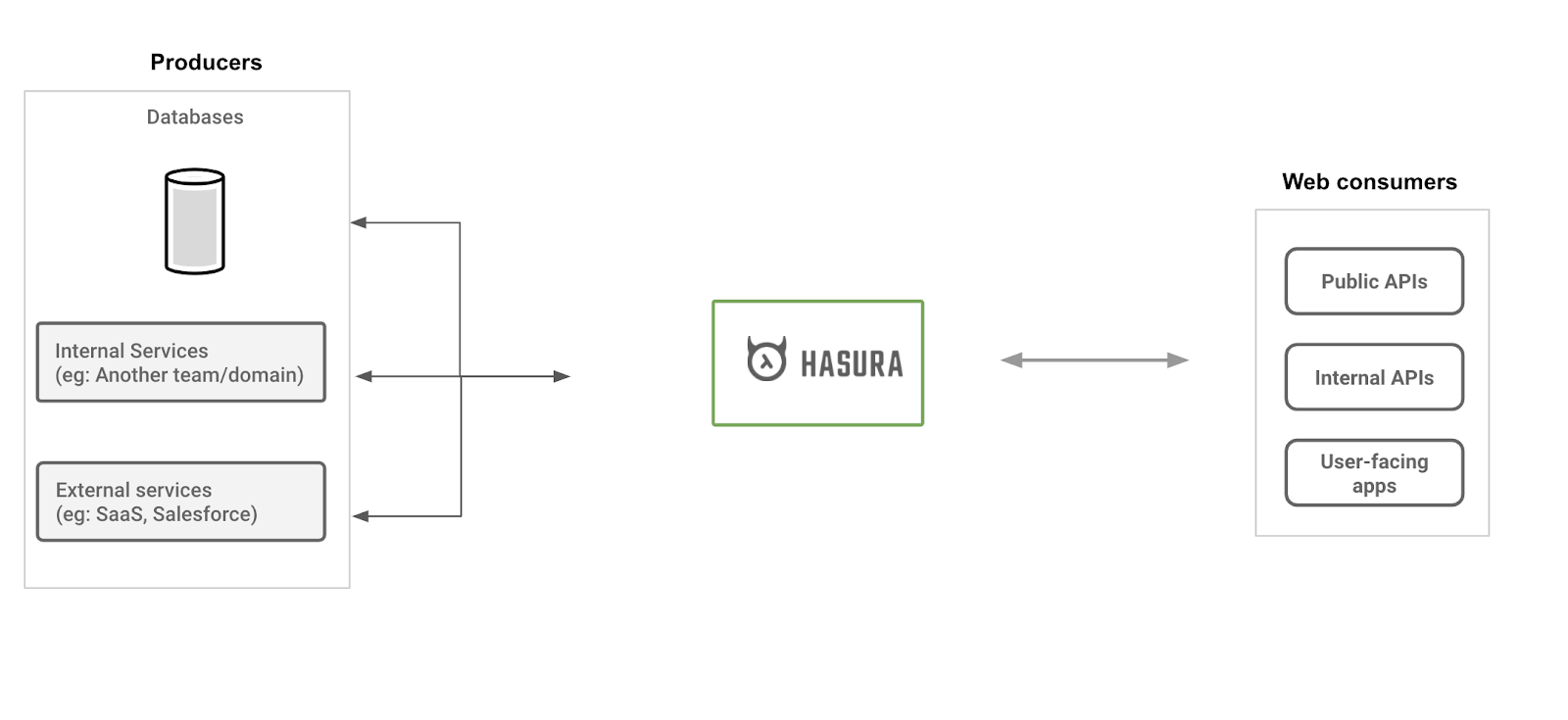
Hasura’s crazy idea is to convert the tedious aspects of building this API into a service.
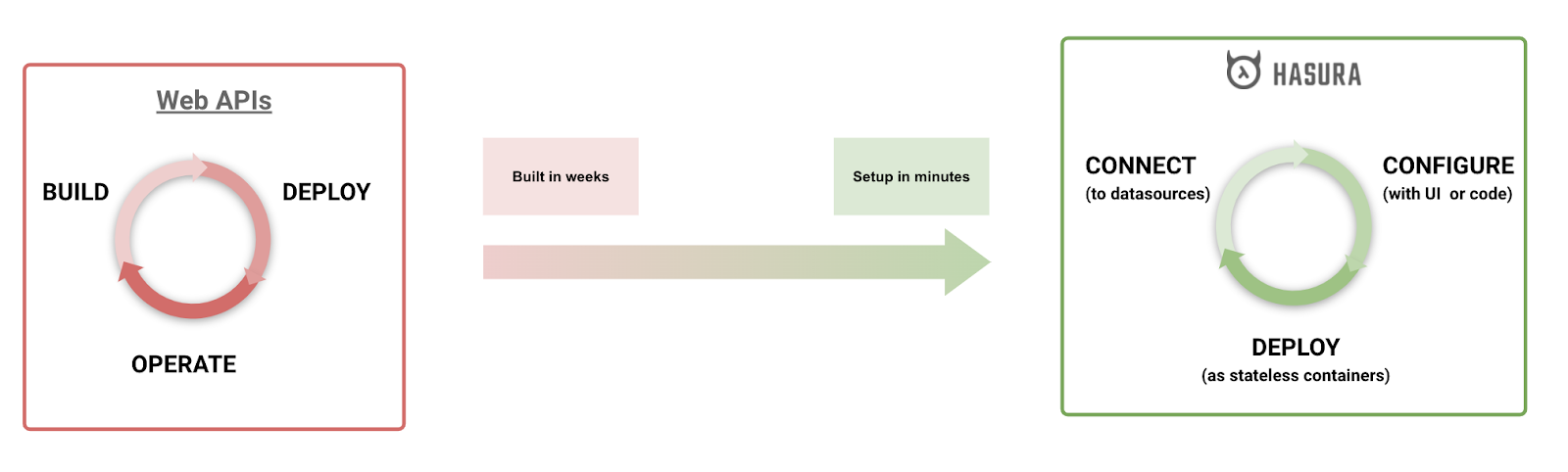
Instead of spending months writing code to map thousands of tables, embed authorization rules and building APIs, Hasura allows developers to declaratively configure a web-server in minutes and expose a production-ready API. From building something by hand to getting that “as a service”.
Hasura provides the data API "as a service" on your data sources.
This allows Hasura users to move extremely fast in environments where they wouldn’t have imagined it possible. From indie devs, startups, to Fortune 10 organizations we hear again and again that Hasura has allowed them to deliver their APIs and build modern apps in record time with record predictability. This is especially valuable for enterprise where all new capabilities (apps or APIs) have to connect to existing online data and they’re not just building entirely greenfield applications.
2. Hasura’s technical design
Designing a product like Hasura is an extremely dangerous and risky affair. Capturing what developers are used to doing by hand and automating portions of that to become a service is not something one should just wade into.
As we started to build Hasura (many years ago, before even GraphQL was launched as an open-specification!), we looked into what kinds of products and technologies have done something similar that we could take design inspiration from.
2.1. Prior work & design inspiration
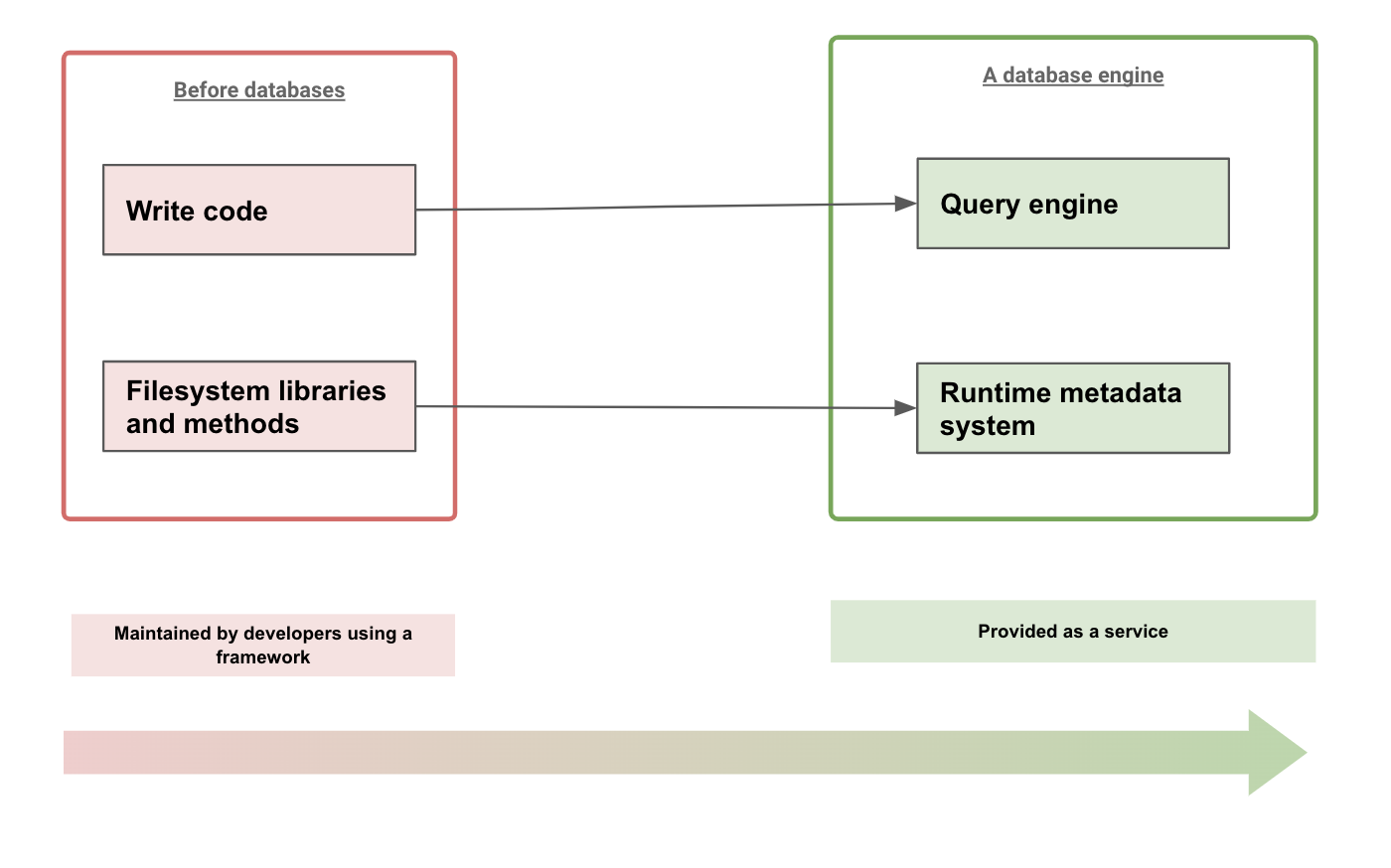
If we take a step back and think about technology that was able to massively increase developer productivity, by abstracting away the repetitive portions of work into a service and also simultaneously capture domain-specific requirements, the best examples that come to mind are: Databases!
A database provides a metadata engine at runtime that is able to capture the domain-specific requirements provided by a developer and then provide a service that allows the developer to operate on data - without the tedious work of actually dealing with raw files. Consider, for example, the difference between Lucene and Elasticsearch. :)
Using its metadata, a database engine is able to operate entirely at runtime (as a service) without any build-time work on the part of the developer. A declarative metadata system is useful, because the database engine can effectively “think about itself” and automatically abstract away the grunt work over a predictable but flexible API.
Furthermore, a database server is now able to provide guarantees and SLAs on performance, security, availability and on other operational aspects out of the box.
When we started thinking about technical design primitives for Hasura, we took heavy inspiration from the database world, having worked extensively with databases like Postgres, building search services with Lucene, synchronizing data from normalized to de-normalized data stores and other similar OLTP data tasks.
A convenient way to think about Hasura is that it is the frontend of a distributed database engine that works at the web-tier to support, ahem, web-scale loads.
Check out the table below that draws analogies from a database world to the Hasura GraphQL engine.
Database
Hasura
Speaks SQL over TCP
Speaks GraphQL over HTTP
Expose models & methods over a relational algebra
Expose data models and methods over a unified JSON abstraction
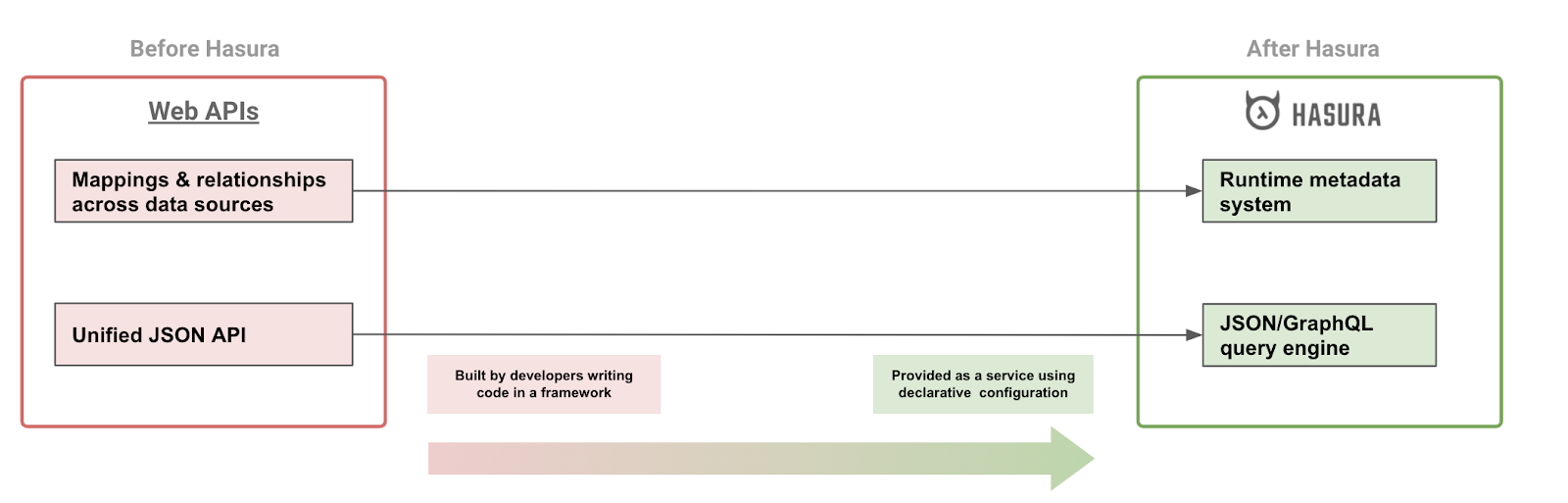
Metadata captures modelling rules
Metadata captures mapping, relationships and authorization rules
Engine talks to storage directly
Engine talks to other databases and sources over the network
Implements transaction engine and a write-ahead-log to drive complex database operations with fault-tolerance
Implements an event-engine to drive stateless business logic with atleast-once or exactly-once semantics.
2.2. Hasura approach
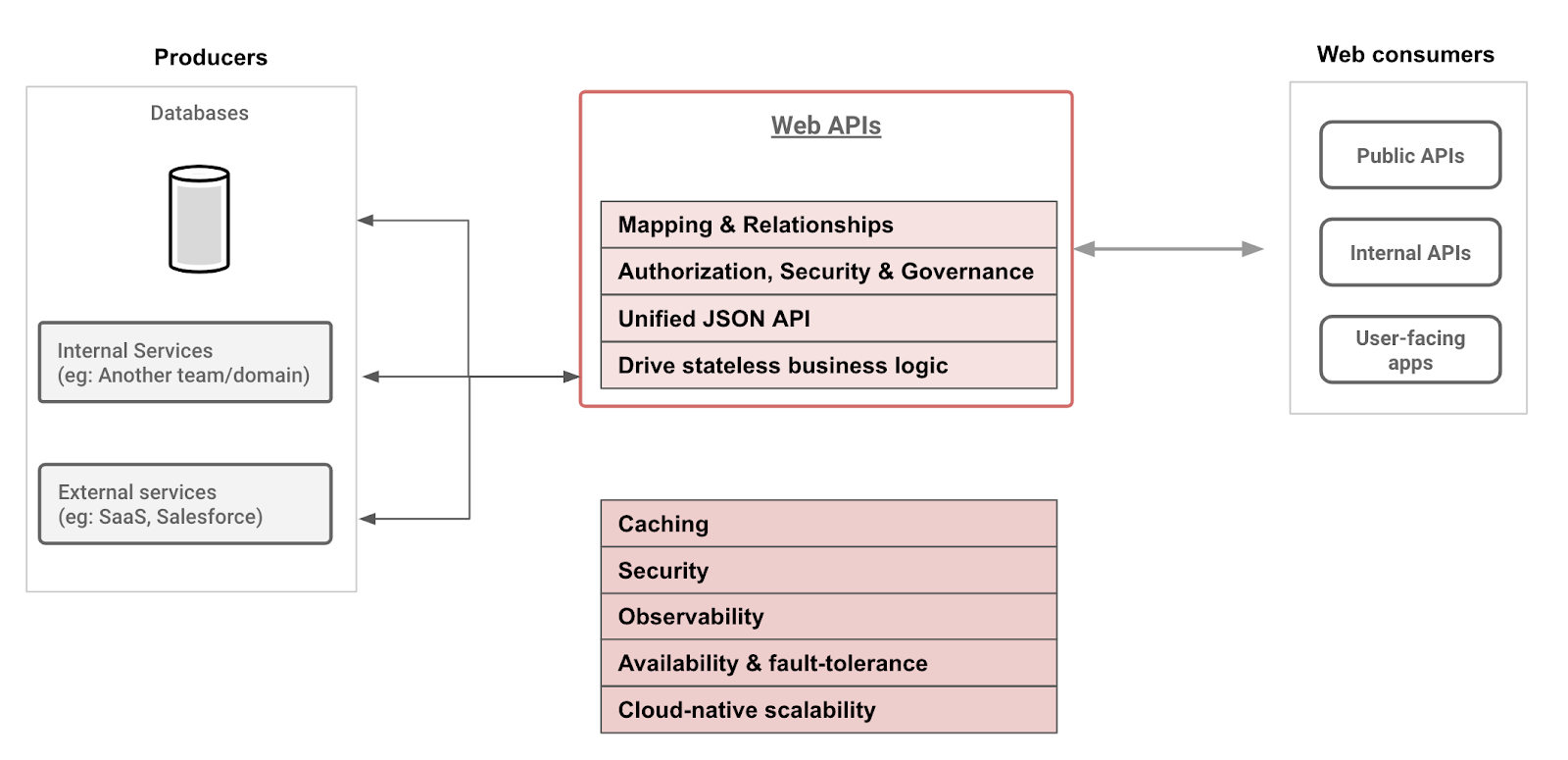
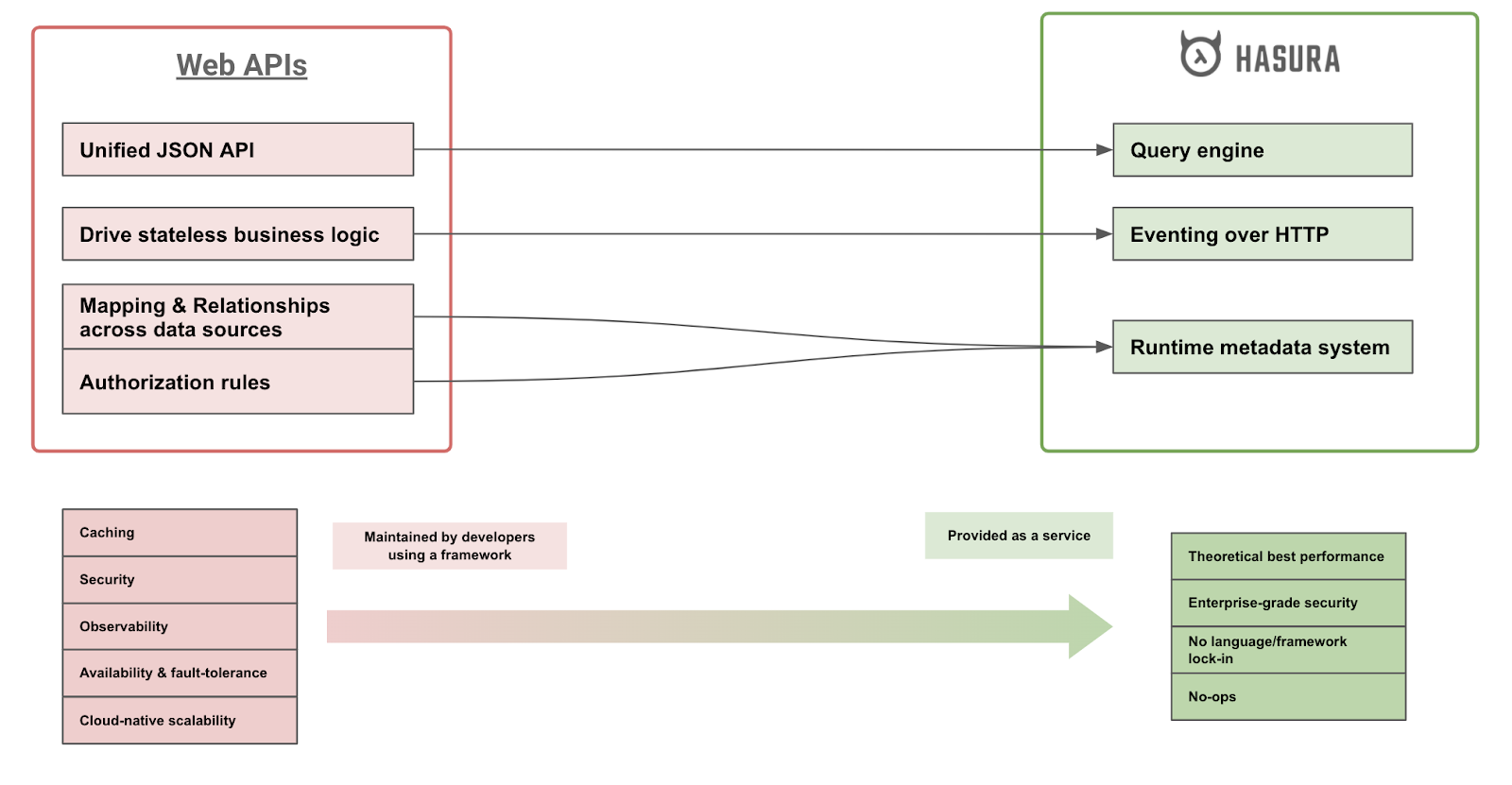
Hasura implements a metadata engine that can capture the domain-specific requirements of a web service that provides data access.
Using that, Hasura provides out-of-the-box web APIs that allow flexible and secure operations on data.
At the same time, Hasura is able to provide the SLAs and guarantees on so-called NFRs (non-functional requirements) to ensure smooth operations.
In the diagram below, you can see how Hasura maps web API concepts into a declarative web-service aka "a GraphQL engine".
Let’s dig into details of these capabilities and features and we’ll see how Hasura’s design is able to tackle these technical challenges.
3. Key Hasura Capabilities
3.1. Production ready in minutes
The most important business value that Hasura provides is reducing time to market, by unblocking developers.
Everything that we do at Hasura is through the lens of making sure that getting productive is hyper-fast.
We've designed Hasura and the developer tooling around it to make sure grokking Hasura concepts and operating Hasura is as easy and fast as possible.
3.2. Instant (GraphQL) APIs on your data
Once the Hasura service starts running, developers can dynamically configure its metadata. This configuration can be done using a UI, or using an API call, or using code in a git repo that is “applied” to Hasura to integrate best with your CI/CD pipeline.
This metadata captures a few key things:
Connections to data sources
Mapping models from the data sources into an API
Relationships between models within the same data-source and across data sources
Authorization rules at a model or method level
Using this metadata, Hasura generates a JSON API schema and presents a web API that can be consumed.
Hasura provides this unified JSON API over GraphQL. GraphQL is a particularly great fit, since it is native to JSON. As an API spec it can capture the flexibility required to operate on a large number of data models with a variety of methods, while at the same time provide a controlled boundary required by a web service.
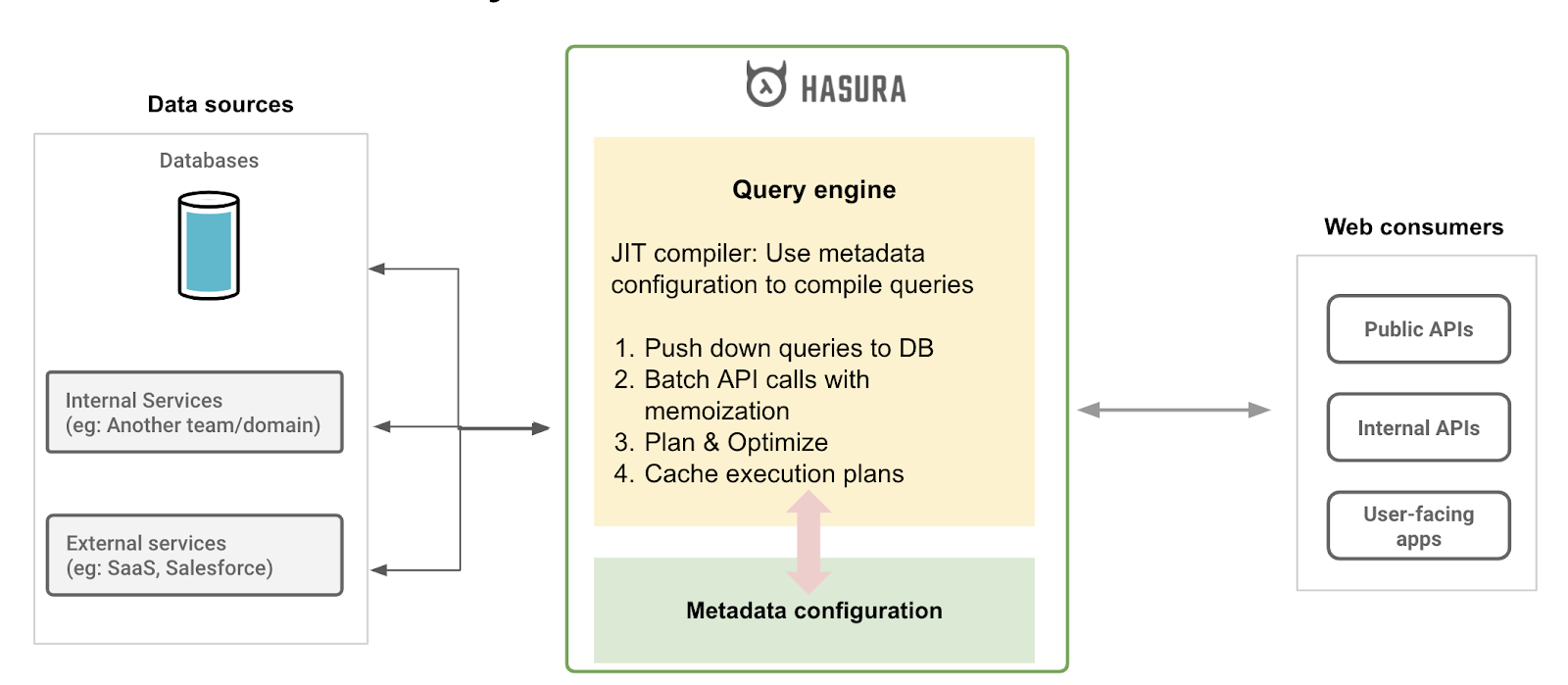
Although Hasura presents itself as a web-service, Hasura is quite a JIT compiler, Hasura takes incoming GraphQL API calls over HTTP and then tries to achieve theoretically optimal performance while delegating the data fetches to downstream data-sources.
Hasura can avoid N+1 issues entirely, common with GraphQL backend implementations. It can memoize aggressively, and issue the minimal number of hits to upstream data sources.
Hasura’s metadata and query engine are able to effectively present your entire world of data as a unified JSON document that is queryable.
However, data access can not be automated and solved for unless without embedding authorization rules.
Developers are consuming data in insecure environments. Unlike many decades ago where a bank building would have the database, and the Java applications would be running on trusted machines being used by trusted employees. As owners of data today, we want to be able to give developers access to the right scoped data (and methods on that data) wherever they are and whatever they may be doing with it.
Types of developers
Types of APIs
Developers outside the org
Public APIs
Developers in different teams
Internal APIs but with governance and QoS controls
Developers building apps for external users
External facing APIs, but with restricted surface area to prevent abuse by end-users
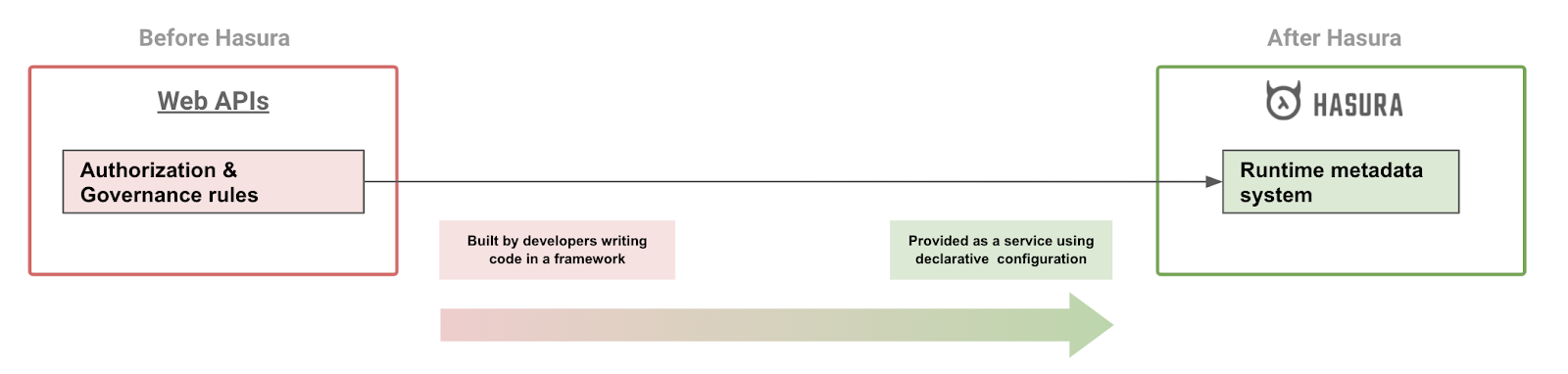
Hasura has an authorization engine that allows developers to embed declarative constraints at the model level.
This allows Hasura to automatically use the right authorization rules for any given API call that may access lists of models, parts of the models, models through relationships.
Because these authorizations are declarative and entirely available at runtime (via APIs), it allows developers and Hasura as a product, to provide additional observability into the authorization system. Examples:
Authorization audit: What authorization rules were used/triggered in a particular API call by and end consumer
Tooling to review and manage authorization rules
Hasura’s authorization system resembles the declarative system of RLS (or Row Level Security) that some database engines offer but brought to the application layer. Incidentally, we built the first version of Hasura’s authz system at the same time as Postgres RLS was first introduced many years ago. A happy coincidence! 🤓
Authorization rules are conditions that can span any property of the JSON data graph and its methods:
Any property of the data spanning relationships
Eg: Allow access if document.collaborators.editors contains current_user.id
Any property of the user accessing the data
Eg: Allow access if accounts.organization.id is equal to current_user.organization_id
Rules can mask or tokenize or encrypt portions of the data model or the data returned by a method and are labelled. These labels are called "roles"
There are significant advantages to a declarative authorization system because it allows Hasura to perform several optimizations automatically:
Authorization + data access in a transaction: Often the data fetch and the authorization rule check are present in the same system. This allows the fetch and the authz check to happen “atomically” so that the authz rule is not invalid by the time the data is fetched.
Authorization predicate push-down: Wherever possible, Hasura can automatically push-down the authz check in the data query itself. This provides a significant performance benefit and avoids additional lookups where it can be avoided
Authorization caching: Hasura can automatically update and cache authentication information or authorization checks as required which is work that one would have to do for hot queries
Automated private-data caching: Because Hasura can “think” about the authorization rules, Hasura can also automatically determine if multiple GraphQL queries made by different users will actually end up fetching the same data. This part of application level caching, aka knowing “what to cache” which developers would manually build can now be automated by Hasura.
Notably, Hasura doesn’t provide a built-in authentication mechanism. In most existing environments, especially enterprise, the authentication service is often an external system. Also with the rise of amazing SaaS and open-source identity management and authentication "as-a-service" providers Hasura can now continue to solve for what it does best. For example, Hasura works seamlessly with Keycloak, Okta, Auth0, Azure AD, Firebase Auth and entirely custom community-built solutions like hasura-backend-plus that provide an authentication service for Hasura. The list above is not exhaustive in the least, but is intended to convey the variety of authentication solutions that exist and that Hasura can integrate well with!
3.4. Application level caching
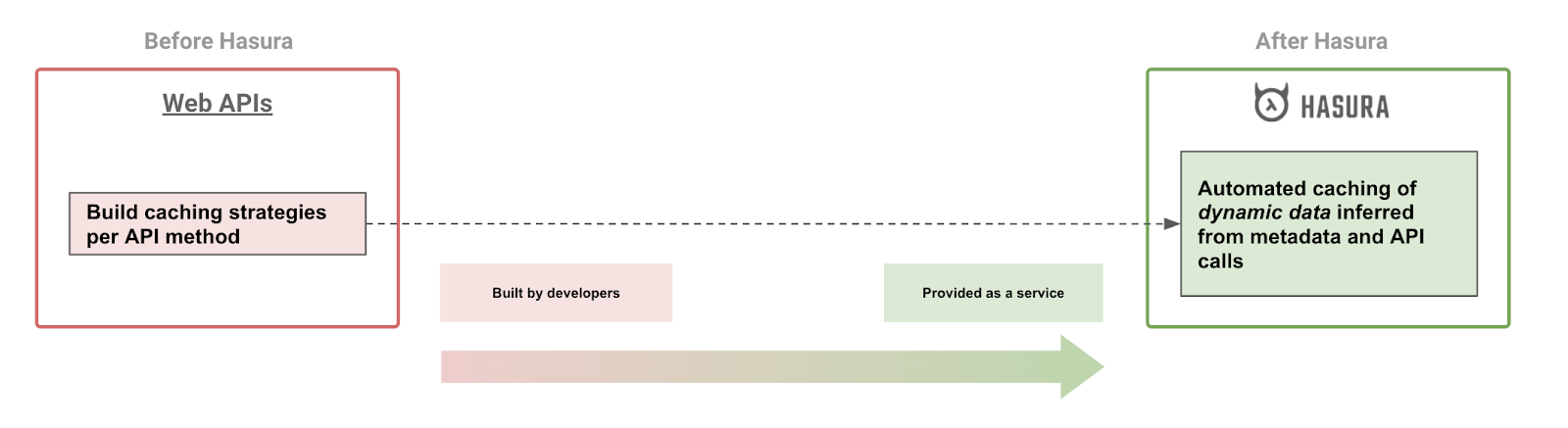
Application level caching is one of the major reasons why developers often need to manually build web APIs that provide data access manually. Certain API calls are extremely frequent or extremely expensive and computing the data fetch is too expensive for the upstream data source.
Developers then build caching strategies that use domain knowledge of knowing what queries to caching, for which users (or user groups) and use a caching store like Redis to provide API caching.
Because Hasura’s metadata configuration contains detailed information about both the data models and the authorization rules which contain information about which user can access what data, Hasura can implement API caching for dynamic data automatically.
Cache invalidation, which is the second part of this problem, is a HARD problem. Most commonly, to avoid worrying about caching invalidation vs consistency, as developers we use TTL based caching and let the API consumers deal with the inconsistency.
Hasura has deep integrations into the data sources, and since all data access can go through Hasura or using the data-source’s CDC mechanism, Hasura can theoretically provide automated cache invalidation as well. This part of the caching problem is analogous to the "materialized view update" problem.
We’ve taken our first steps to automate application level caching and have a long way to go, but the future and potential is extremely exciting :)
I gave a detailed talk about building automated caching strategies at GraphQL Summit a few months ago which might be interesting to you if you’d like to learn more about how we think about caching at Hasura!
3.5. Driving stateless business logic
Driving stateless business logic is becoming increasingly harder in the microservices and polyglot data landscape that we have.
Event driven patterns have emerged as a solution to deal with high-volume transactional loads and to orchestrate a sequence of business logic actions that execute exactly once and handle failures without requiring roll-backs.
These patterns also allow business logic to be as stateless as possible. Business logic resembles “pure compute” that is invoked on an event. Any data required during the execution is accessed over HTTP APIs.
However, the plumbing required to do this is prohibitive to getting started.
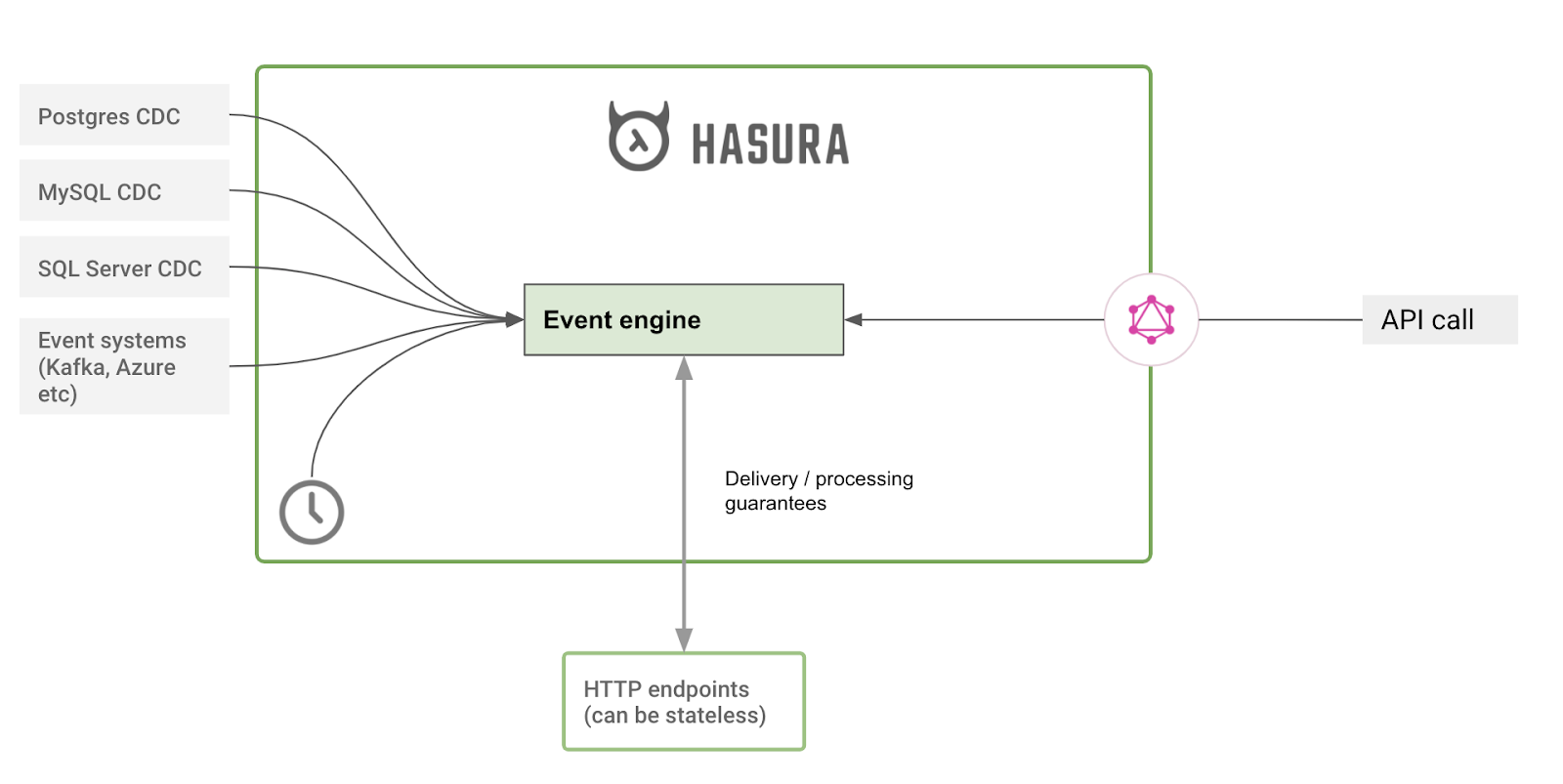
Hasura implements an eventing system that provides developers an easy way to write stateless business logic that is integrated with Hasura over HTTP.
Hasura captures and delivers events over HTTP and makes certain guarantees (atleast-once, exactly-once) to help create workflows that allow developers to be as productive with stateless business logic as they would have been writing code in a stateful monolith!
Hasura's eventing integrations:
Change Data Capture integrations with data-sources to atomically capture and reliably deliver data events over HTTP. Read more.
API events: API calls made by end-users are mapped to events that are delivered to backing business logic, over HTTP. Hasura can provide a synchronous or asynchronous boundary. Read more.
Time based events: Hasura can trigger events based on a time schedule or a timestamp and deliver them over HTTP to business logic. Read more.
For example, a data change event can be captured by Hasura and delivered to a REST endpoint that is backed by a serverless function or a microservice.
Supporting traditional transactions: However, when an API consumer is speaking to a single data-source which supports transactions Hasura can also expose transactions over websockets and GraphQL. This allows business logic authors to use transactions the way they normally would and gradually move to an event based system if required.
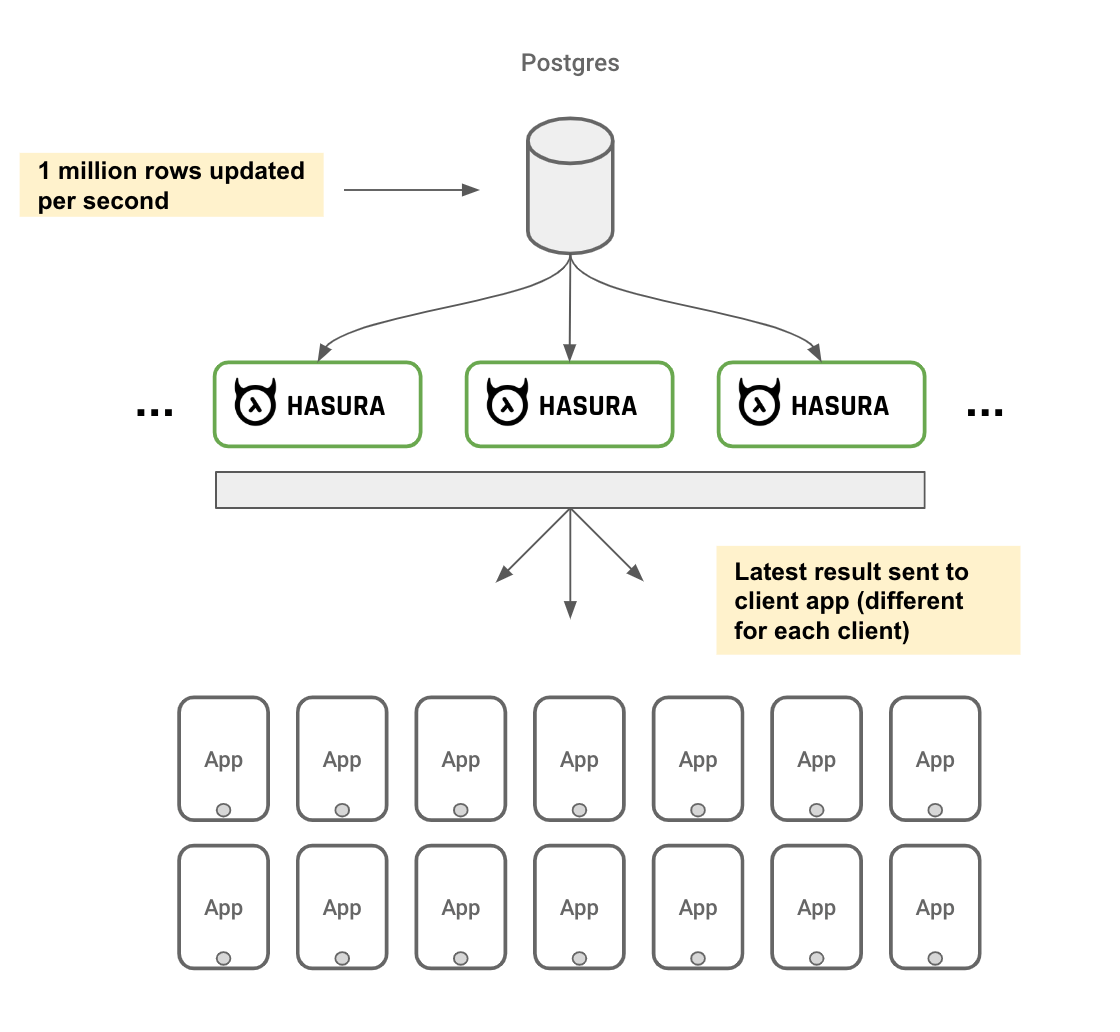
3.6. Realtime APIs (aka Subscriptions)
Hasura integrates with databases and can provide a scalable realtime API to end API consumers. This is kind of like a WATCH API or a GraphQL subscription to watch changes on a particular resources.
Because of its authorization system, Hasura can ensure that it can send the right events to the right consumers.
Realtime APIs over websockets are notoriously painful to manage in production because they are surprisingly stateful and expensive. Websockets also require implementing another layer of web security.
Read more about how Hasura provides a scalable subscriptions API on Postgres here:
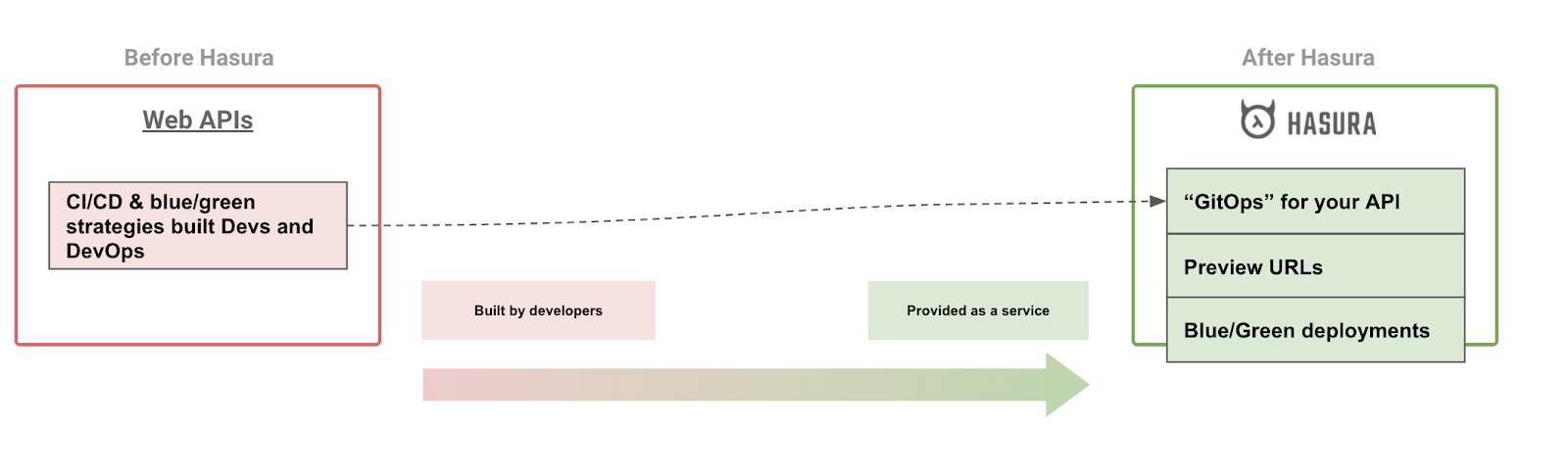
If you’re familiar with the JAMStack ecosystem, you would have come across the idea of “preview URLs”. These are endpoints that host versions of your static app in various stages of your development process. These are extremely useful during development, staging, QA etc for human stakeholders.
Blue/green deployments or A/B rollouts are also a joy because these are static assets available at dedicated endpoints. Via some simple configuration, DNS rules, or load-balancer configuration you can benefit from this ability to publish multiple versions of your app simultaneously and split traffic between them.
Hasura’s goal is to bring this ability to dynamic APIs!
Because Hasura is an API system that is entirely configured at runtime and can isolate it’s metadata configuration in an external system, you can do the following with ease:
Deploy a new version of your API, against the same data-source to preview a metadata change (like new model mappings or authorization rules)
Run multiple versions of Hasura against the same data-sources to ensure a reliable roll out.
3.8. Federated data & control plane
In case you missed it, Hasura’s metadata system is entirely dynamic and configurable via APIs at runtime.
We’re building an authorization system on the Hasura metadata APIs. This allows you as an owner of the API to federate control of the metadata to relevant data-source owners.
Your online data is already present across multiple sources which need to be federated. Hasura makes that tractable by providing the missing link, a federated control plane.
Read more about data federation with Hasura and Remote Joins here.
3.9. No lock-in to a specific language/framework
Hasura presents itself as a service and provides integration points to other services over the network viz. Native connections to data systems and over HTTP for API consumption or for driving business logic.
This allows Hasura users to bring their favourite language, runtime, framework and hosting vendor when using Hasura.
This also allows us to build Hasura in a relatively insulated and decoupled environment while encouraging adoption of the latest and greatest technology trends.
3.10. No-ops
Our vision as a product, and also critical to ensure that Hasura adds recurring business value, is to allow developers to move as quickly to the “No Ops” future :)
Because Hasura is a self-contained service, we’re able to build an auto-scaling experience that actually works, building all the right integrations with APM and tracing tooling so that the data API service doesn’t impose a heavy operational burden.
Even more important, is Hasura’s ability to natively integrate with the health-check, availability, replication, scalability and circuit breaking patterns required by upstream data-sources.
4. FAQ
4.1. What if my data models change? Isn’t it a bad idea to couple the API to the data sources?
Hasura does not derive it’s API from a database. Technically, Hasura derives its APIs from the metadata configured by the user. This allows Hasura to handle the all the problems that emanate from exposing data models directly, while still benefitting from the approach.
Data models are meant to change, which could happen for several reasons:
Data models evolve (additively or destructively) with business requirements
Normalize to make writing data easier
Denormalize to make reading data faster
Change databases entirely
Hasura’s metadata engine allows developers to redefine their model mappings while preserving the end APIs. While this could use database concepts like views, this can be done without requiring any additional DDL on the database as well, because Hasura metadata can contain the right mappings. For example, suppose an entire table ceased to exist, Hasura’s metadata can contain a named query (similar to a view) that continues exposing the same API model but now mapped to a named query to ensure that data is now fetched from multiple tables instead of the one.
Another example, on Postgres specifically, we’re working on being able to create the same GraphQL API whether you use a normalized set of tables, or denormalized tables with JSON columns.
4.2. How do I customize Hasura’s APIs?
Hasura auto-generates a bulk of the required APIs using metadata you provide and then allows you to extend the API by mixing in your business logic.
Hasura encourages a CQRS model while adding custom APIs by providing all the underlying plumbing and you can then add your own API in your favourite language/framework/hosting-provider and plug it into Hasura as a set of REST endpoints.
4.3. Does Hasura force my consumers to use GraphQL?
Based on popular demand, especially from our enterprise users, we’re working on adding support for REST APIs soon, just the way Hasura already provides GraphQL :)
Keep a lookout!
4.4. How do I use Hasura for existing applications?
We’ve designed Hasura to instantly add value to any existing online data store. You can point Hasura to an existing data source (database, GraphQL, REST), add some configuration and start using it.
Very commonly, our users use Hasura to add high-performance GraphQL queries and subscription support to their existing applications and continue using their existing APIs for writes.
Hasura is designed for incremental adoption without having to rip-and-replace or entirely rebuild your stack. Get in touch with us if you need help thinking through your architecture.
4.5. I use X web-framework to build APIs. How do I use Hasura?
Same as 4.2 and 4.4!
5. Comparisons to other tech in the landscape
Coming soon. We'll take a detailed look at how Hasura compares to other technologies in your stack and what the pros/cons of Hasura are.