The Hasura GraphQL Engine is a blazing-fast GraphQL server that gives you instant, realtime GraphQL APIs over Postgres, with webhook triggers on database events, and remote schemas for business logic.
Hasura helps you build GraphQL apps backed by Postgres or incrementally move to GraphQL for existing applications using Postgres.
The Hasura GraphQL Engine is open-source. You can check out the complete repo here.
Postgres ❤️: Supports Postgres types (PostGIS/geo-location, etc.), turns views to graphs, trigger stored functions or procedures with mutations
You can check out all the Hasura features on our website and docs.
Architecture and performance
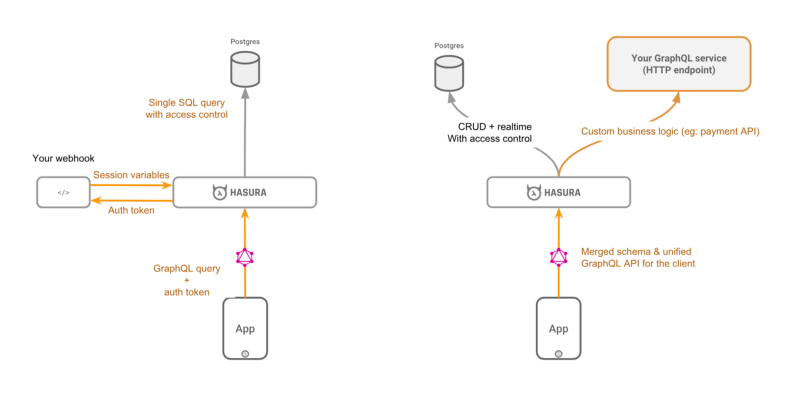
The Hasura GraphQL Engine fronts a Postgres database instance and can accept GraphQL requests from your client apps. It can be configured to work with your existing auth system and can handle access control using field-level rules with dynamic variables from your auth system.
You can also merge remote GraphQL schemas and provide a unified GraphQL API.
How Hasura works in your stack
While designing Hasura, we had two objectives:
Hasura should be able to run anywhere, from your local machine to the Heroku free tier to a server on Amazon, Google or Microsoft.
You should be able to extract maximum performance/dollar.
Consequently, we optimised Hasura for low memory footprint & latency. On the Heroku free tier, it consumes ~50MB of RAM even while serving more than ~1000 requests/per second.
If you’re interested in the architecture decisions involved in building this, you can read about it here.
Getting Started
Our aim with the Hasura GraphQL engine is to help you setup a GraphQL server with the least amount of friction, so that you can start building applications without any setup.
With that in mind, here’s how you can deploy Hasura to Heroku in just 30 seconds.
And that’s it! Once you have deployed Hasura, (on Heroku or using Docker), you are now ready to start making GraphQL queries, as realtime GraphQL APIs are automatically generated for your databases. Go ahead, try it out :)
In case you wish to use Hasura as a self-hosted BaaS, we have a tutorial featuring Hasura integrations with an infra provider and an auth provider. Check it out here!
More tutorials, integrations and examples are available here.
Getting Support
In case you are ever stuck, you can reach out to us on Discord (we are extremely active) or by creating a Github issue. You can also follow our Twitter to keep up with updates on Hasura and the company.
We would love more such stories! If you do try Hasura out or use Hasura to build something awesome, let us know via the Discord — it would make our day!