In this post, we will look at various aspects of taking a GraphQL API to production and how Hasura helps you through the process seamlessly with it's advanced security and production ready features.
As we dive into what Hasura offers to be production ready, we will also step back to look at potential issues related to performance, security and reliability in building apps with GraphQL.
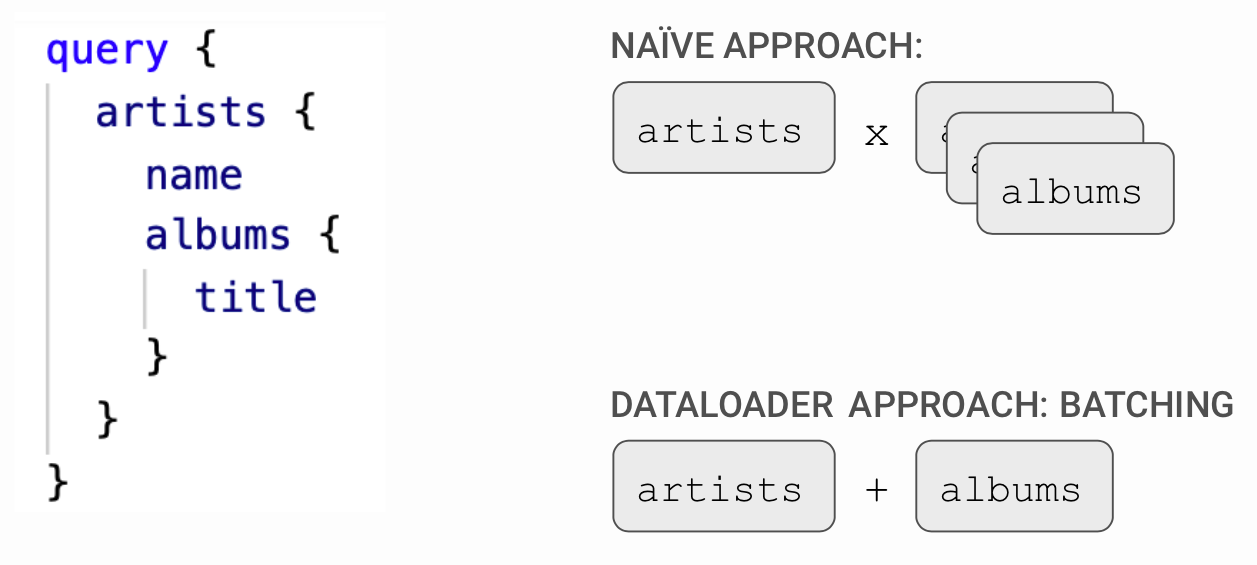
The most common bottleneck with GraphQL performance is the N+1 query problem. GraphQL query execution typically involves executing a resolver for each field. Let's take an example of fetching artists and their related albums.
Naive Approach with N+1 problem
In the example query above, we would invoke a function to fetch the albums and then for each of these albums, we would invoke a function to fetch the tracks, the classic N+1 query problem. The number of queries grows exponentially with the depth of the query.
The queries executed on Postgres would be as follows:
SELECT name FROM artists;
This gives us all the artists. Let the number of artists returned be N. For each artists, we would execute this query (so, N queries):
SELECT title FROM albums WHERE artist_id = <artist-id>
This would be a total of N + 1 queries to fetch all the required data. As you can imagine, this hits the database exponentially with higher levels of nesting. The other approach to consider here is the Dataloader approach which hits the database linearly with the level of nesting. Batching of query happens at each nested layer reducing the exponential queries made in the naive approach.
Efficient Queries
So what would be a better solution? Let's look at this SQL:
SELECT artists.name as name
FROM artists
JOIN albums
ON (artists.id = albums.artist_id)
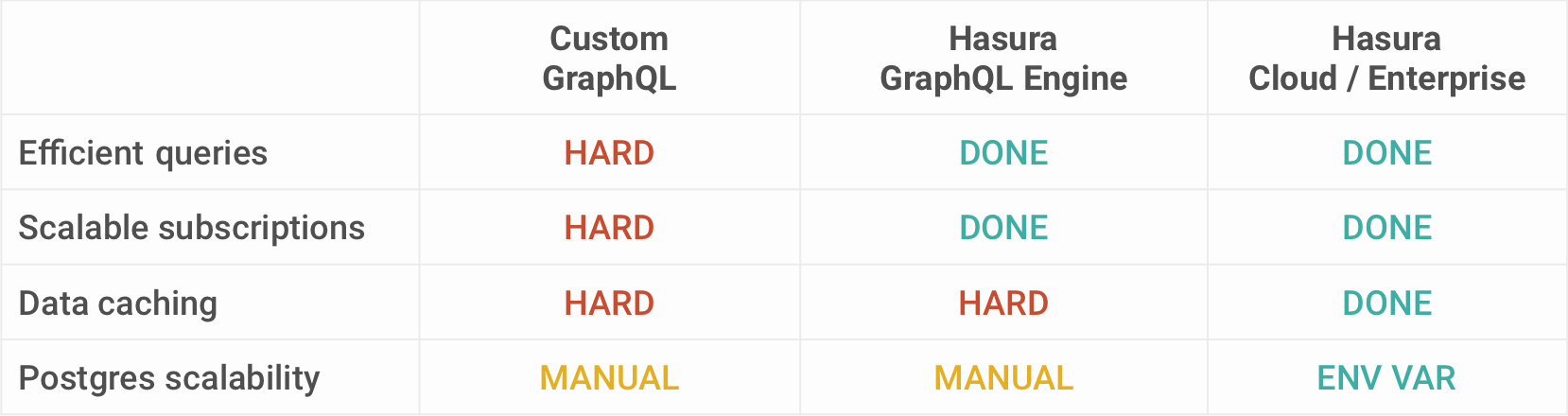
Instead of making multiple SQL queries, this SQL plan hits the database just once! This compiler based approach allows Hasura to form a single SQL query for a GraphQL query of any depth.
Hasura follows the Don't resolve, compile instead approach for the database queries. You can read more about the architecture of GraphQL to SQL server. For other remote sources like Remote schemas (custom GraphQL server), it follows the dataloader approach for batching and combining queries.
Scalable Subscriptions
If you are building a realtime app, scaling websocket connections for live queries is a critical requirement for the app. When there are enormous number of realtime queries, Hasura can handle them by grouping similar queries and batching them during the compilation step, yet maintaining permissions.
Caching GraphQL queries at the server side needs a different approach compared to a typical REST API architecture. In REST, you can cache queries at the HTTP layer using GET requests and serve it in front of a CDN. Typically GraphQL queries are POST requests and caching needs to be handled differently.
Query Caching: Hasura already offers query caching in the OSS version, where the internal representation of the fully qualified GraphQL AST is cached, so that it’s plan need not be computed again. For Postgres, Hasura makes use of Prepared Statements to make query execution faster. Read more about Hasura's fast GraphQL query execution.
Data Caching: Hasura Cloud goes a step further and adds support for data caching on top of the query caching that's already available. Hasura has enough information about the data models across data sources, and the authorization rules at the application level letting users cache authenticated GraphQL API calls that works for shared data.
Cache invalidation is handled by using a TTL configuration so that state data is refreshed within a time interval. So clients can query with a @cached directive for data caching.
The final bottleneck when it comes to performance is the underlying database (i.e Postgres). Hasura Cloud supports horizontal scaling of Postgres, letting you load balance between multiple instances for read queries. You can
Create read-replicas of your postgres instances
Configure routing, connection pooling, and load balancing
And ofcourse, the regular optimisation of Postgres like adding the right indexes, analyzing the output of Explain remains the same on both the OSS version and on the Cloud.
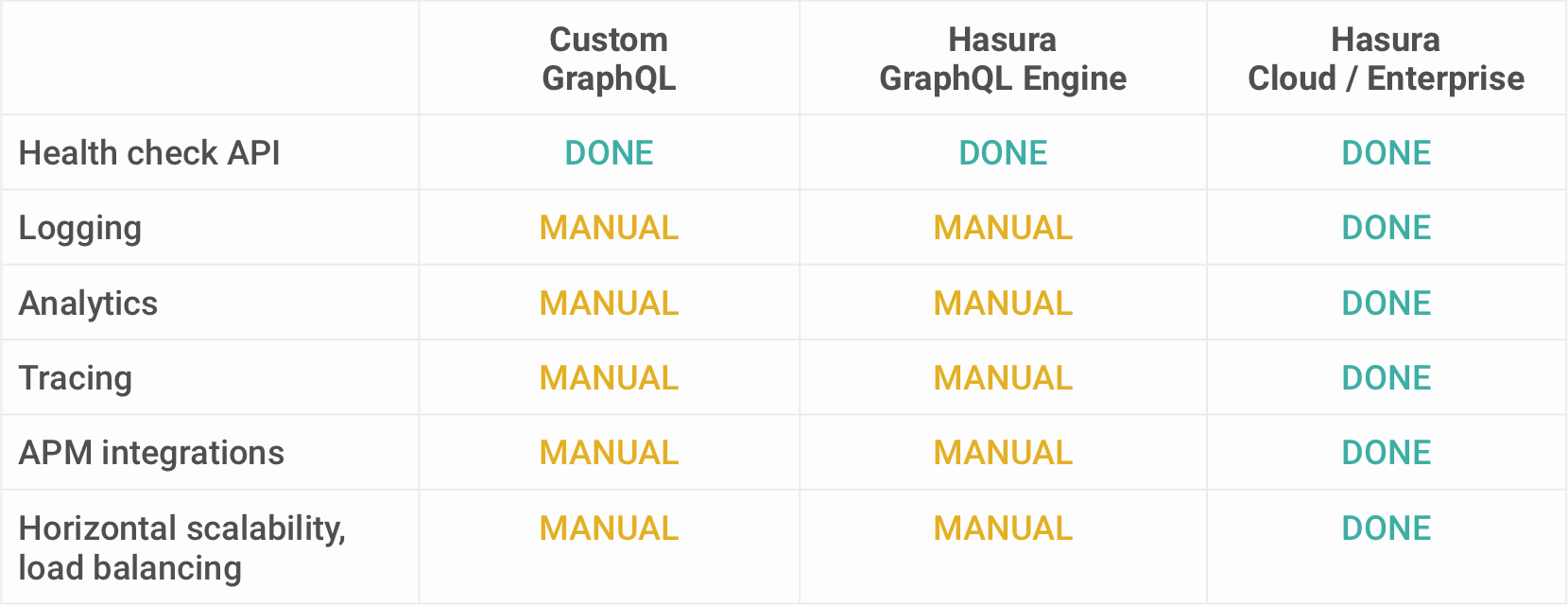
GraphQL Performance Checklist Comparison
Hand rolling your own GraphQL server is really hard if you are serious about performance. To top it off, Hasura also adds a declarative Authorization layer to make the job easier for authenticated requests and we will dive in to this in the next section.
Security
Next up is Security. As much as we care about performance, any complex production app will involve authenticated requests, a sophisticated access control system and some form of defense mechanism for preventing malicious attacks.
Service level
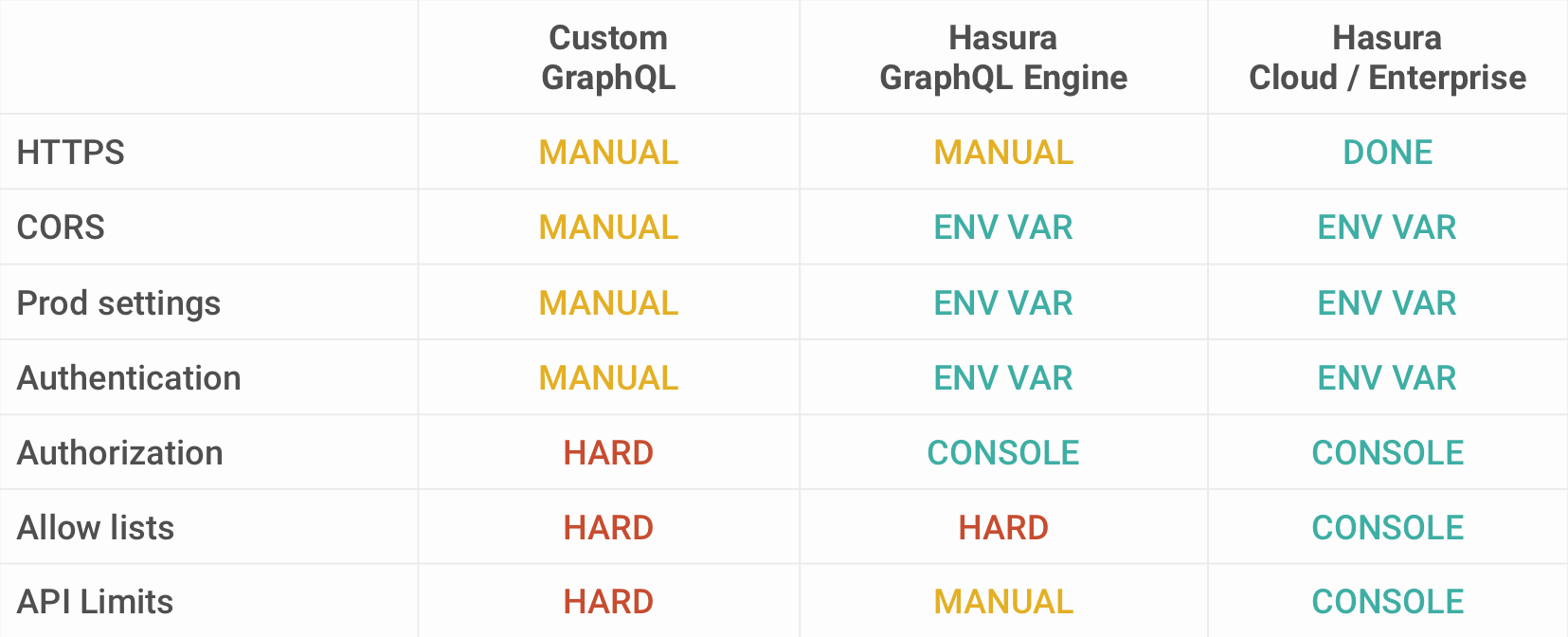
To cover the bases right, we will need to protect the Hasura GraphQL endpoint with some form of an admin secret. Hasura can be configured with an admin secret for direct backend access without restrictions, but also to prevent any public access of the API. CORS policies should be configured to whitelist only the application domains, unless it's a public facing SaaS API.
Maintaining different logging and debugging modes for development and production environment is important to prevent exposing sensitive information in server logs. For example, dev mode should be disabled in prod. Read more about these in the Hasura Production Checklist.
Authentication and Authorization
Adding to the admin secret, for real world apps, you might want to integrate an authentication provider either via JWT or through Webhooks. If applicable, ensure auth tokens are consistent with the user db via events or webhooks (example: match user IDs on create). Some applications will also require unauthenticated public access and for those use cases, you can configure UNAUTHORIZED_ROLE.
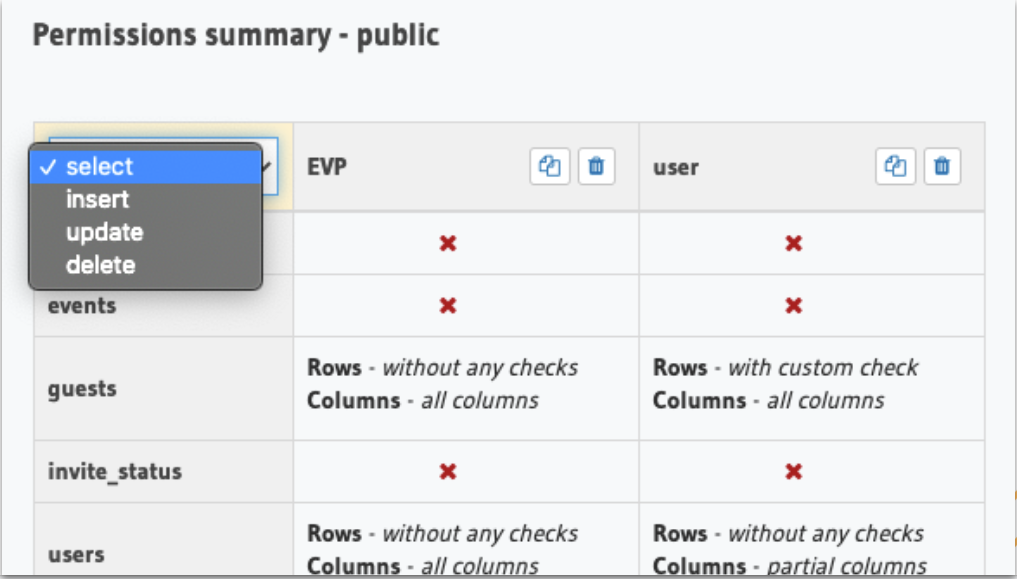
Hasura comes with built-in authorization system. You can define role based permission rules to restrict data access. Permissions can be set per role, per schema, per table and per operation type and access control rules (records and fields) for insert, select, update, and delete.
Role based permission check
Defense mechanism
Now despite setting up security rules and configuration, there are different vectors that need to be controlled to prevent any malicious attempts. With Hasura, you can:
Enable allow lists: Define a list of allowed operations (GraphQL queries, mutations or subscriptions) for your project to only allow a set of operations to be performed. In Hasura Cloud, you can configure Allow Lists for different environments.
For example, during development of a new feature you can define a new set of allowed operations on a staging environment and apply the same configuration to a production environment easily after the necessary testing is done.
GraphQL Query Capture: Hasura cloud captures queries (optionally stripping out session and query variables since they might be sensitive) and makes it available to you for 2 main uses:
Regression testing
Bootstrapping and managing an Allow List
The allow list can be configured with one click from the record of past operations. This way, you can quickly define an allow list on an existing project by just monitoring the queries that are made to the server.
Set rate limits: Configure your reverse proxy to limit by session variable or client IP; configure your GraphQL service to limit by query depth or complexity. Rate limiting restricts number of GraphQL operations per minute. This uses a sliding window approach. This means whenever Hasura receives a request, it will count the rate of that client starting from the current time to last one minute. Read more about configuring API Limits in Hasura.
Set response limits: Limit the number of rows returned, access to aggregation queries. This can be configured at the permission layer.
Effort required for Security Checklist
Collaborator Management
In Hasura Cloud, you can share access to the projects by configuring roles having certain privileges. The Admin role has complete access to the console i.e they can change the schema and the GraphQL engine metadata. The User role has limited privileges, depending on what's allowed.
The Execute GraphQL permission allows running queries, mutations and subscriptions from the GraphiQL tab of the console.
The View Metrics permission allows inspecting operation data and metrics from the PRO tab of the console.
This granularity makes it easier to share the management of APIs in teams without using a shared admin secret or a shared account credential.
In a production app, it is important to monitor the API usage to detect any anamoly. For example, if you have deployed a new schema change to production, you want to ensure if the APIs continue to work fine. With Hasura Cloud you can monitor errors, websocket connections, subscriptions, with a drill-down into individual operations.
Health Check: You can also configure external tools with the Health Check API that Hasura exposes. The Health API will respond with a status code 500 when something is wrong with the server and you can setup alerting/notifications for the same.
Distributed Tracing: Hasura Cloud has support for distributed tracing, a technique for debugging Hasura in production in the context of the services it works with. These services might include your own Postgres database, any remote schemas, event trigger webhook providers, action providers or authentication hooks. Distributed tracing attempts to give a unified view into the performance characteristics of all of these components of your architecture.
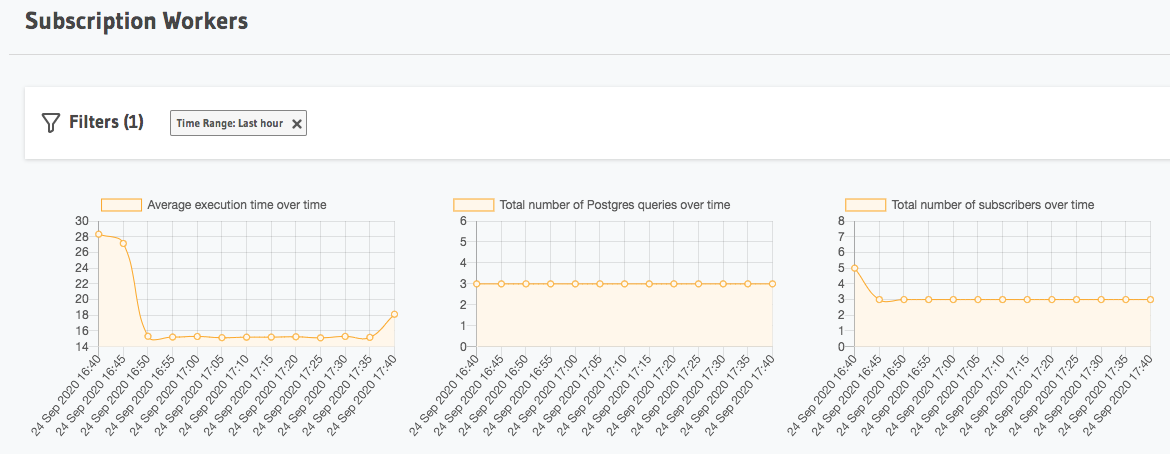
Subscription workers can also be monitored using Hasura Cloud. You can visualize usage statistics like Average execution time, Total number of Postgres queries and Total number of subscriptions among other metrics.
Subscription workers
API access to metrics: Hasura Cloud exposes APIs to access various metrics like the errors, websocket connections, subscriptions etc that can in turn be integrated with an APM tool of choice.
Observability
Observability (in software world) means you can answer any questions about what’s happening on the inside of the system just by observing metrics from outside of the system, without having to modify the working deployment to support this.
Hasura Cloud Metrics offers insights into:
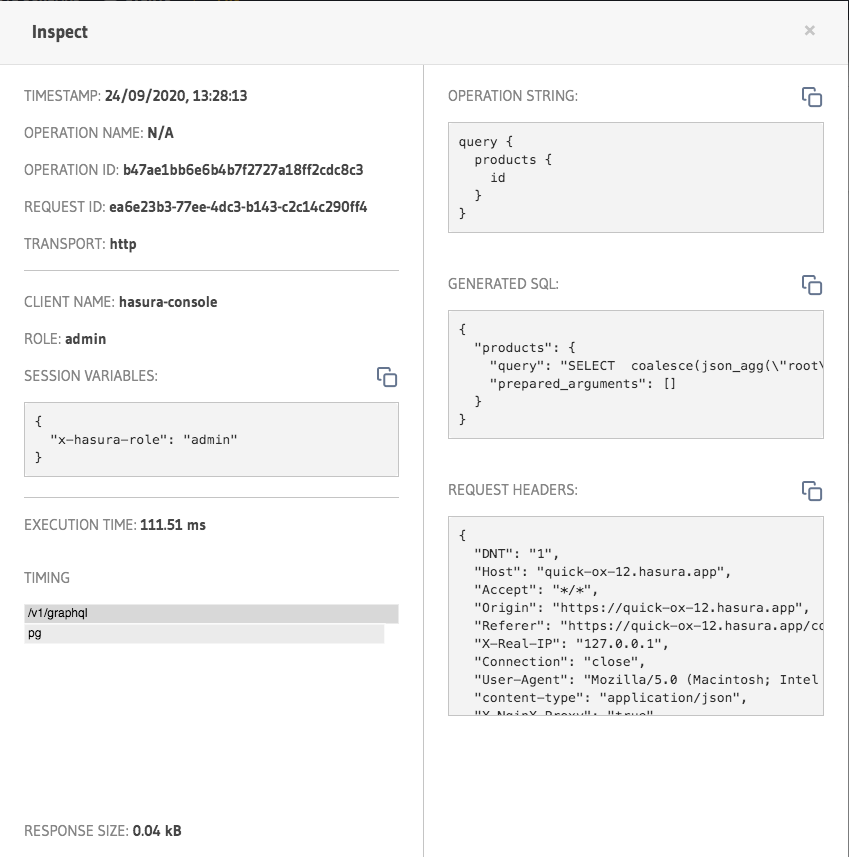
Query payload, hash, and timestamp
Query execution time
Connection type (http or ws)
Response status codes & size (kB)
GraphQL server version
Origin IP address.
Inspect Query Metrics
You can also configure these metrics with APM tools with the API access exposed by Hasura for further drill down of usage.
Specifically for Hasura GraphQL Engine, apart from the Cloud offering, you can also track usage of
Session variables such as X-Hasura-Role, X-Hasura-User-Id
Query metadata
Regression Testing
Hasura Cloud includes a comprehensive test bench that lets you seamlessly compile a test suite on each project, executable on any GraphQL Engine instance (ex: staging, prod). Broadly, we need to
Create a suite of critical operations (based on the application use case)
Add regression test suite to workflows, CI/CD.
The workflow involves, creating an initial regression test suite for production environment, and whenever there is a schema or Hasura metadata change, before moving to production, it will go through an automated test suite in CI/CD and only if the tests pass we will promote the changes to production.
Hasura Cloud makes it easier to configure these tests and run the test suite on demand.
High availability of the API is critical for a busy (continous network requests) application.
Configure GraphQL server load balancing
Once you configure read replicas for your Postgres instance, the load balancing at the database layer is automatically taken care. At the Hasura API layer, load balancing is done seamlessly with multiple instances of Hasura running in different regions* across the globe.
Configure Postgres high availability
This can be achieved by using a hosted Postgres Cloud vendor like Amazon RDS, Google Cloud SQL, Azure Postgres among others.
Here's a quick comparison of hand rolling your own GraphQL server and Hasura Cloud to ensure reliability of your API and application.
Effort required for Reliability Checklist
GraphQL Infrastructure
In production, hosting of custom GraphQL servers will typically involve Dev-Ops to manage infrastructure, scaling and to be highly available.
In Hasura Cloud, each instance of Hasura is a heavily multi-threaded server that exploits shared memory within the instance to aggressively optimise handling GraphQL queries at runtime. If you are running Hasura yourself or any other custom GraphQL server, then you will have to figure out how much CPU or RAM is required for optimal performance and high availability.
If you’re running on Hasura Cloud, you don’t need to care! Hasura Cloud doesn’t ask you to think about the number of instances, cores, memory, thresholds etc. All you need to do is to connect the database and let Hasura Cloud handle the infra for you.
You can keep increasing the number of concurrent users and the number of API calls and Hasura Cloud will figure out how much resources to allocate and will auto-scale for you.
Now that you have learnt what it takes to run and maintain a production ready GraphQL server, to reap the benefits of performance, security and reliability, make the switch to Hasura Cloud from your OSS version. Read more on Moving from OSS to Hasura Cloud.