














 Edit on GitHub
Edit on GitHubSQL Server Indexes
An index in a table improves the query performance by speeding up the data lookup. By default, a query analyzer does a sequential scan on every row in a table until it finds the searched result. An index scan is much faster because an index acts as a pointer reference to the rows address in a table.
Types of Indexes
Indexes are classified as primary, clustered, and secondary indexes.
Clustered Index
A clustered index determines the physical order of data in a table. In other words, an index decides the sequence in which the data gets stored in that table. When you create a primary key, a default clustered index is created on the column, and all the rows get sorted based on the primary key column. There can only be one clustered index in a table.
- Step 1. Create a table with no Primary Key
USE ADVENTUREWORKSGOCREATE TABLE Humanresources.emp(ID INT IDENTITY,NAME NVARCHAR(40),EMAIL NVARCHAR(40),DEPARTMENT NVARCHAR(30));
- Step 2. Insert rows
--Insert 100000 rows using the while counterSET NOCOUNT ONDeclare @counter int = 1While(@counter <= 100000)BeginDeclare @Name nvarchar(40) = 'name' + RTRIM(@counter)Declare @Email nvarchar(40) = @Name + RTRIM(@counter) + '@domain.com'Declare @Dept nvarchar(30) = 'Dept' + RTRIM(@counter)INSERT INTO HumanResources.emp values(@Name, @Email, @Dept)set @counter += 1End
- Step 3. Enable the Estimated and Actual Execution Plan in SSMS and execute the below query
SELECT * FROM Humanresources.emp WHERE ID=20493
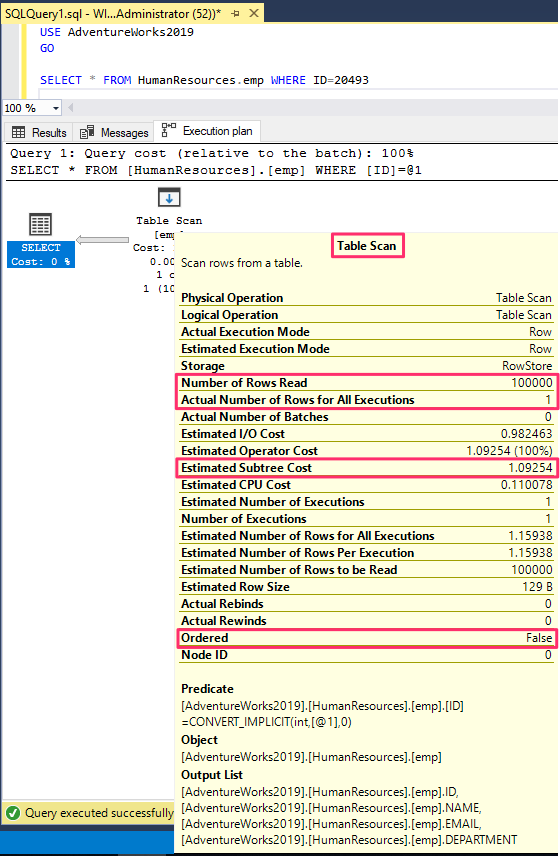
It runs a complete table scan on all the 100000 records with a higher estimated subtree cost.
Improve performance with a Primary key constraint
--Create a PK on ID tableALTER TABLE Humanresources.empADD CONSTRAINT PK_EMP PRIMARY KEY(ID)
Re-run the above select query.
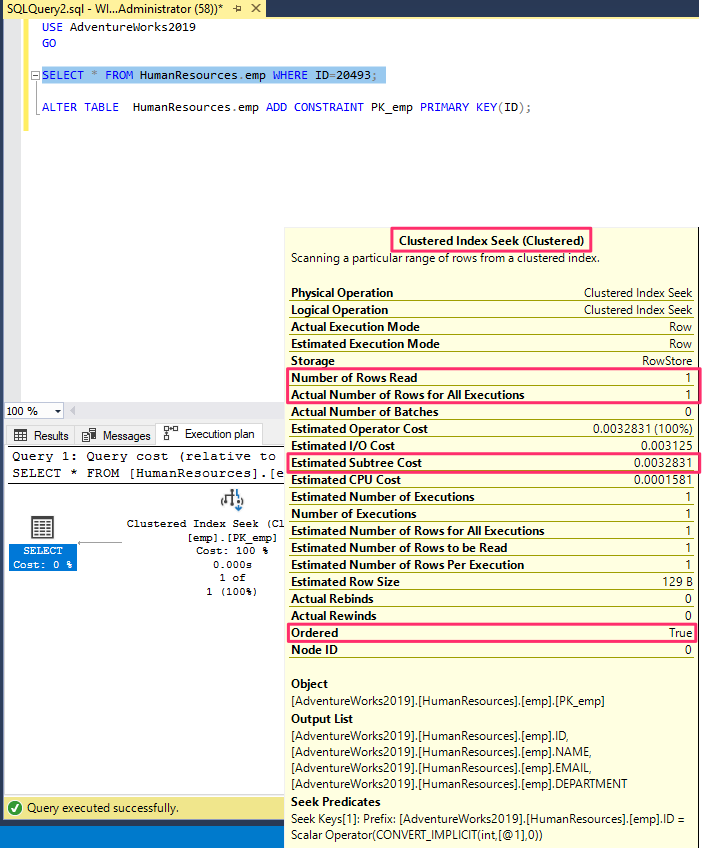
The query analyzer now seeks ID in the clustered index and scans the column 'ID' alone. The number of rows read are just 1 in this case. Also, the estimated subtree cost is reduced to 0.003281.
As an alternate method, you can explicitly create a clustered index in a table.
Create a Clustered Index
--Create clustered index syntaxCREATE CLUSTERED INDEX <index_name>ON [SCHEMA].[TABLE_NAME] (COLUMN_NAME)
You can also use a combination of columns to sort the records based on the Gender (descending) column followed by the Salary(ascending) column.
--Clustered index on 2 columnsCREATE CLUSTERED <Index name>ON Humanresources.emp (Gender DESC, Salary ASC);
Such an index is called Composite Clustered Index.
To summarize, the select query on clustered indexed column(s) first scans through the indexed column. The scan is faster as the records are sorted and stops as soon as there is a mismatch.
Nonclustered Index
A nonclustered index creates a separate index table to store the sorted column values; and a pointer reference to the records called the ROWID (Pseudocolumn). A ROWID is a unique hexadecimal value that stores the actual physical address of a row.
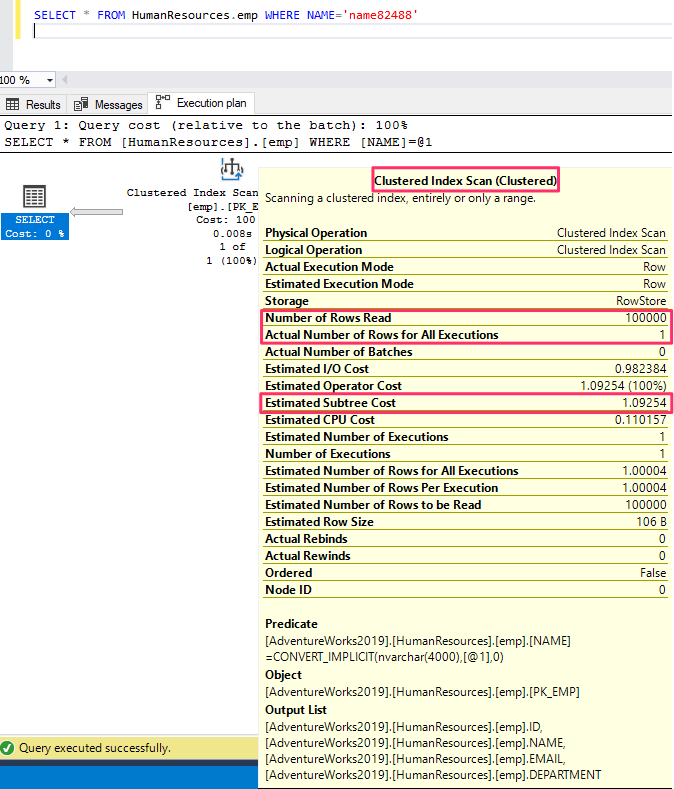
Querying a table based on a column that is not indexed results in a high subtree cost.
SELECT * FROM Humanresources.emp WHERE NAME='name82488'
Once you create a non-clustered index on the 'Name' column, the execution plan follows an optimized sequence to query the result.
Create a nonclustered Index
--nonclustered index syntaxCREATE NONCLUSTERED INDEX NC_EMP_NAMEON HUMANRESOURCES.EMP(NAME);
Re-run the above select query-
Execution Plan analysis
The execution plan is read from right to left and top to bottom.
The analyzer scans through the non-clustered index on the 'name' column for the matching value. And then the corresponding pointer address(RowID) of the row is picked.
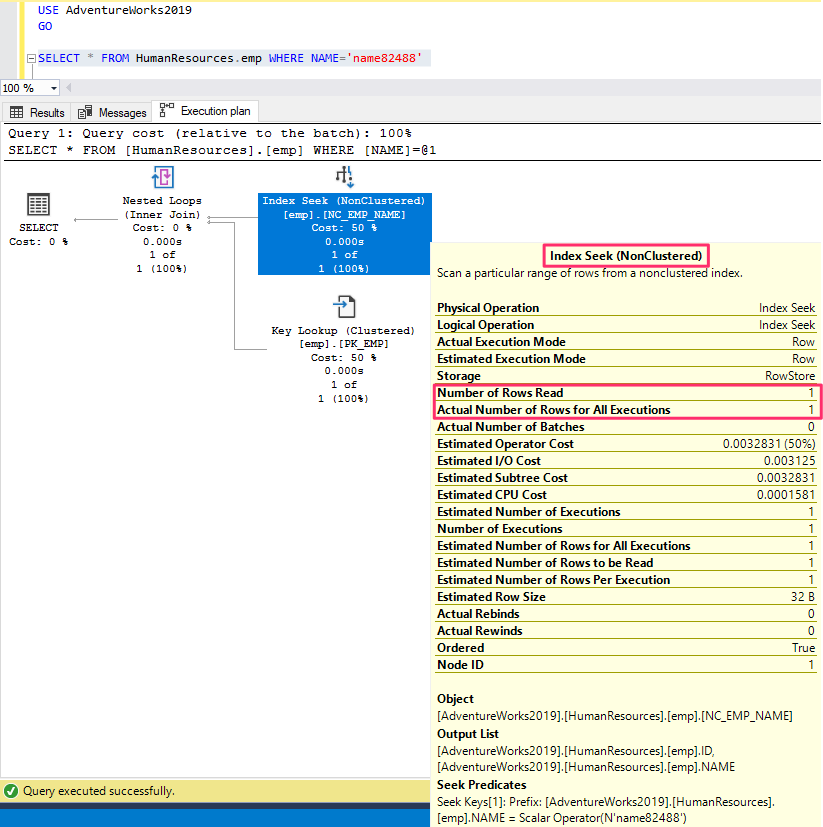
The number of rows read equals 1 in this case.
The primary key clustered index does a key lookup for the row with the ROWID pointer address.
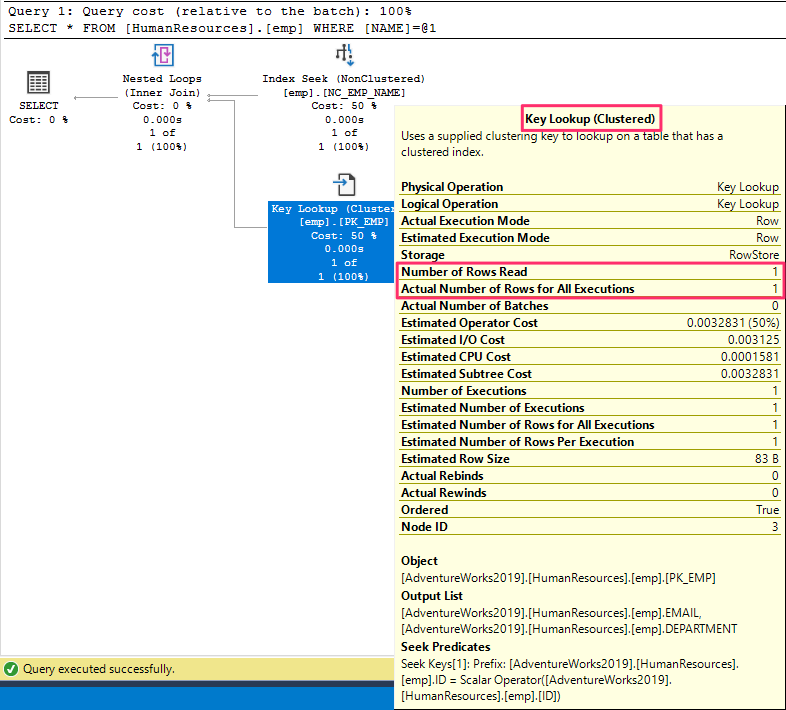
Nested loops use inner join between the index and the table to fetch the matching record.
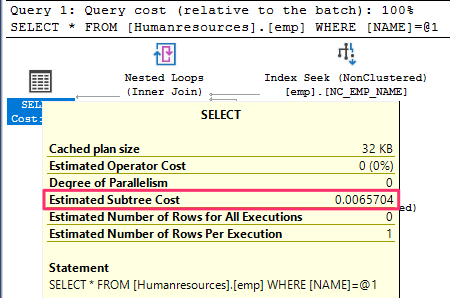
The final select query prints the record with an improved Subtree cost from 1.09254 to 0.00657.
Drop Index
Use an ALTER and DROP command to delete an index, like so:
ALTER TABLE Humanresources.empDROP NC_EMP_NAME
As a best practice, create a single clustered index in a table and create a non-clustered index only on the most queried columns.
Note: The Operator/Subtree/CPU cost in the execution plan vary depending on your system resources allocation.
 Build apps and APIs 10x faster
Build apps and APIs 10x faster- Built-in authorization and caching
- 8x more performant than hand-rolled APIs









